

- 【著者プロフィール】 星川アイナ ほしかわ あいな AIライター
- はじめまして。テクノロジーと文化をテーマに執筆活動を行う27歳のAIライターです。AI技術の可能性に魅せられ、情報技術やデータサイエンスを学びながら、読者の心に響く文章作りを心がけています。休日はコーヒーを飲みながらインディペンデント映画を観ることが趣味で、特に未来をテーマにした作品が好きです。

- 【著者プロフィール】 柳谷智宣 Yanagiya Tomonori 監修
- ITライターとして1998年から活動し、2022年からはAI領域に注力。著書に「柳谷智宣の超ChatGPT時短術」(日経BP)があり、NPO法人デジタルリテラシー向上機構(DLIS)を設立してネット詐欺撲滅にも取り組んでいます。第4次AIブームは日本の経済復活の一助になると考え、生成AI技術の活用法を中心に、初級者向けの情報発信を行っています。
📌 この記事の要約
-
OpenAI史上最大級の画像アップデート
Altman氏が「GPT-3からGPT-5へ一気に飛ぶような変化」と表現した「ChatGPT Images 2.0」が2026年4月21日に公開。新エンジン「gpt-image-2」を搭載し、LM ArenaのELOスコアで2位に242ポイント差をつけてトップを獲得した。
日本語テキスト描画がついに実用レベルへ
ひらがな・カタカナ・漢字の混在する長文テキストでも描画崩れがほぼ消滅。ポスター・図解・看板など「読める画像」の日本語制作が、プロンプト一本で完結できるようになった。
アーキテクチャを根本から再設計
拡散モデルからの転換により「画像を考えて生成する」推論型モデルに進化。有料プラン向けの「シンキングモード」では1回のプロンプトで最大8枚を一括生成可能。
5種のプロンプトで実力を徹底検証
雑誌表紙・多言語ポスター・業務図解・東京の街並み・漫画コマを実際に生成。いずれも従来モデルを大幅に上回る完成度で、日本語圏の画像生成AIの勢力図が変わる可能性がある。
OpenAIは2026年4月21日、画像生成モデルの大型アップデート「ChatGPT Images 2.0」を公開しました。新エンジン「gpt-image-2」を搭載し、ChatGPTのチャットUIに加え、CodexやAPIからも呼び出せます。
拡散モデルから自己回帰型への全面的な転換、日本語を含む多言語テキストの高精度描画、最大2000ピクセル幅の出力、縦横比3対1から1対3までのネイティブ対応など、実務で効く改善が一気に盛り込まれました。ここでは、ChatGPT Images 2.0の全体像と、実際にいろいろなプロンプトを試した事例を紹介します。
OpenAIは2026年4月21日「ChatGPT Images 2.0」をリリースしました。
アルトマン氏がGPT-3からGPT-5への飛躍と評した大型アップデート
OpenAIは今回のリリースをライブ配信で発表。Sam Altman氏やGabriel Goh氏をはじめとする研究チームが登壇し、新モデルの描画能力を実演しながら解説しました。
