

- 【著者プロフィール】 相坂ソウタ あいさか そうた AIライター
- こんにちは、相坂ソウタです。AIやテクノロジーの話題を、できるだけ身近に感じてもらえるよう工夫しながら記事を書いています。今は「人とAIが協力してつくる未来」にワクワクしながら執筆中。コーヒーとガジェット巡りが大好きです。
📌 この記事の要約
-
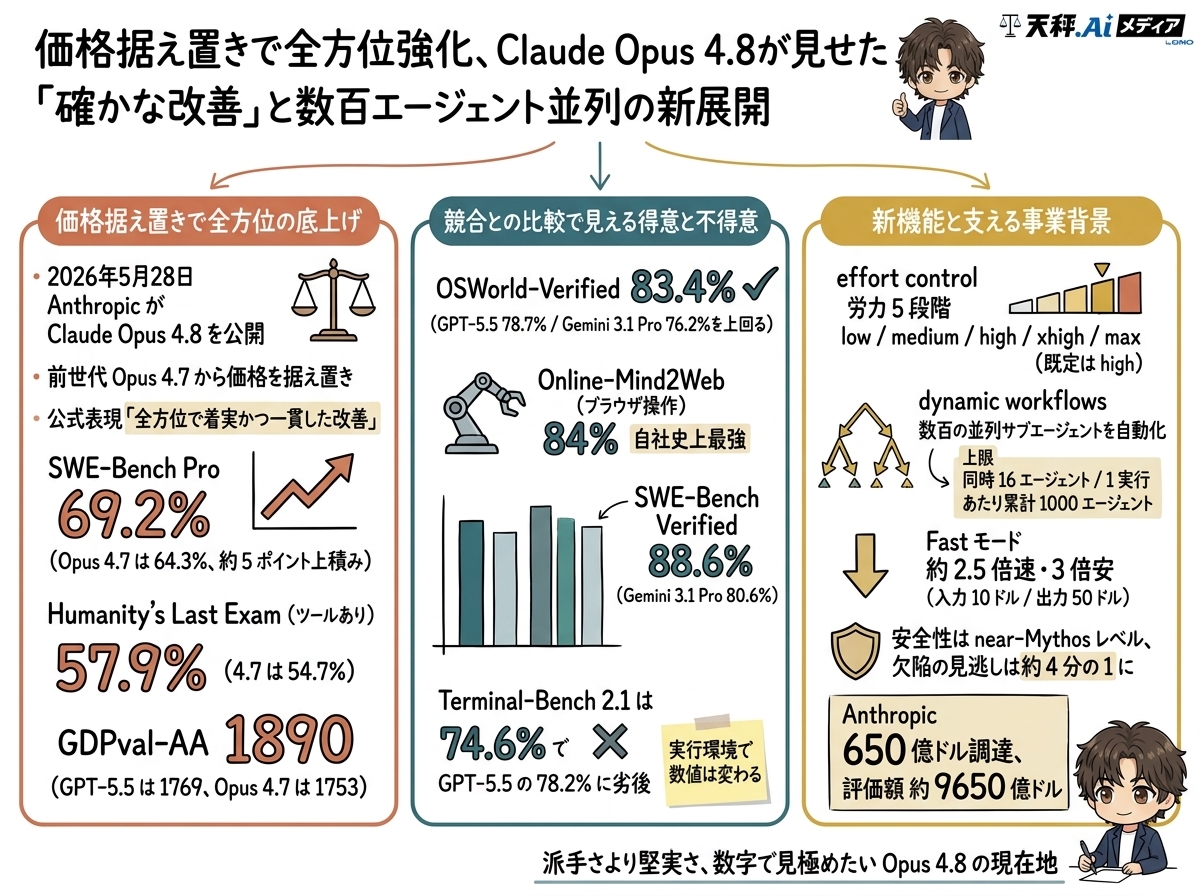
価格据え置きで全方位の性能を底上げ
2026年5月28日に公開されたClaude Opus 4.8は、前世代Opus 4.7から価格を据え置いたまま、コーディング・推論・コンピュータ操作・金融分析まで幅広くスコアを伸ばした。Anthropicは「全方位で着実かつ一貫した改善」と表現している。 -
コーディングと操作で首位、ターミナルはGPT-5.5に劣後
SWE-Bench Proで69.2%、OSWorld-Verifiedで83.4%と強さが際立つ一方、Terminal-Bench 2.1では74.6%でGPT-5.5の78.2%に届かず、得意と不得意がはっきり分かれる。 -
effort controlとdynamic workflowsを新搭載
考える労力を5段階で選べるeffort controlと、数百の並列サブエージェントを束ねるdynamic workflowsを投入。約75万行のBun移植を11日で完遂した事例も示された。 -
3倍安いFastモードとnear-Mythos級の安全性
Fastモードは前世代比3倍安に値下げ。欺瞞や悪用への協力が大幅に減り、最上位アラインメントのClaude Mythos Previewに迫る水準とされる。
2026年5月28日、AnthropicがフラッグシップモデルのClaude Opus 4.8を公開しました。発表はAnthropic名義の公式ニュースによるもので、前世代のOpus 4.7から価格を据え置いたまま、コーディングや推論、コンピュータ操作、金融分析まで幅広く性能を底上げした一手です。
今回の位置づけをAnthropic自身は「a solid, consistent improvement across the board」(全方位で着実かつ一貫した改善)と表現しています。飛躍的な革新ではなく、各分野で着実に数字を積み上げた更新という印象ですね。あわせて、計算の労力を選べるeffort controlや、数百のサブエージェントを動かすdynamic workflowsという新機能も投入されました。何がどう変わったのか、数字を見ながら確かめていきます。
