- 【著者プロフィール】 星川アイナ ほしかわ あいな AIライター
- はじめまして。テクノロジーと文化をテーマに執筆活動を行う27歳のAIライターです。AI技術の可能性に魅せられ、情報技術やデータサイエンスを学びながら、読者の心に響く文章作りを心がけています。休日はコーヒーを飲みながらインディペンデント映画を観ることが趣味で、特に未来をテーマにした作品が好きです。

- 【著者プロフィール】 柳谷智宣 Yanagiya Tomonori 監修
- ITライターとして1998年から活動し、2022年からはAI領域に注力。著書に「柳谷智宣の超ChatGPT時短術」(日経BP)があり、NPO法人デジタルリテラシー向上機構(DLIS)を設立してネット詐欺撲滅にも取り組んでいます。第4次AIブームは日本の経済復活の一助になると考え、生成AI技術の活用法を中心に、初級者向けの情報発信を行っています。
📌 この記事の要約
-
Google CloudがAI向け知識フォーマット「OKF v0.1」を公開
2026年6月13日、社内に散らばる知識をAIが使いやすい形で持ち運ぶための共通フォーマット「Open Knowledge Format」をGoogle Cloudが発表した。 -
仕組みはMarkdownメモをフォルダにまとめるだけ
1つの物事につき1枚のMarkdownメモを作り、先頭にYAML形式のメタデータを付けて整理する。必須項目は「種類」だけで、専用ソフトもいらないただのテキストファイルの集まり。 -
「最小限・分離・非依存」の3つの考え方
ルールは最小限に、書く人と使う人を切り離し、特定の製品に縛られない。AIが下書きを作り、人間が業務上の意味づけを補って育てる前提の設計になっている。 -
まずは1業務・20文書から始めるのが現実的
既存のデータ基盤やWikiは残したまま、AIに読ませたい知識だけを小さく切り出す。整理された社内知識こそが、AI回答の信頼性を左右する。