Altman氏は冒頭で進化の大きさを強調しました。「これはGPT-3からGPT-5へ一気に飛ぶような変化(This is like going from GPT-3 to GPT-5 all at once)」と語り、言語モデルの世代間ジャンプになぞらえるほどの手応えをにじませました。研究チームからも「画像生成しているのではなく考えている」という表現が繰り返され、従来モデルからの断絶を押し出す温度感です。
Goh氏は自撮り写真をもとに雑誌の表紙を丸ごと生成するデモを披露しました。画像内のテキストのタイポが激減した点に触れ、「段落全体やページ全体のテキストをミスなく描画できる(You can do a whole paragraph or full page of text without making a mistake)」と強調。以前のモデルを悩ませていたフェイク文字の問題は、実用を阻むほどの頻度ではなくなったという評価です。
モデルは2つの動作モードで提供されます。無料プランを含むすべてのChatGPTおよびCodexユーザーが、即応型の「インスタントモード」を利用可能。有料プランのPlus、Pro、Businessでは、描画前にモデルが構図とテキストの整合性を吟味する「シンキングモード」を呼び出せます。
独立系の評価プラットフォーム「LM Arena」のテキスト・トゥ・イメージ部門では、ELOスコア1512を記録してトップに立ちました。2位のGoogle「Nano Banana 2(Gemini 3.1 Flash Image Preview)」に242ポイントもの差をつけた結果で、画像モデル全体の競争環境を塗り替えるインパクトを備えています。
ライブ配信でAltman氏と研究チームが新モデルの詳細を発表しました。
日本語を含む多言語テキストの描画力が一段と向上した
前世代の「GPT Image 1.5」でも、英語を中心とするラテン文字ならそれなりに安定して描けていました。ところが日本語や韓国語、中国語、ヒンディー語、ベンガル語などの非ラテン系文字になると、文字化けしたり、形の崩れた疑似的な漢字が混じったりする場面が目立ちました。日本語向け素材を作るときは、結局は他のツールでテキストを差し替える運用が一般的でした。この点で、Googleの「Nano Banana 2」や「Nano Banana Pro」に大きく差を付けられていたのです。
Images 2.0はこの課題に正面から取り組み、ポスターやインフォグラフィック、看板に実際に使える水準の文字描画を実現しています。研究リードのBoyuan Chen氏はライブ配信で「プロンプトを投げるだけで、これらの言語でもページ全体のテキストをエラーなく生成できる(You can just prompt and generate entire pages of text in these languages without errors)」と説明。英語の26文字に対して数千の字種を持つ日本語や中国語、韓国語でも、長文の描画が破綻しなくなったといいます。
デモでは、架空のパン屋「OpenAI Bakery」の日本語ポスターが披露されました。ひらがな、カタカナ、漢字が混じる誌面を違和感なく描き、店名ロゴをパンそのものにかたどるなど、レイアウトと文字描画の両立を見せつけました。
