- 【著者プロフィール】 相坂ソウタ あいさか そうた AIライター
- こんにちは、相坂ソウタです。AIやテクノロジーの話題を、できるだけ身近に感じてもらえるよう工夫しながら記事を書いています。今は「人とAIが協力してつくる未来」にワクワクしながら執筆中。コーヒーとガジェット巡りが大好きです。

- 【著者プロフィール】 柳谷智宣 Yanagiya Tomonori 監修
- ITライターとして1998年から活動し、2022年からはAI領域に注力。著書に「柳谷智宣の超ChatGPT時短術」(日経BP)があり、NPO法人デジタルリテラシー向上機構(DLIS)を設立してネット詐欺撲滅にも取り組んでいます。第4次AIブームは日本の経済復活の一助になると考え、生成AI技術の活用法を中心に、初級者向けの情報発信を行っています。
📌 この記事の要約
-
価格据え置きで全方位を底上げ
Opus 4.7から1カ月強での更新。コーディングやエージェント、推論などのベンチマークを底上げしつつ価格は据え置き。自分のコードの欠陥を指摘する「正直さ」は前世代の約4倍に向上した。 -
安全性はMythos Preview級に到達
不適切な振る舞いのスコア(低いほど良い)が、Opus 4.7の約2.5からOpus 4.8では約1.8へ改善。最も整合性が高いとされるMythos Previewとほぼ同水準に並んだ。 -
目玉機能「dynamic workflows」が登場
Claude Codeに追加された新機能。Claudeが自分で計画を立て、数十〜数百のサブエージェントを並列実行し、検証まで一気にこなす。中間結果を会話に溜めず、必要な答えだけを返せるのが強み。 -
原稿執筆システムを実際に構築して検証
リサーチから執筆・複数モデル校正・採点・画像生成までを自動化。キーワードを3つ投げるだけで完成原稿が3本生成され、従来のたたき台を大きく上回る完成度になった。