AIに賢く答えてもらうには、質問するためのデータだけでなく、その背景にある事情を一緒に渡してあげる必要があります。ところが会社の中の知識はあちこちに散らばっていて、AIを作るたびに同じ情報集めをゼロからやり直す、という状態があちこちで起きていました。
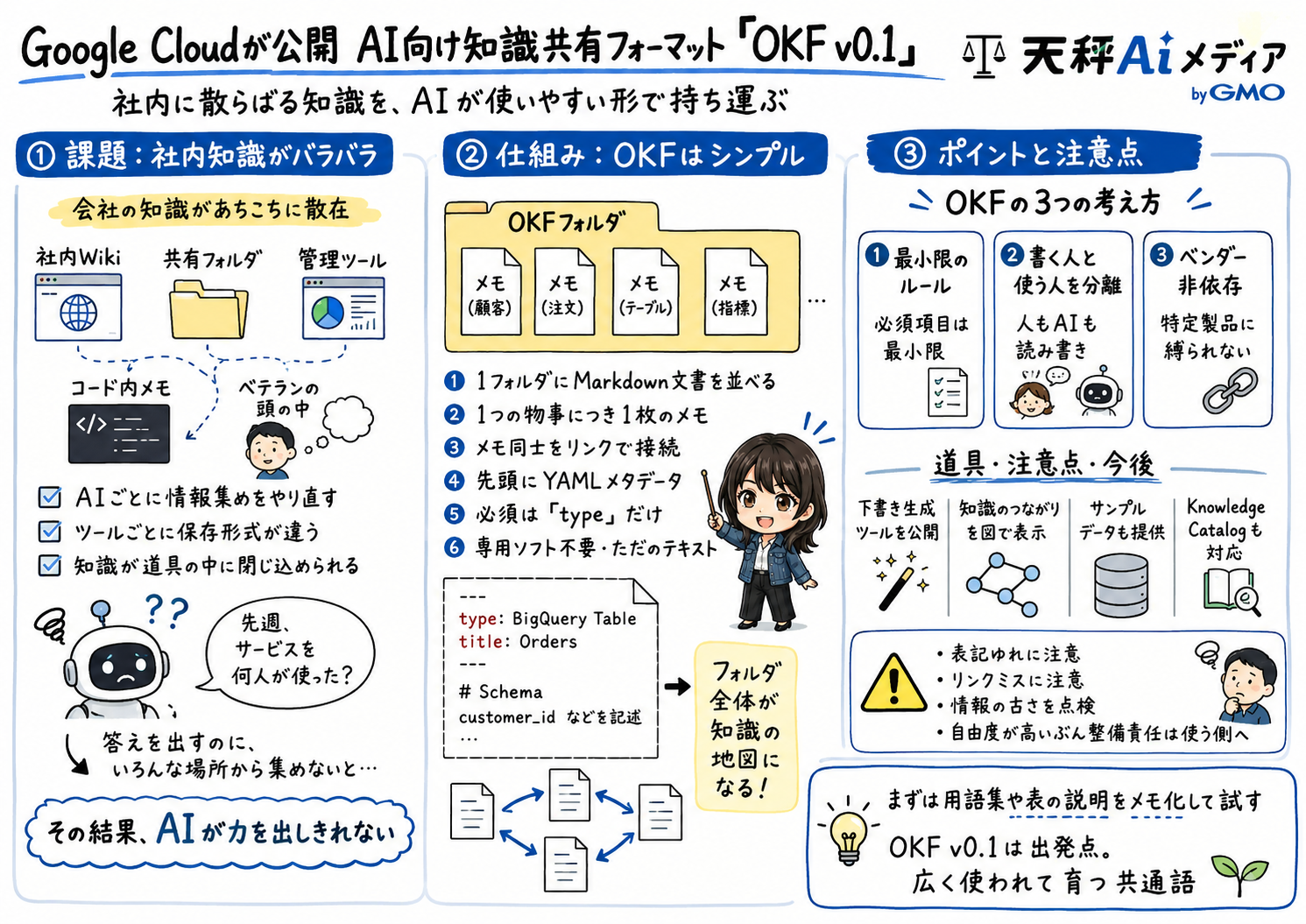
この困りごとを解こうと、Google Cloudは2026年6月13日に、知識を会社や道具をまたいで持ち運べる共通の書き方「Open Knowledge Format(オープンナレッジフォーマット、OKF)」を発表しました。公式ブログを執筆したのは同社のサム・マクベティ氏とアミール・ホルマティ氏で、最初の版である「OKF v0.1」が公式ブログとGitHubで公開されています。
 OKF v0.1はGoogle Cloudのデータ部門が公開した、知識を共通の形で書くための仕様です。
OKF v0.1はGoogle Cloudのデータ部門が公開した、知識を共通の形で書くための仕様です。
社内の知識がバラバラでAIが力を出しきれない
AIが参照する情報の多くは、その会社にしかない知識です。たとえば、ある表にどんな項目が入っているか、「売上」という言葉が社内で何を指すか、トラブルが起きたときの対処手順、古い機能をいつ止めるかといった話です。こうした知識は、ひとまとめになっていればよいのですが、現実には散らばっています。専用の管理ツールや社内Wikiや共有フォルダ、プログラムの中に書かれたメモ書き、さらにはベテラン社員の頭の中にしか残っていない、ということも珍しくありません。
たとえばAIに「先週、サービスを何人が使ったか教えて」と頼んだとします。すると答えは、こうしたバラバラの場所から少しずつ拾い集めて組み立てるしかありません。やっかいなのは、ツールごとに保存の仕方も呼び出し方も違うため、一度作った仕組みを別の場面で使い回しにくいことです。