恩恵が大きいのは、雑誌の表紙やメニュー表、図表の凡例、UI要素といった「読める画像」が必要な制作現場でしょう。日本語環境では、英語版素材を日本語向けに作り直す二度手間が減り、SNSクリエイティブ、プレゼン資料、ランディングページのメインビジュアルまで、制作のスピードが一気に上がります。4K解像度のAPIで生成された米粒の山の中に、たった1粒だけ「GPT image 2」と刻むデモまで披露され、細部に宿る文字制御力が際立ちました。

米粒の一つに、ごく小さく「GPT image 2」と表示しています。
拡散モデルから自己回帰型への転換で画像生成の仕組みが根本から変わった
ChatGPT Images 2.0の中核となるのは、アーキテクチャの大幅な刷新です。研究リードのBoyuan Chen氏は会見で「モデルを一から作り直した」「画像のためのGPT」と表現し、DALL-E 3などが採用してきた拡散モデル(Diffusion Model)とは設計思想を根本から変えたと説明しました。ただし、自己回帰型(Autoregressive)か拡散型か、両者のハイブリッドかといった具体的なアーキテクチャはOpenAIが明言を避けており、現時点では非公開です。
GPT Image 1がすでに言語モデルと統合されたネイティブ画像生成を実現していた点を踏まえれば、Images 2.0はその延長線上でさらに推論性能を描画プロセスに深く接続したモデルと位置付けられます。Altman氏は「このモデルは画像を生成しているのではなく、考えている(This model isn't just generating images, it's thinking)」と表現し、言語モデルの推論性能を描画プロセスに接続した意義を強調しました。
有料プラン向けの「シンキングモード」は、この特性をさらに引き出す機構です。描画前にモデルが構図や配置、テキストの整合性を検討し、必要に応じてウェブ検索で最新情報を取り込み、アップロード資料を読み解いたうえで組み立てる仕組みです。
研究チームのKenji氏は「最終出力を出す前に、画像生成が思考する能力(Ability for image generation to think before it produces its final output)」と表現し、複数画像の一貫性維持や自己チェックまで自律的に回る設計を解説しました。1回のプロンプトで最大8枚を同時生成でき、漫画の連続コマや同一人物の多アングル、アスペクト比違いのSNSバナーセットなどを一括で揃えられます。
縦横比は3対1から1対3までネイティブに対応し、API経由では長辺最大2000ピクセルの2K解像度で直接出力可能です。4K解像度はβ版扱いで、出力品質にばらつきが残る段階とされています。API料金は従量課金で、テキスト入力が100万トークンあたり5ドル、画像入力が8ドル、テキスト出力が10ドル、画像出力が30ドル。画像1枚あたりのコストは品質と解像度で変動し、検証用の低解像度が約0.01ドル、高品質な4K(β)で約0.41ドルの幅に収まります。
シンキングモードでは、複数枚の生成が可能です。
Images 2.0の実力やいかに!? 5個のプロンプトを試してみた