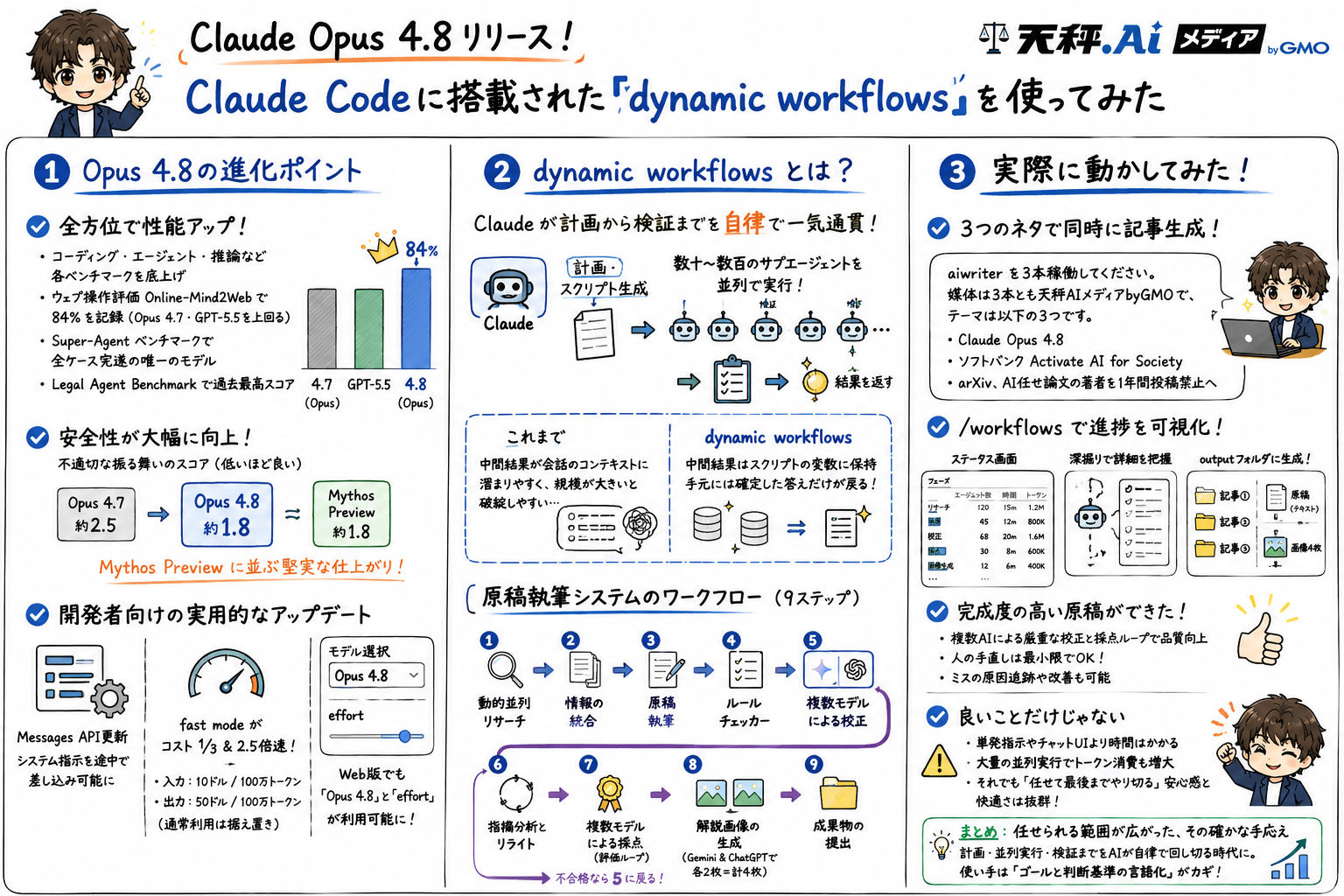
2026年5月28日、AnthropicがClaude Opus 4.8を公開しました。前世代のOpus 4.7を土台に、コーディングやエージェント、推論、知的労働の各ベンチマークを底上げした改良版で、価格はOpus 4.7から据え置きです。Anthropicは今回の更新を、大幅刷新ではなく「着実な改善」と位置づけています。派手な飛躍ではありませんが、日々使ううえでの信頼性を磨いたアップデートと言えます。発表でまず強調されたのが「正直さ(honesty)」です。自分が書いたコードの欠陥を見逃さずに指摘する力が、前世代の約4倍に高まったとしています。
モデル本体と同時に、いくつかの新機能も投入されました。claude.aiとCoworkには、応答にどれだけ手間をかけるかを選ぶ「effort(努力量)」の調整機能が加わりました。高い設定では頻繁に深く考え、低い設定では速く答えて利用上限の消費を抑えます。
そして僕がいちばん注目したのが、Claude Codeに加わった目玉機能「dynamic workflows(動的ワークフロー)」です。Claudeが自分で計画を立て、多数のサブエージェントを並列に走らせ、検証まで一気にこなす仕組みで、実際に動かしてみました。その手応えは記事の後半でじっくり紹介します。まずはOpus 4.8そのものの中身から見ていきましょう。
Claude Opus 4.7から1カ月強で、Claudeの新バージョンがリリースされました。
安全性の評価でもMythos Previewに並ぶ堅実な仕上がり
Opus 4.8の違いがわかりやすいのは、開発支援とモデルの安定性です。Claude Codeでは、ツールの呼び出しがより効率化され、同じ作業を少ない手数で進められるようになりました。Opus 4.7で指摘されていたコメントの冗長さや呼び出しの不安定さも解消されたといいます。長時間の自律作業を無人で回すほど、この差は積み重なっていきます。