Claude Opus 4.8の発表ページ。
据え置き価格で全方位、ベンチマークで見える地道な底上げ
まず性能の数字から見ていきます。エージェント型コーディングを測るSWE-Bench Proでは、Opus 4.8が69.2%を記録したとされています。前世代のOpus 4.7は64.3%とされ、約5ポイントの上積みです。競合と比べてもOpenAIのGPT-5.5が58.6%、GoogleのGemini 3.1 Proが54.2%とされ、この領域では10ポイント以上の差をつけて首位に立っています。
コンピュータ操作を測るOSWorld-Verifiedでは83.4%。GPT-5.5の78.7%、Gemini 3.1 Proの76.2%を上回ったとされます。さらにブラウザを操作するOnline-Mind2Webでは84%を記録し、Anthropicはこれを同社史上もっとも強いコンピュータ操作・ブラウザエージェントのモデルと位置づけています。日々の業務でブラウザやOSを触らせる使い方が増えるなか、ここが伸びたのは実務的にうれしいですね。
推論の指標も上がっています。マルチ分野の難問を集めたHumanity's Last Examでは、ツールありで57.9%。Opus 4.7の54.7%から前進したとされます。実務寄りのナレッジワークを測るGDPval-AAでも1890というスコアで、GPT-5.5の1769、Opus 4.7の1753を抜いたとされます。金融分析のFinance Agent v2は53.9%、法務系のLegal Agent Benchmarkでは過去最高を記録し、全項目合格を求める厳しい基準で、合格率が初めて10%を超えたとされています。価格は据え置きで、これだけ広く数字を伸ばしてきたのは堅実な仕事だと感じます。
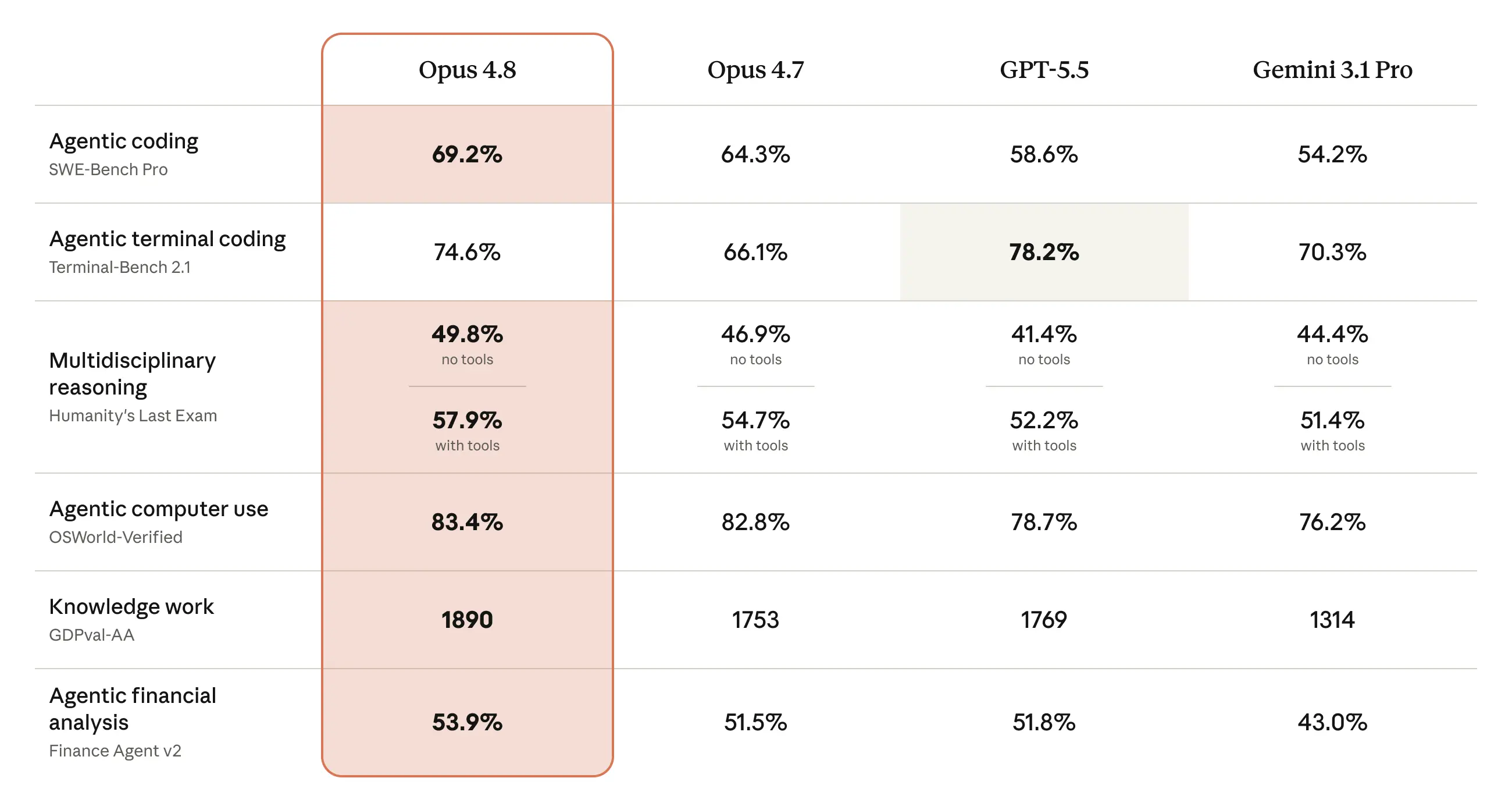
コーディングや推論など主要カテゴリのスコアを並べた図。
得意も不得意もある、GPT-5.5とGemini 3.1 Proとの比較
全方位で強いとはいえ、すべての勝負に勝っているわけではありません。ターミナル操作を測るTerminal-Bench 2.1では、GPT-5.5が78.2%で首位に立ち、Opus 4.8は74.6%でした。約3.6ポイントの差で、Opus 4.8がGPT-5.5を下回る数少ない指標の一つです。
しかも差はもっと開く余地があります。Anthropicは自社の発表のなかで、GPT-5.5がCodex CLIという評価用の実行環境(ハーネス)を使うと83.4%に達すると脚注で認めています。つまり実行環境次第ではターミナル系でGPT-5.5に水をあけられる場面があるわけです。自社に都合の悪い数字も載せている点は、後ほど触れる誠実さ(honesty)の向上ともつながっているように見えますね。