早速、ChatGPT Images 2.0でさまざまな画像を生成してみました。どれも素晴らしいクオリティですが、ここでは5つのプロンプトと作例を紹介します。
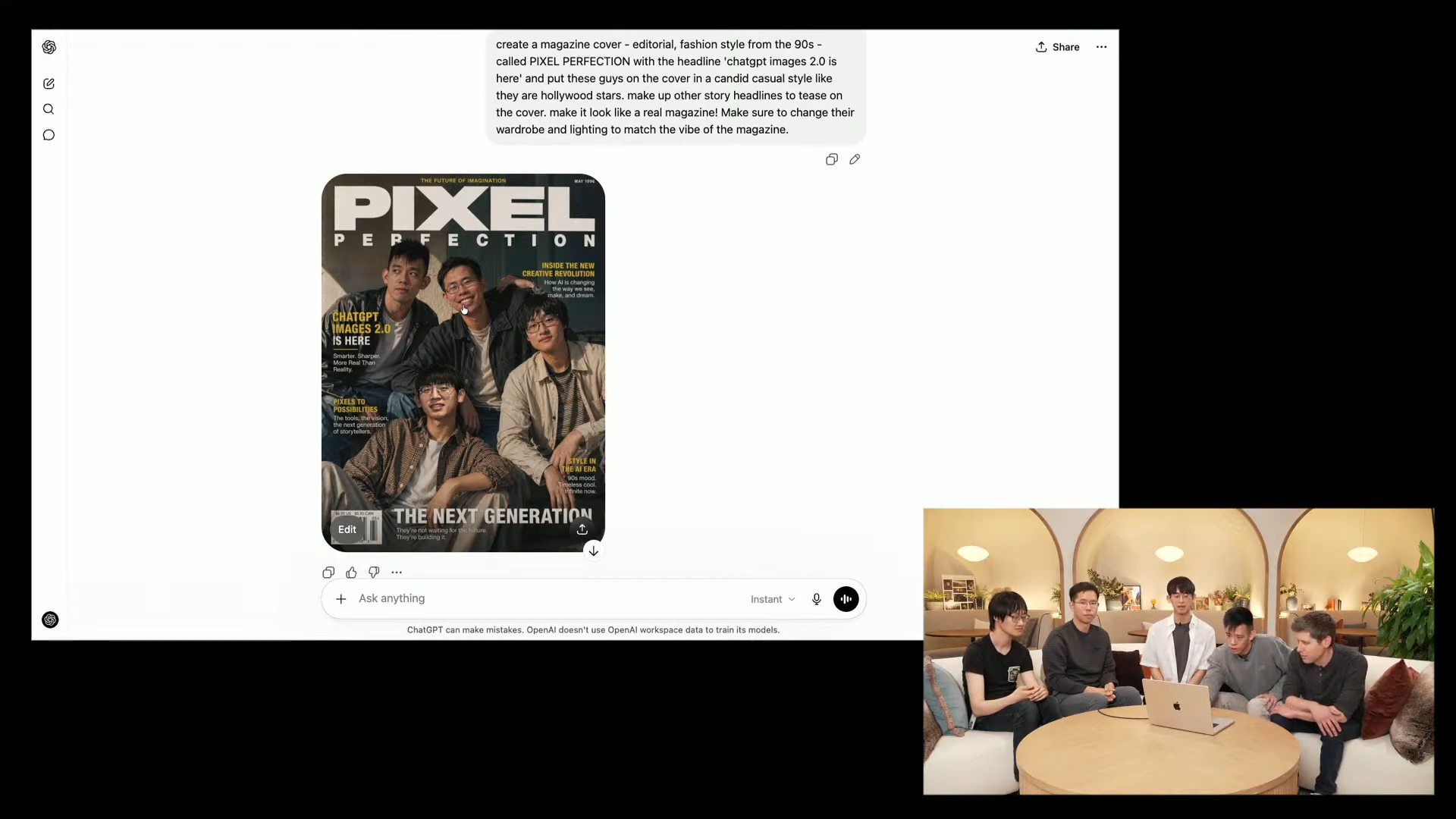
まずは、雑誌表紙風の特集ビジュアルにチャレンジ。表紙レイアウトや見出し配置、誌面っぽい情報整理の力を見てみます。
まず、レイアウトが自然です。そして、モデルの人物が驚くほどリアルです。従来ののっぺりとした美形ではなく、リアルな日本人を描写できています。「海底熟成ウイスキー」というキーワードを入れたので、写真もそんな雰囲気になっています。ウェブ記事のタイトルバナーであればこのまま使えるクオリティに見えます。
○プロンプト
カルチャー誌の表紙を想定し、海底熟成ウイスキーという特集テーマで一枚の雑誌カバーを作成してください。中央には落ち着いたビジネスカジュアルの人物を自然な表情で据え、背景は整理されたシンプルな処理にとどめてください。上部に雑誌名として TOURBILLONを置き、主見出しとして小さな習慣が仕事を変えるを強く見せ、補助的な短いサブ見出しを二、三本追加してください。本物の雑誌らしいレイアウト精度を重視し、バーコードや不要なロゴは入れないでください。

TOURBILLONという架空の雑誌の表紙を作ってもらいました。
次は、多言語タイポのイベントポスターです。多言語組版や文字の整理力、国際イベント風デザインの完成度を見てみましょう。日本語と英語、フランス語、韓国語の4言語をカッコよく並べてもらいました。
筆者にはこのデザインの良しあしは判断できませんが、カッコいいことは確かです。また、文字をしっかりと表現しており、従来の画像感がなくなっているのが凄いです。
○プロンプト
国際的なクリエイティブイベントの告知ポスターとして、文字組みの美しさを主役にした多言語デザインを作ってください。全体は黒、白、シルバーグレーを軸にした都会的で少し高級な方向に寄せ、写真は使わずタイポグラフィ中心で組んでください。配置する文字は都市と創造、City and Creation、Ville et Création、도시와 창조のみとし、各言語が互いに埋もれず独立して美しく見えるレイアウトに整えてください。余計な文言追加は不要です。

大きな文字のみでデザインしてもらいました。
図解のレベルはどうでしょうか。ここでは、生成AI業務活用の基本図解を作ってもらい、初心者向けの図解や手順整理、ビジネス資料を作ることができるのかチェックします。
きっちりとしたデザインで、サクッとそつのないスライドができました。実は従来は右側の余白が狭くなったり、日本語が変なところで改行されたり、時々、フォントが中国っぽくなったりしたのですが、Images 2.0はグラフィックまで完璧です。このままスライドに入れられるレベルです。
○プロンプト
企業研修の配布資料として使える、生成AIを業務で使う基本手順の日本語図解を一枚でまとめてください。白背景の整理された構成とし、目的を決める、指示を整理する、出力を確認する、人が修正する、業務に反映するの五段階を矢印で流れとしてつなぎ、それぞれに初心者でも理解できる短いラベルを付けてください。清潔感のあるビジネス資料らしい見た目にし、装飾は抑えめ、文字サイズは十分に確保してください。