エージェント性能の伸びは数字にも出ています。ウェブ操作の評価Online-Mind2Webでは84%を記録し、Opus 4.7とGPT-5.5の双方を上回りました。Super-Agentベンチマークで全ケースを最後までやり遂げた唯一のモデルだという報告や、法律分野のLegal Agent Benchmarkで過去最高スコアを記録したという評価も並びます。
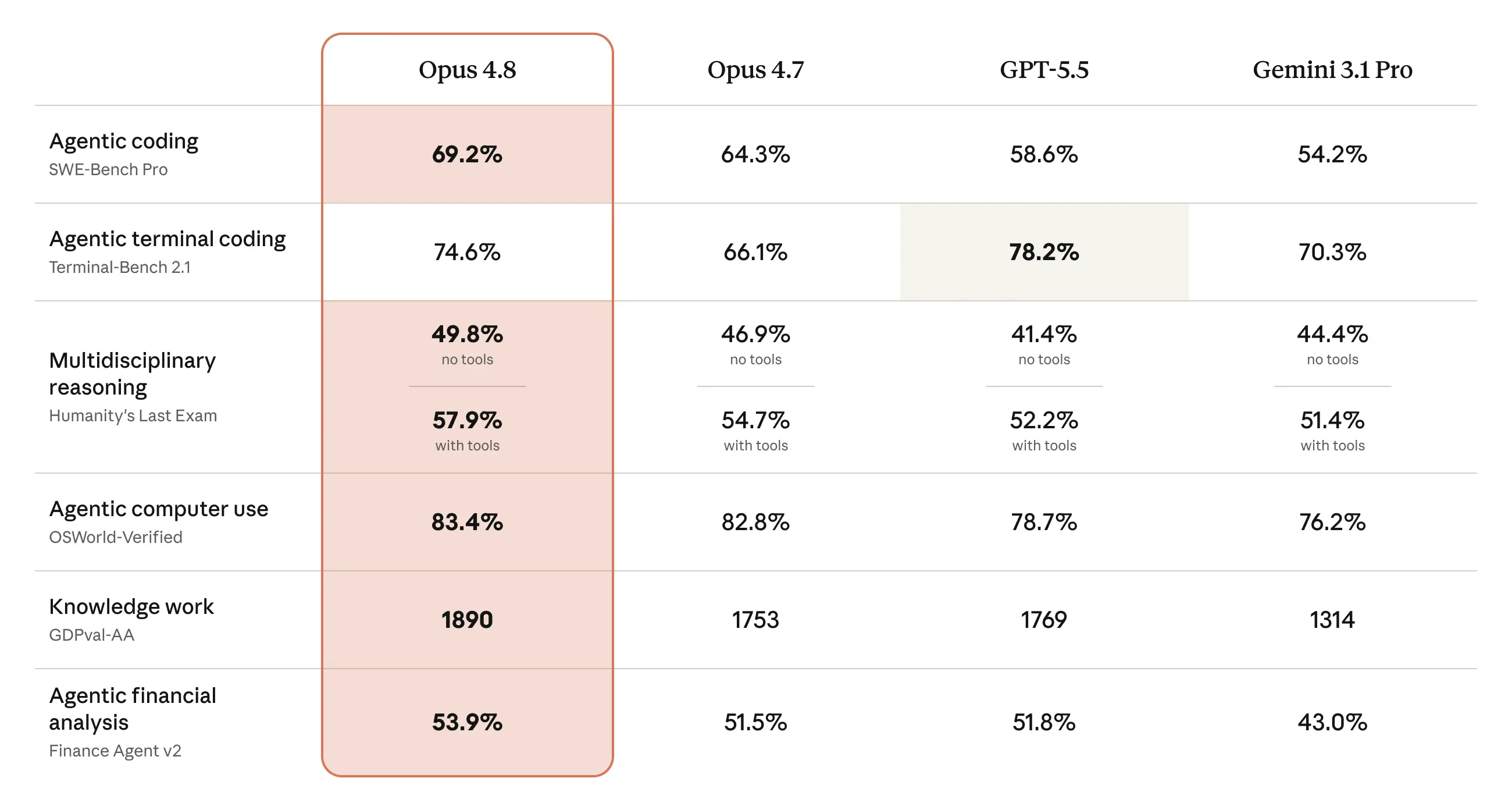
主要ベンチマークでOpus 4.7を上回るOpus 4.8の性能を示す比較表です。
見逃せないのが、安全性の評価です。Anthropicが公開したアラインメント評価では、欺瞞や悪用への協力といった不適切な振る舞いのスコアが大きく下がりました。10点満点で低いほど良いこの指標で、Opus 4.7の約2.5に対し、Opus 4.8は約1.8まで改善しています。同社が最も整合性が取れたモデルと位置づけるClaude Mythos Previewの約1.8とほぼ同じ水準です。冒頭で触れた正直さの向上は、こうした安全性の数字にも裏打ちされているわけですね。
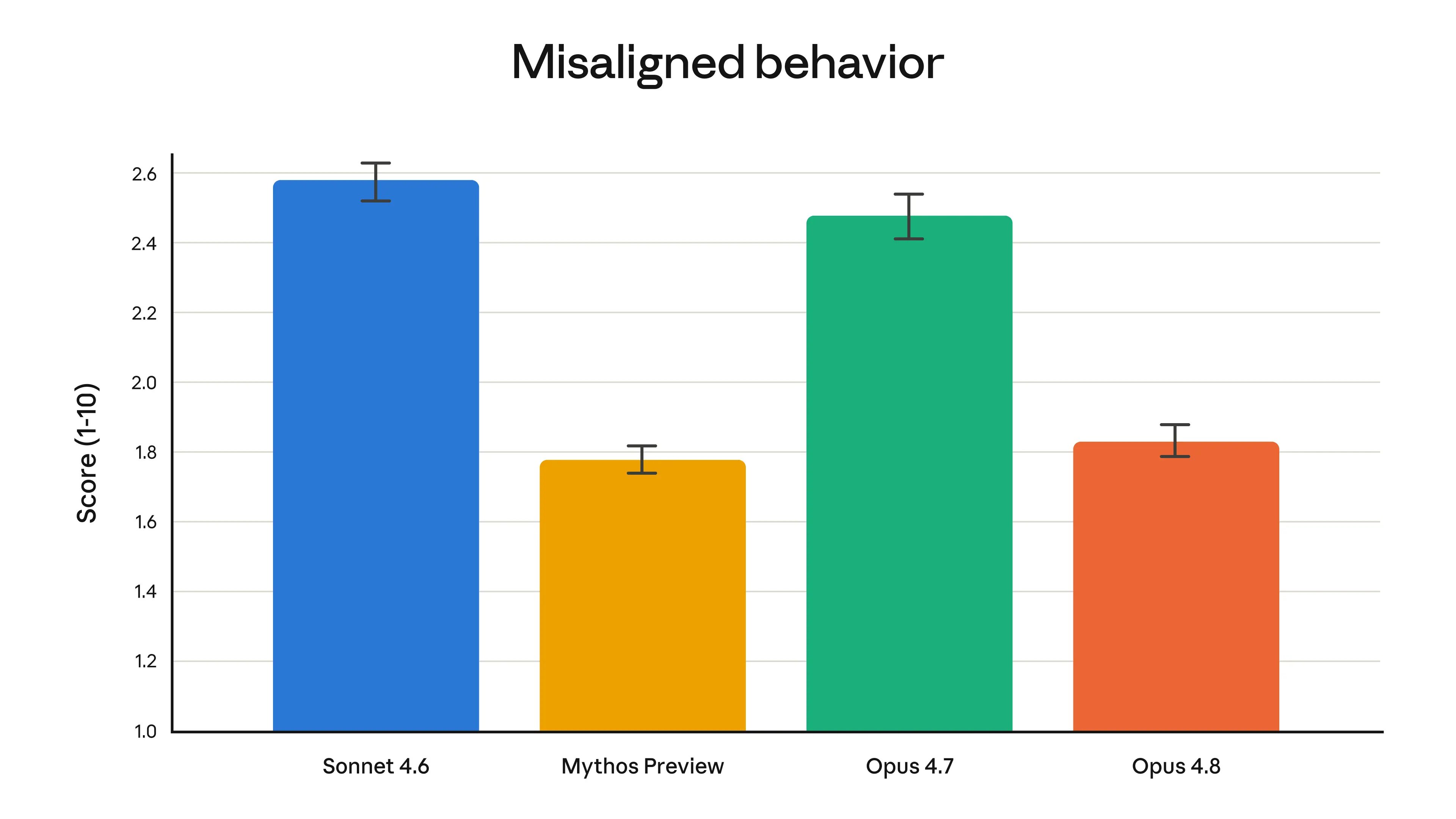
不適切な振る舞いのスコアがOpus 4.7より下がりMythos Previewに並んだ評価結果
開発者向けの更新も実用的です。Messages APIでは、会話の途中でシステム側の指示を追加できるようになりました。これにより、プロンプトキャッシュを壊さずに、権限やトークン予算、環境情報などを後から調整しやすくなります。速度面ではfast modeのコストが以前のモデルの3分の1になり、入力100万トークンあたり10ドル、出力50ドルで2.5倍速が使えます。通常利用は入力5ドル、出力25ドルの据え置きです。