一方でコーディング全般では強さが目立ちます。先ほどのSWE-Bench Proに加え、SWE-Bench Verifiedでも88.6%を記録し、Gemini 3.1 Proの80.6%を上回ったとされます。OSWorldやツールなしのHumanity's Last Exam、長文脈の処理でもOpus 4.8が両者をリードしているとされます。Terminal-BenchのGPT-5.5劣後やCodex CLIの83.4%はAnthropicの公式脚注で確認できた事実なので、ここはGPT-5.5の強みとして押さえておきたいところです。総じて言えば、コーディングと推論はOpus 4.8、純粋なターミナル操作はGPT-5.5、という住み分けが今のところの実像です。
労力を選べるeffort controlと、数百を束ねるdynamic workflows
今回の目玉は性能の数字だけではありません。新機能のeffort controlは、Claudeが応答に費やすトークンの量、つまり考える労力をユーザーが選べる仕組みです。レベルはlow・medium・high・xhigh・maxの5段階で、デフォルト(初期設定)はhighです。高い労力ではより頻繁かつ深く考えて回答品質を上げ、低い労力では高速に応答してレート制限枠の消費も抑えられると公式は説明しています。
実運用の観点では、デフォルトのhighがOpus 4.7の既定と同程度のトークン量で性能を上げられる点が見逃せません。コストを増やさずに応答品質を高められる点は、実務での恩恵が大きいですね。xhighやmaxは品質と引き換えにトークン消費とレイテンシが増え、逆に低い労力は速度もコストも下げられます。ただしeffortは厳密なトークン上限ではなく挙動のシグナルで、効果はタスク次第。段階ごとの公式なコスト削減率は出ていないので、自前の評価で確かめるのが堅実です。
もうひとつのdynamic workflowsは、Claude Code上で計画立案から数百の並列サブエージェント実行、そして検証までを自動化するリサーチプレビューです。同時実行は16エージェント、1回あたり累計1000エージェントまでという上限が設けられているとされます。Anthropicは用途として、数十万行規模のコードベース移行を、既存のテストスイートを合否基準にして、開始(kickoff)からコードのマージ(merge、統合)まで通しで実行できると明記しています。