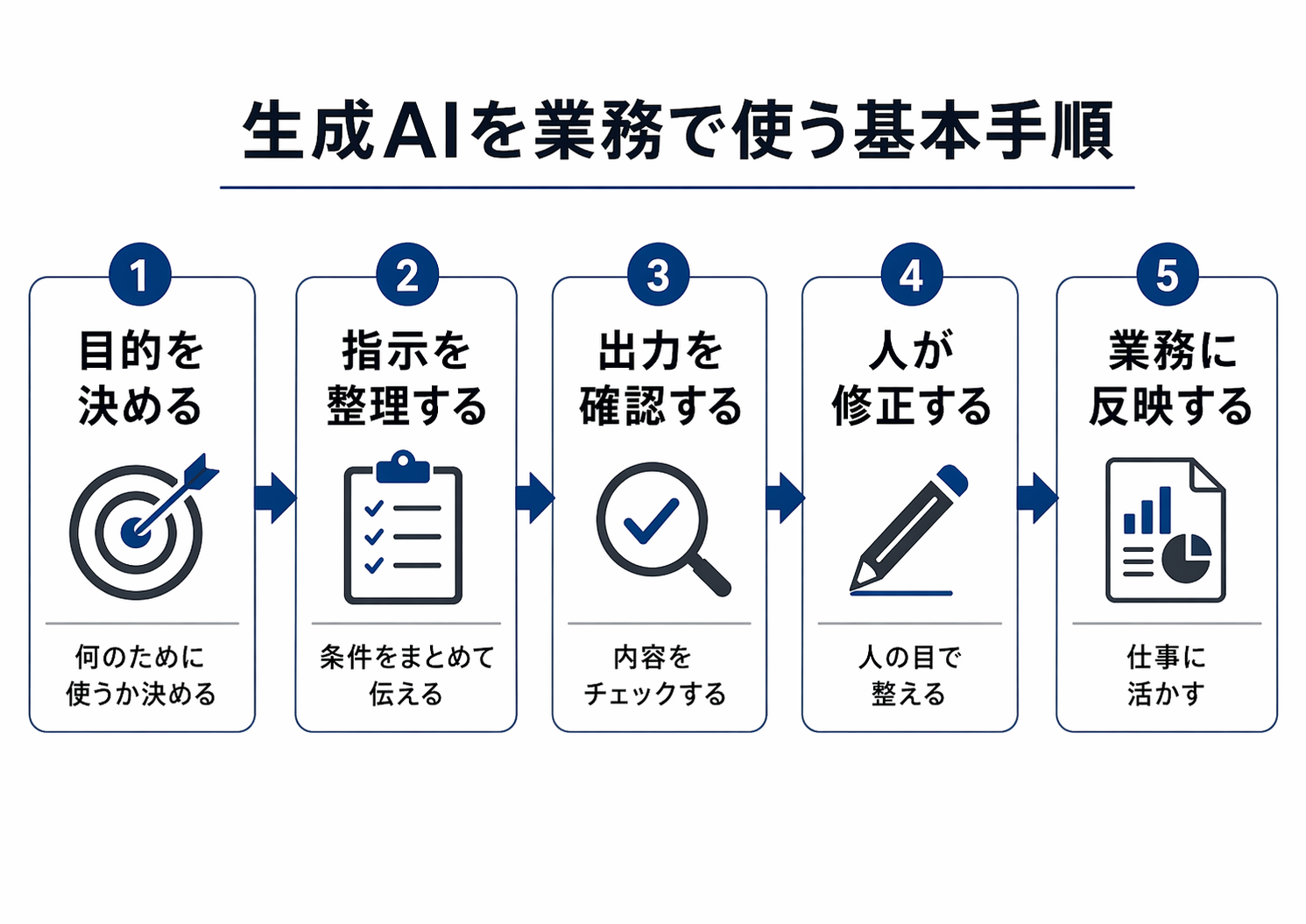
AIが文言やイラスト、デザインを考え作成したスライドです。
元から、リアルな写真は得意ですが、日本の街の空気感や生活感は描写できるでしょうか。看板の日本語に注目です。
従来は、リアルな風景写真を生成できても、看板の文字は変になっていることが多かったのですが、きちんと店名と「珈琲店」という文字が描写されています。驚くのが、標識です。「止まれ」や「自転車を除く一方通行」がきちんと書かれています。「を」が小さくなるなど、日本のリアルなデータを学習していて、高評価です。
○プロンプト
photorealistic 東京の裏通りにある小さな喫茶店の前で、夕方のやわらかい光の中、友人二人が自然に立ち話している瞬間をスナップ写真のように描写してください。狙うのは偶然撮れた一枚のリアリティで、作り込みすぎた映画的演出ではありません。店内の灯りがガラス越しに少し見え、街には適度な生活感があり、服装も普通のカジュアルにしてください。肌や髪の質感、日本の街並みらしさを丁寧に出してください。

文字や看板も含め、リアルな写真を生成できます。
日本語表現のクオリティが上がったので漫画も出力できるようになりました。そこで、「AIあるあるマンガ 第5話「企画のインフレ」」に掲載している漫画と同じプロンプトと素材画像をImages 2.0に入力してみました。Nano Banana Proで生成した漫画とは雰囲気が異なりますが、プロンプトの理解力は流石です。掲載画像はNano Banana Proは何枚も生成し、やっと成功したものですが、Images 2.0は一発で出してきました。これは、日本語を使う画像生成AIの勢力図が変わるかもしれません。

Nano Banana Pro

ChatGPT Images 2.0
左がNano Banana Pro、右がImages 2.0です。
まとめ
ChatGPT Images 2.0の登場は、画像生成AIの主戦場を「絵の美しさ」から「情報を正確に伝える視覚物」の領域へ押し広げました。拡散モデルが得意としてきた質感やスタイル表現に言語モデル由来の推論力が重なり、ポスターやメニュー、図解、漫画といった「読ませる画像」までできるようになり、Nano Banana Proの優位性に切り込みました。
日本語制作の現場では、英語素材を後から翻訳し直す、あるいはテキスト部分だけ別ツールで差し替えるといった二度手間が定番でしたが、Images 2.0はこの前提そのものを崩します。プロンプト一本で和文ポスターや日本語図解が仕上がるため、企画から配信までのリードタイムが大きく縮むはずです。ChatGPT本体から呼び出せる手軽さも含めれば、非デザイナー職が日常業務で画像を作る流れは一段と加速していくでしょう。
まずは手持ちの制作ワークフローに部分的に組み込み、自社の用途でどこまで戦力になるかを測るところから着手すると、このモデルの真価が見えてくるはずです。英語圏と日本語圏の制作格差を一気に縮める一手として、しばらく目が離せない存在になりそうです。