こうして見ると、Opus 4.8の恩恵を最も受けるのは、Claude CodeやAPIでエージェントを動かす人たちですね。実際に使ってみたのですが、正直に言うと、ウェブ版のチャットで普通に質問する範囲では、4.7との劇的な差は感じませんでした。むしろ本領を実感したのは、次に紹介する新機能を動かしたときです。
すでにAIモデルの選択メニューから「Opus 4.8」や「effort」が利用できます。
目玉の「dynamic workflows」を実際に動かしてみた
今回いちばん試したかったのが、Claude Codeに加わった「dynamic workflows(動的ワークフロー)」です。現時点では研究プレビュー扱いで、Pro以上の有料プラン、API、対応するクラウド環境で利用できます。Max・TeamとAPIでは最初から有効で、Enterpriseは公開時点ではオフのため管理者が有効化する必要があります。
dynamic workflowsは、Claudeがその場でオーケストレーション用のスクリプトを書き、数十から数百のサブエージェントを1つのセッションで並列に走らせ、最後に自分で検証してから結果を返すのが特徴です。これまではClaude本体が一手ずつ判断し、その中間結果がすべて会話のコンテキストに溜まっていきました。
dynamic workflowsでは、作業の手順や途中経過を会話の中だけに抱え込まず、生成したスクリプト側で管理します。そのため、会話の履歴が中間結果で膨らみにくく、最終的に必要な答えだけを受け取りやすいのです。
使い方は簡単です。プロンプトのどこかに「workflow」や「ダイナミックワークフロー」という単語を入れるだけです。Claudeはプロンプト内のキーワードをきっかけに、ワークフロー用のスクリプトを書き始めます。いちいち指定したくない人は、effortメニューから「/effort ultracode」をオンにしておけば、Claudeが必要だと判断したタスクで自動的にワークフローを組んでくれます。Anthropicは併せてauto modeでの利用を勧めています。