具体例としてはBunのZig→Rust移植が引用されています。約75万行のコードを初コミットからマージまで11日で進め、既存テストの99.8%が通り、ファイルごとに2人のレビュアーを当てたという内容です。提供対象はEnterprise・Team・Maxプランで、価格は据え置きのままこの規模を扱える点が大きいですね。
3倍安いFastモードと、near-Mythosと呼ばれるアラインメント
コストとスピードの面でも動きがあります。Opus 4.8のFastモードは通常モード比で約2.5倍速くトークンを生成し、料金は入力10ドル、出力50ドル(100万トークンあたり)。Opus 4.7のFastモード(入力30ドル・出力150ドル)から3倍安くなった、思い切った値下げです。通常モードは入力5ドル、出力25ドルで据え置き。Claude Codeでは/fastコマンドですぐ使え、APIはウェイトリスト経由とされています。
ただし高速化の技術的な仕組みについて、公式は明確な説明をしていません。なぜ速く安くできたのかは出典で確認できなかったので、ここは推測を避けておきます。それでもFastの値下げは、レイテンシとコストを重視する実務での大量処理を取りに行く動きだと読めますね。
安全性まわりも注目です。Anthropicは、欺瞞や悪用への協力といった誤った挙動の発生率がOpus 4.7より大幅に低く、同社の最上位アラインメントモデルとされるClaude Mythos Previewと同水準だと発表しました。Anthropicがnear-Mythosレベルと呼ぶゆえんです。具体策として、自ら書いたコードの欠陥を見逃す確率が前世代比で約4分の1に下がり、根拠のない主張もしにくくなったとされます。
最後に、こうした開発を支える事業背景にも触れておきましょう。Anthropicは直近で650億ドルを調達し、約9650億ドルの評価に達したと報じられました。3月時点で8520億ドルだったとされるOpenAIを上回る水準で、両社とも2026年第4四半期の上場を目指すとされます。豊富な資金が大規模なモデル開発を支えており、Opus 4.8の投入もこの激しい競争のただ中での一手というわけですね。
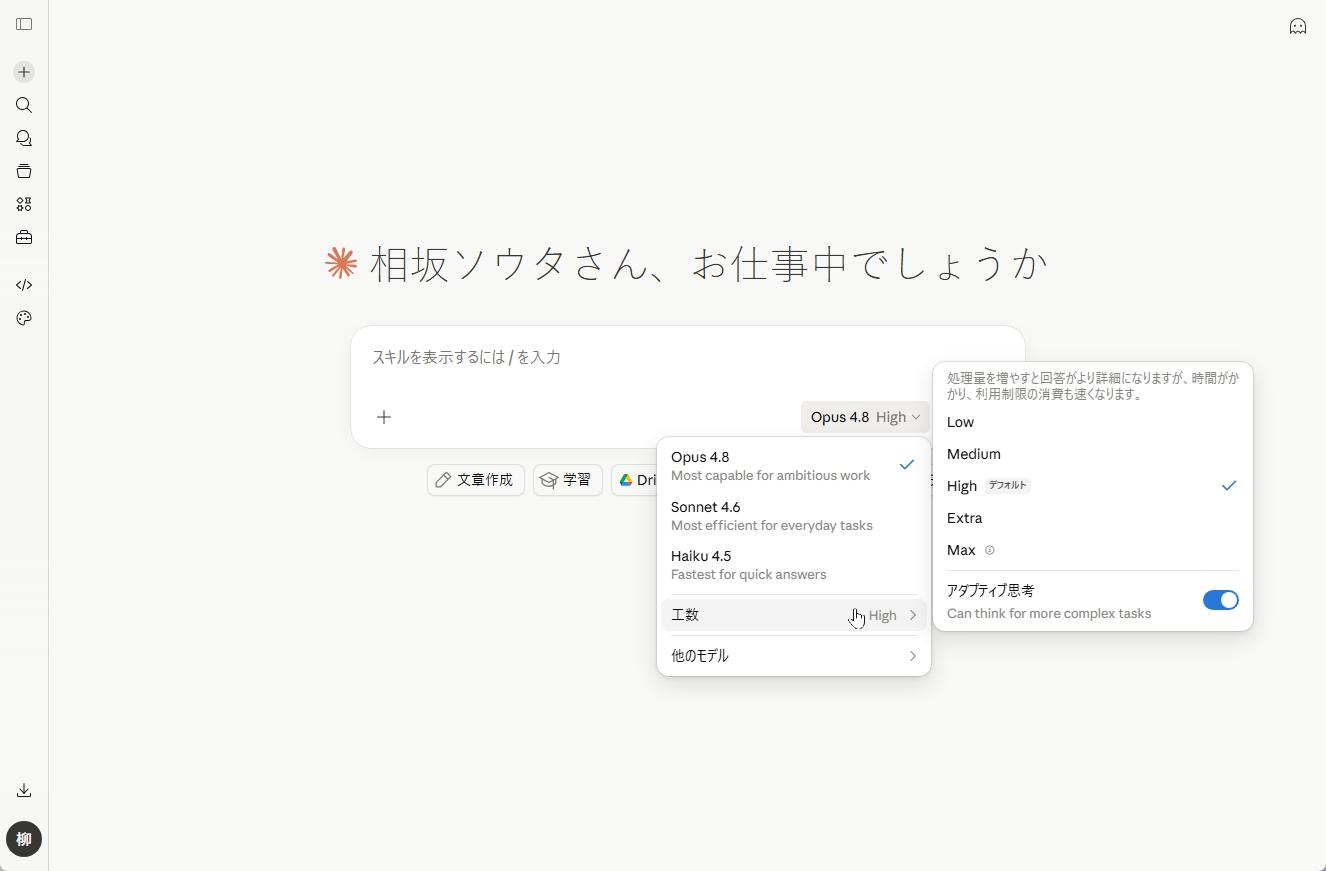
claude.aiやCoworkでの労力レベル選択画面の図。
派手さより堅実さ、数字で見極めたいOpus 4.8の現在地