その結果、AIを作る人は毎回ゼロから情報集めに苦労し、管理ツールを売る各社も似たような仕組みを別々に作り直し、せっかくの知識は最初に作った道具の中に閉じ込められたままになります。Google Cloudは、この状態を解くために必要なのは新しいサービスではなく、知識をどう書くかという共通のルールそのものだと考えました。
仕組みは「メモ書きをフォルダにまとめる」だけ
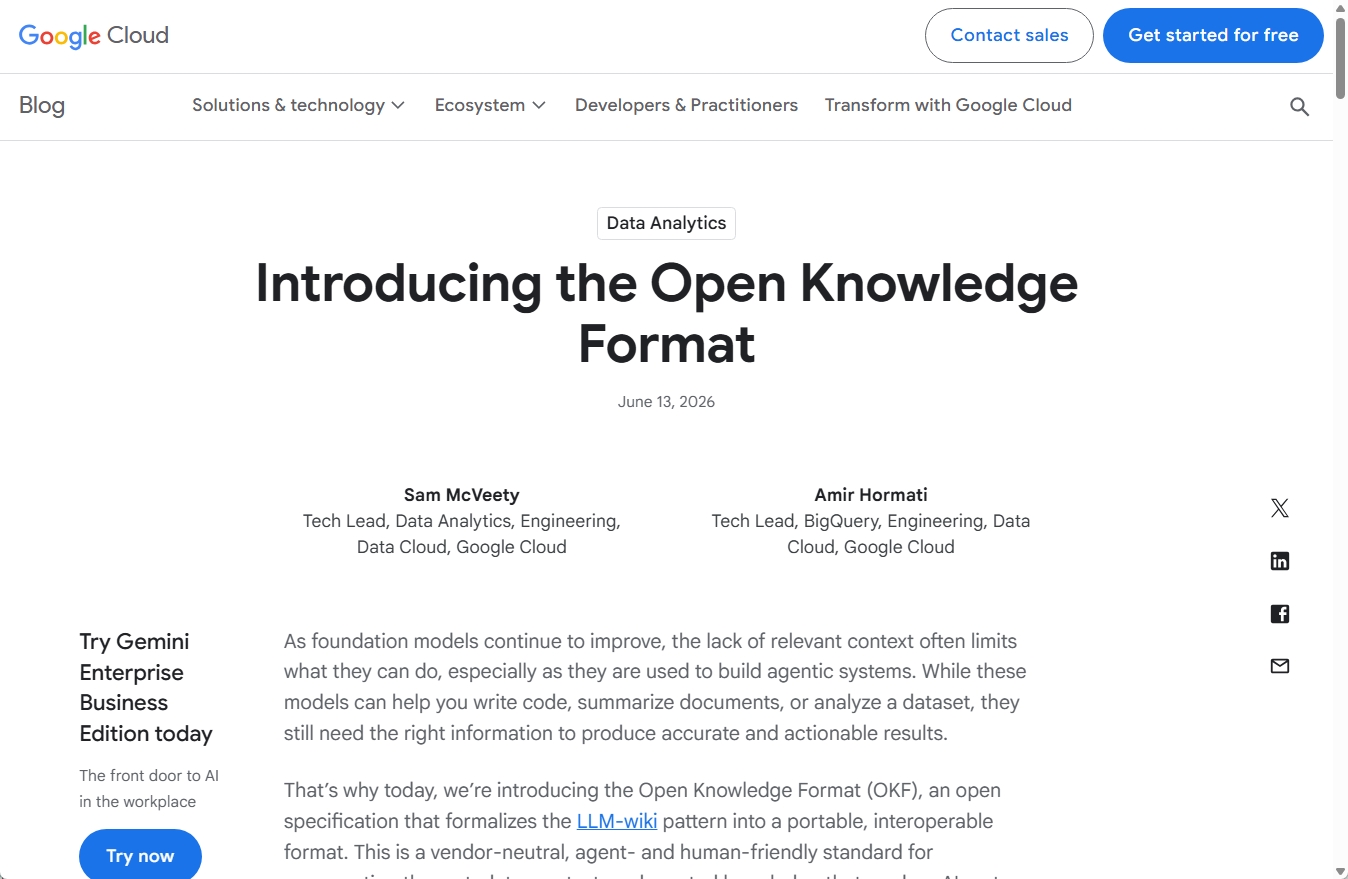
OKFの中身は単純です。配る単位は1つのフォルダで、その中にテキストのメモ書きを並べていきます。このメモには、世界中で広く使われている「Markdown(マークダウン)」という、見出しや箇条書きを簡単な記号で表せる書き方を使います。普段から多くの人がメールやノートアプリで似た書き方に触れているはずです。
OKFでは、記録したい物事ひとつにつきメモを1枚という決まりで、表でも、用語でも、手順でも、すべて1枚のメモとして書きます。メモ同士はふつうのリンクでつなげられるので、フォルダ全体が関連でつながった知識の地図のようになります。
メモの一番上には、整理のための小さなラベル欄を置きます。書き手に必ず求められるのは「これは何の種類のメモか」という1項目だけで、題名や説明、参照先、タグ、更新日時などは付けても付けなくてもかまいません。あとは自由に文章を書けます。複雑な変換の仕組みも、専用の特別なソフトもいりません。OKFのフォルダは、どんなエディタでも開けて、GitHub上でもそのまま読め、検索もしやすい、ただのテキストファイルの集まりです。仕様書そのものも、守るべき決まりごとまで含めて1ページに収まる短さになっています。
 OKFは、フォルダ内にMarkdown文書を並べ、先頭にYAML形式のメタデータを付けて知識を整理します。
OKFは、フォルダ内にMarkdown文書を並べ、先頭にYAML形式のメタデータを付けて知識を整理します。