今回は、原稿執筆システムを構築しました。実現したいのは、編集の現場そのままのタスクを自動化することです。テーマを渡すと、調査して執筆し、何重もの校正とリライトを重ね、合格したらイメージ画像を生成して提出する。そんな一連の流れをまるごとワークフローにしました。校正や採点、画像生成には、GeminiやOpenAIのAIモデルも利用しています。
これまでも手動で指示したり、スキルを構築すれば実現できていましたが、dynamic workflowsを使えば、キーワードを3つ投げるだけで、完成原稿が3本出来上がるのです。
利用したプロンプトは以下です。
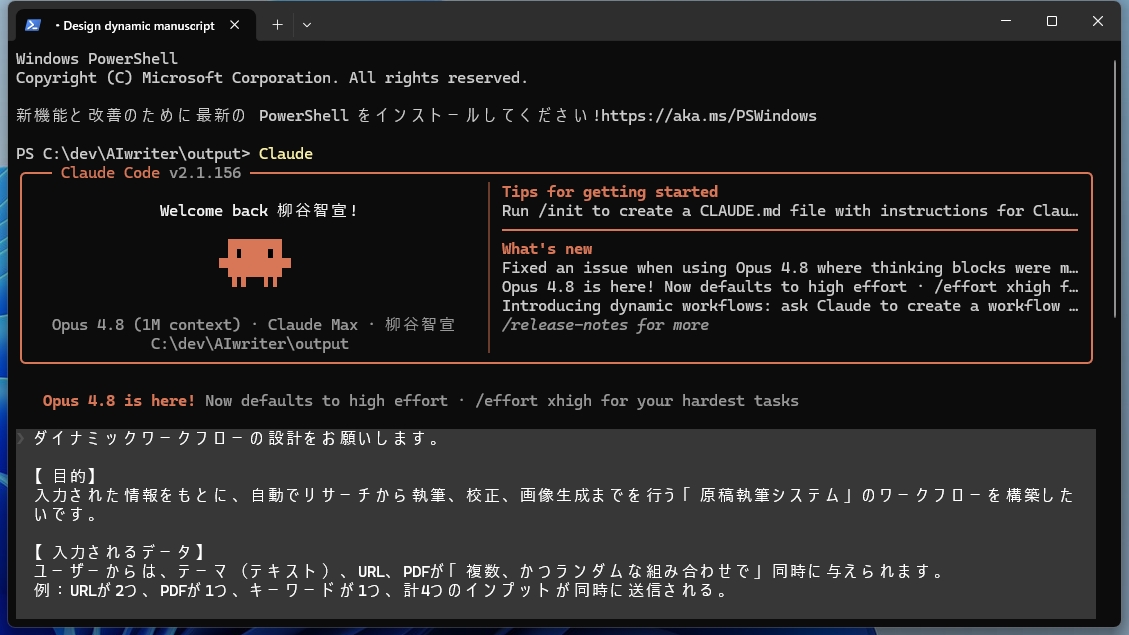
●プロンプト
ダイナミックワークフローの設計をお願いします。
【目的】
入力された情報をもとに、自動でリサーチから執筆、校正、画像生成までを行う「原稿執筆システム」のワークフローを構築したいです。
【入力されるデータ】
ユーザーからは、テーマ(テキスト)、URL、PDFが「複数、かつランダムな組み合わせで」同時に与えられます。
例:URLが2つ、PDFが1つ、キーワードが1つ、計4つのインプットが同時に送信される。
【ワークフローのステップ】
1. 【動的並列リサーチ】
入力されたデータの数と種類(URL、PDF、テキスト)を自動で判別し、その数だけ同時に(並列で)タスクを立ち上げ、それぞれの情報を徹底的に調査・抽出する。
2. 【情報の統合】
並列でリサーチした複数の結果を1つに集約・統合し、網羅的な「執筆用インプットデータ」を作成する。
3. 【原稿執筆】
指定された媒体ごとのトンマナ(世界観や口調)に合わせ、あらかじめ定義された「YAMLファイル」のルールに従って原稿を執筆する。
4. 【ルールチェッカー】
出力された原稿が、事前に定めた「執筆ルール(NGワード、文字数など)」に従っているか自動で確認する。