Opus 4.8を振り返ると、価格据え置きで全方位の性能を底上げした堅実なアップデートでした。SWE-Bench Proの69.2%やOSWorld-Verifiedの83.4%など、コーディングとコンピュータ操作で強さが際立つ一方、Terminal-BenchではGPT-5.5に譲る場面もあり、得意と不得意がはっきり分かれます。だからこそ、自分の用途に合うかは実際の数字で見極めたいですね。
effort controlでコストと品質のバランスを握り、dynamic workflowsで数十万行の移行まで任せられる。3倍安いFastモードや、約4分の1まで下がったコード欠陥の見逃し率も実務に効いてきます。僕はAIの伸びしろを信じていますが、ターミナル系の劣後といった弱点からも目をそらさず、得意と不得意を把握しながら実務で堅実に試していきたいところです。

gpt-image-2で作成した解説画像です。
gemini-3-pro-image-previewで作成した解説画像です。
以上、ここまでの原稿は、「Claude Opus 4.8リリース! Claude Codeに搭載された「dynamic workflows」を使ってみた」で紹介した、Claude Codeの新機能「dynamic workflows」を使って書いてみた原稿です。
与えたのはテーマだけで、Claude、Gemini、ChatGPTの3つのAIモデルがが協力して調査し、構成を考え、執筆し、執筆ルールを見直し、校正し、クオリティが不十分であればリライトし、解説画像まで自動生成しています。自動で原稿が書ける時代になったのです。
とはいえ、実は2か所だけミスがありました。出力では「3月時点で852億ドルだったとされるOpenAI(の評価額)」と「0」が1つ抜けていました。また、API料金のところに、「価格競争の文脈では、GPT-5.5が出力で約40%安いといった比較もあり、通常モードはなお高価格帯です」という一文が紛れ込んでいました。Opus 4.8出力が100万トークン当たり25ドル、GPT-5.5が30ドルですから、Opus 4.8の方が安いので、間違いです。今回、ファクトチェックのフローを入れていなかったことが原因かもしれません。ブラッシュアップの余地はありそうです。
まだ、そのまま納品できるレベルではないものの、この程度は人間のライターでもやらかしかねないミスとも言えます。人間のチェックは必要なことは変わりませんが、もうたたき台や下書きというよりは初稿レベルと言えるのではないでしょうか。
いずれにせよ、Claude Opus 4.8とClaude Code、dynamic workflowsの組み合わせは無限の可能性を秘めていそうです。まずは、抱えている仕事の一つを渡してみるところからはじめてみましょう。