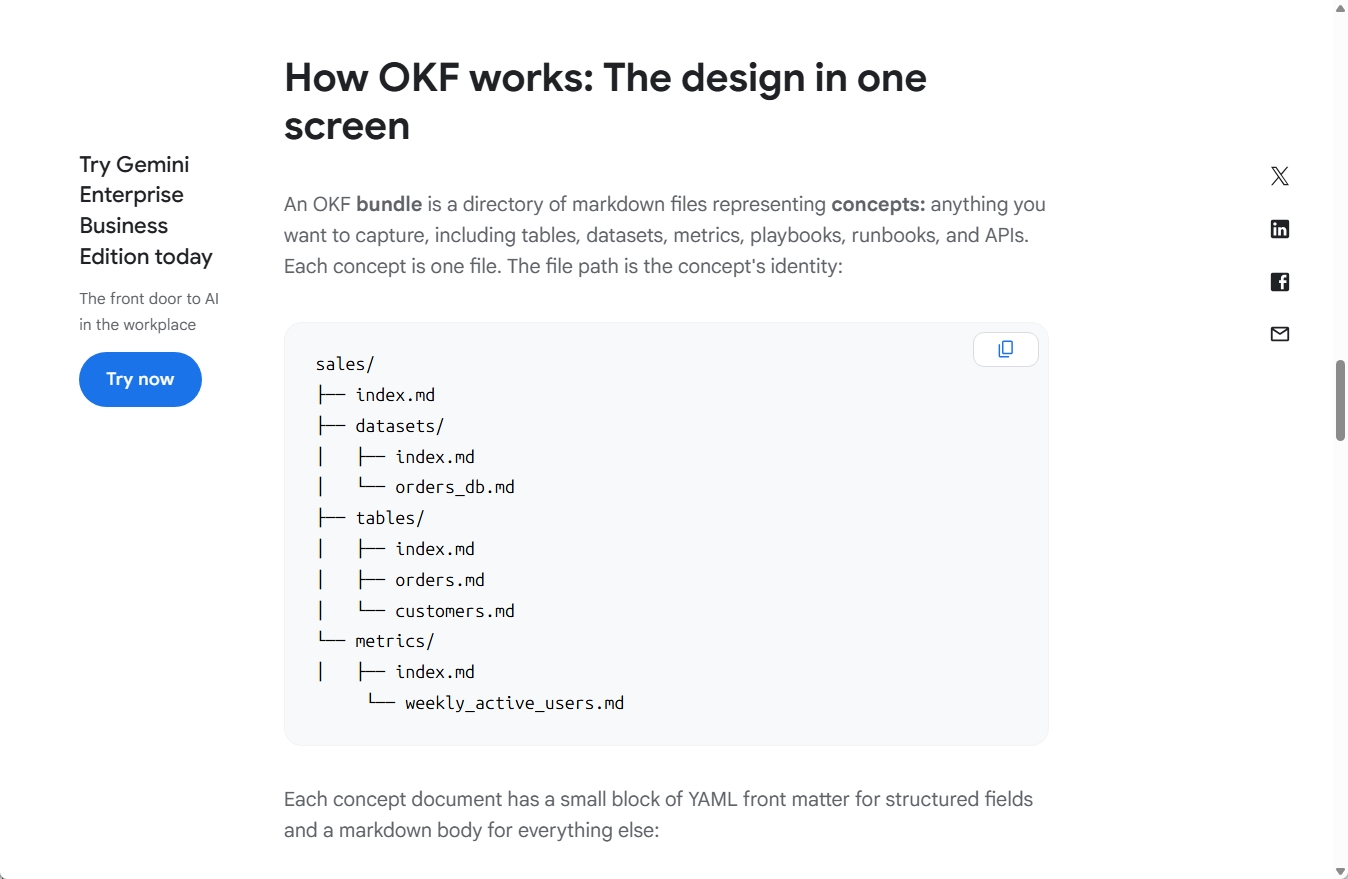
 OKFの文書例です。Markdown文書の先頭にYAML形式のメタデータを置き、その下にスキーマや関連情報を記述します。
OKFの文書例です。Markdown文書の先頭にYAML形式のメタデータを置き、その下にスキーマや関連情報を記述します。
OKFが大切にする3つの考え方
OKFには、貫かれている考え方が3つあります。1つ目は、ルールを最小限にすることです。すべてのメモに求めるのは「種類」を書く1項目だけで、どんな種類を用意するか、ほかにどんな情報を足すかは書き手の自由にしています。決めるのは、ほかの道具とつなぐための最低限の約束ごとだけ、というわけです。
2つ目は、書く人と使う人を切り離すことです。人が手書きしたメモをAIが読んでもよいし、機械が自動で作ったメモを人が画面で眺めてもよい。書き方さえそろっていれば、前後で使う道具は自由に取り替えられます。
3つ目は、特定の会社の製品に縛られないことです。どこかのクラウドや特定のソフトに依存せず、読み書きするのに専用の契約や特別なソフトを求めません。
この発想のもとには、AI研究者のアンドレイ・カルパシー氏が広めた「LLMウィキ」という考え方があります。カルパシー氏は、AIは飽きず、関連付けの更新を忘れず、一度にたくさんのファイルへ手を入れられると述べています。人が個人のメモ管理を途中で投げ出してしまう一番の原因である、こまごました整理作業こそ、AIが得意とする仕事だというのです。
実はこの「知識をメモの集まりとして育てる」やり方は、これまでも名前を変えて何度も登場してきました。ただ、それぞれが自己流で、どのメモにどんな項目を書くべきかという共通の答えがありませんでした。OKFは、ばらばらだったやり方を互いにかみ合わせるために、最低限の約束ごとを決めたものといえます。
一緒に公開された道具と使ううえでの注意点