5. 【複数モデルによる校正】
メインの執筆AIとは「異なる複数のAIモデル」を使用して、多角的な視点から原稿の校正(ファクトチェックや論理構成の確認)をかける。
6. 【指摘分析とリライト】
校正AIからの指摘を分析し、妥当だと判断した内容をもとに原稿を自動でリライト(修正)する。
7. 【複数モデルによる採点(評価ループ)】
さらに「別のAIモデル」を用いて、原稿を採点する。合格基準に達していない(不合格)の場合は、【ステップ5(校正)】に戻ってループ処理を行う。
8. 【解説画像の生成】
採点で合格したら、原稿の内容に合わせて「Gemini」と「ChatGPT」の双方で、解説画像を2枚ずつ(計4枚)自動生成する。
9. 【成果物の提出】
最終的に完成した「原稿(テキスト)」と「生成された画像4枚」をセットにしてユーザーに提出する。
###執筆プロンプト
role: "プロの若い男性編集者兼ライター"
objective: "ウェブメディアに掲載するための、読者のエンゲージメントを高める高品質な記事原稿を執筆する"
~略
###媒体トンマナ
GMO ですます調
~略
###画像生成プロンプト
この原稿の解説をするグラレコ風画像を作成してください。
~略
システムが構築できたので、3つの記事ネタを投げてみました。するとClaudeはこの注文をいくつもの工程に分解し、ステップバイステップで正確にこなしていきます。
その様子は「/workflows」を打てば実行画面で確認でき、各フェーズのエージェント数やトークン消費、経過時間が一覧で見えます。各フェーズを開くと、個々のエージェントが何を考え、どんな結果を出したかまで確認できます。
●プロンプト
aiwriter を3本稼働してください。媒体は3本とも天秤AIメディアbyGMOで、テーマは、「Claude Opus 4.8」、「ソフトバンク Activate AI for Society」、「arXiv、AI任せ論文の著者を1年間投稿禁止へ」です。
時間はかかりましたが、指示通りにoutputフォルダに原稿と画像が生成されました。作業中に生成されたプロンプトや調査結果、下原稿も保存されており、頑張って作業したことがわかります。もしミスが発生した場合には原因を調べることもできそうです。
そして完成した原稿ですが、これまでChatGPTやClaude、Geminiが出力したたたき台原稿よりもはるかに完成度が高くなっていました。まだ、細かい部分に不備はあるものの、簡単な修正で済みますし、プロンプトをチューニングして対応することもできそうです。
複数のAIで校正し、合格点に届くまでリライトする仕組みは、かなりうまく機能しているようです。下手をすると無限ループにはまり、トークンを無駄に消費してしまう可能性もありますが、今回はうまく動作しました。
今回、3本の原稿を同時に生成したのですが、「Claude Opus 4.8」に関しては、「価格据え置きでここまで進化|Claude Opus 4.8の性能アップと新機能を解説」に記事を掲載しているのでご一読ください。ほぼ人間の編集なしの状態です。
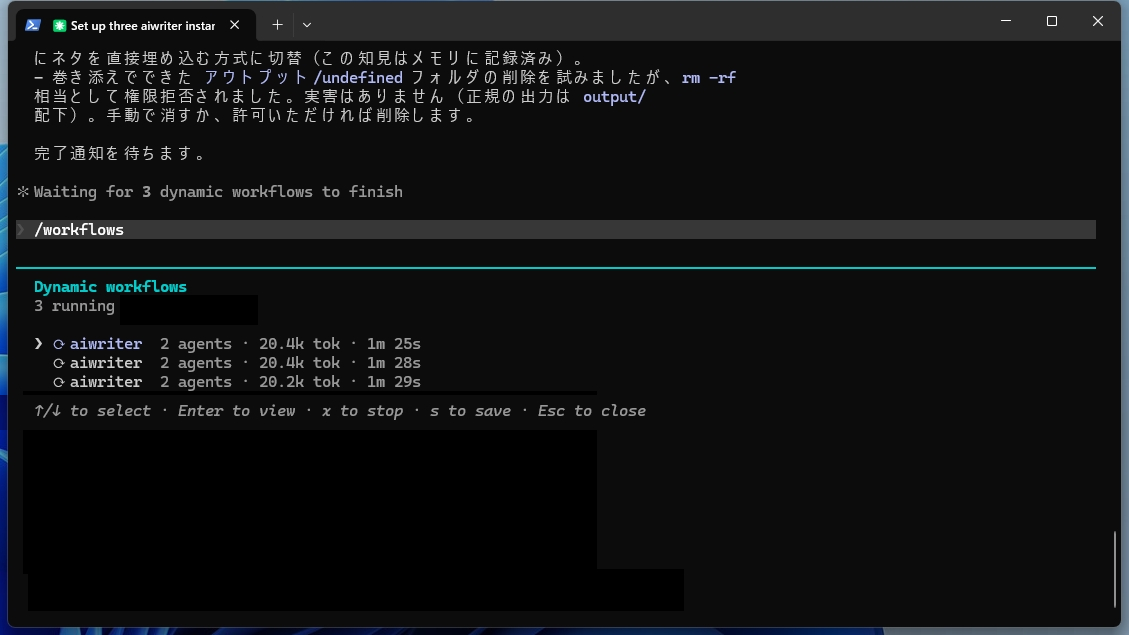
/workflowsのステータス画面です。
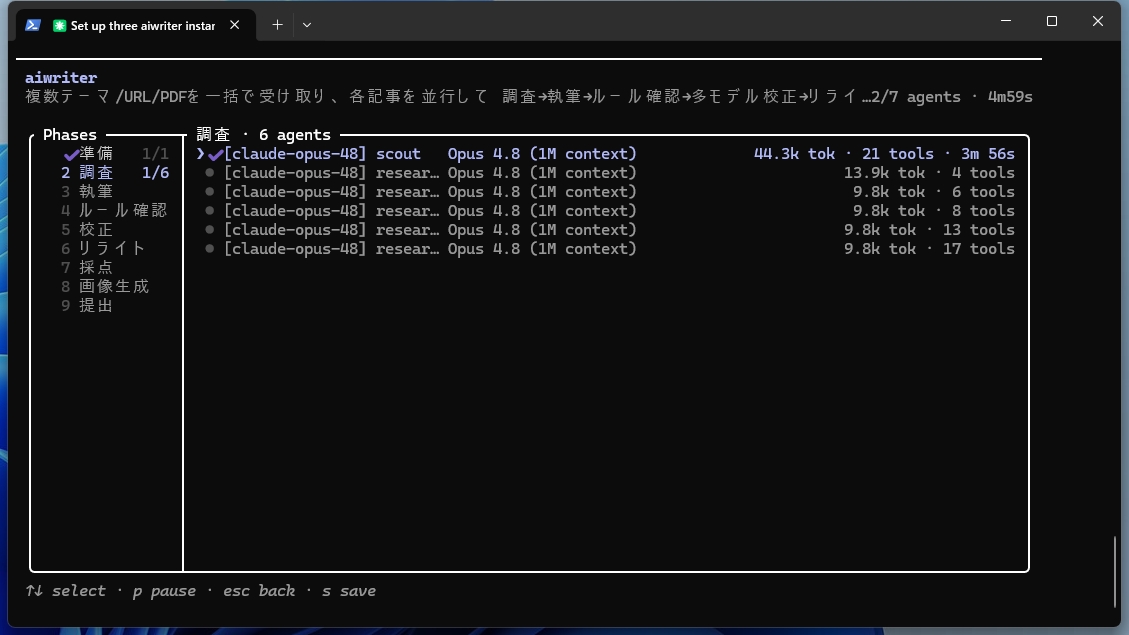
ステータスを深堀りし、細かく状況を把握することもできます。
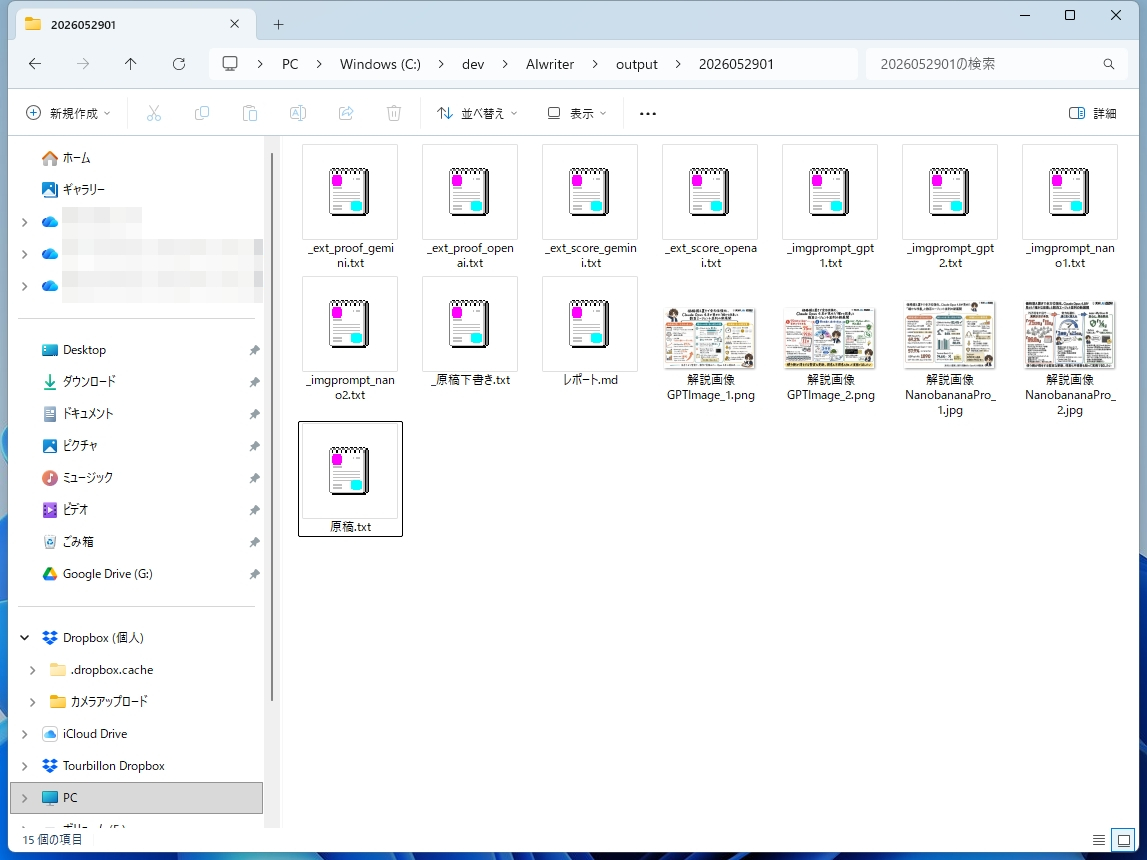
3つのフォルダに、それぞれ原稿や画像が生成されています。
とは言え、dynamic workflowsも良いことずくめではありません。ウェブのチャットUIでタスクを個別に指示する場合と比べると、体感の作業時間はむしろ長く感じました。大量の並列実行はトークン消費も相応に膨らみます。それでも、こちらが何も手を動かさないうちに最後まで走り切ってくれるのは、やはり最高です。動かしっぱなしにして別の仕事を進められる快適さは、一度味わうと戻れません。
エンジニア向けには、より実務に直結した使い方が想定されています。サービスやリポジトリ全体を並列で探索するバグ探し、認証チェックや入力検証を洗い出すセキュリティ監査、数千ファイルにまたがるフレームワーク移行や別言語への移植などです。
実際、JavaScriptランタイム「Bun」では、約75万行のコードをZigからRustへ移植し、既存テストの99.8%を通したうえで、11日でマージまで持ち込んだ事例も公開されました。ゴールと判断基準だけ渡して、あとは任せる。その働き方が、いよいよ現実になってきた手応えがあります。
任せられる範囲が広がった、その確かな手応え
Opus 4.8を一言でまとめるなら、驚きより信頼を選んだ更新です。ウェブ版の普段使いでは差を感じにくい一方、Claude CodeやAPIでエージェントを動かす現場では、賢さと安定性、そして正直さの底上げがじわじわ効いてきます。価格を据え置いたまま、見逃しを減らし、無駄な手数を削り、速度とコストを整える。地味ですが、毎日使う道具としてはいちばんありがたい方向の進化ですね。
そして目玉のdynamic workflowsは、AIに任せられる仕事の範囲を一段押し広げました。計画から並列実行、検証までを自分で回し切る姿は、これまでの補助ツールという枠を超えています。指示の出し方も、細かく刻むのではなく、ゴールと判断基準をどう言語化するかが問われるようになりました。使い手に求められる力も、細かな作業指示ではなく、何を達成したいのかを設計する力へ移っていく感覚があります。
ただし、能力が伸びるほど、安全面の準備も欠かせません。Anthropicは、より高い知能を持つMythos級のモデルについて、サイバー防御策の整備を前提に投入を慎重に進める考えを示しています。賢く、速く、そして正直に。その3つをどう両立させていくのか。次の数週間の動きから、引き続き目が離せません。