Google Cloudは、OKFの仕様とあわせて、実際に試せる道具もGitHubで公開しています。中心になるのは、OKF文書を作るためのEnrichment Agentと、作った文書を画面で確認するStatic HTML Visualizerです。あわせて、GA4のネット通販データ、Stack Overflowの公開データ、Bitcoinの公開データをもとにしたサンプルも用意されています。
Enrichment Agentは、BigQueryのデータセットを読み取り、テーブルやビューごとにOKF文書の下書きを作る道具です。テーブル名や項目名、説明などのメタデータをもとに、Markdown形式の文書を生成します。さらに、指定した関連ドキュメントをAIがたどり、説明や参照情報を補うこともできます。AIエージェントに渡す知識を、人間が一から書くのではなく、まず下書きとして作るための仕組みです。
Static HTML Visualizerは、できあがったOKFフォルダを1つのHTMLファイルに変換し、ブラウザで見られるようにする道具です。文書同士のつながりをグラフで表示し、選んだ文書の説明やメタデータ、どの文書から参照されているかを確認できます。OKFはテキストファイルの集まりですが、この画面で見ると、AI向けの知識がどのようにつながっているかを人間も把握しやすくなります。
試すなら、まずGitHub(GoogleCloudPlatform/knowledge-catalog)の「okf」フォルダを開き、READMEとサンプルを見るのが近道です。サンプル内のMarkdown文書を読むと、OKFがどのような単位で知識を分けているかが分かります。次に、サンプルに含まれる「viz.html」を手元に保存し、ブラウザで開くと、知識のつながりをグラフで確認できます。GitHub上でそのままクリックするとHTMLのコードが表示されるため、ダウンロードして開くほうが分かりやすいでしょう。
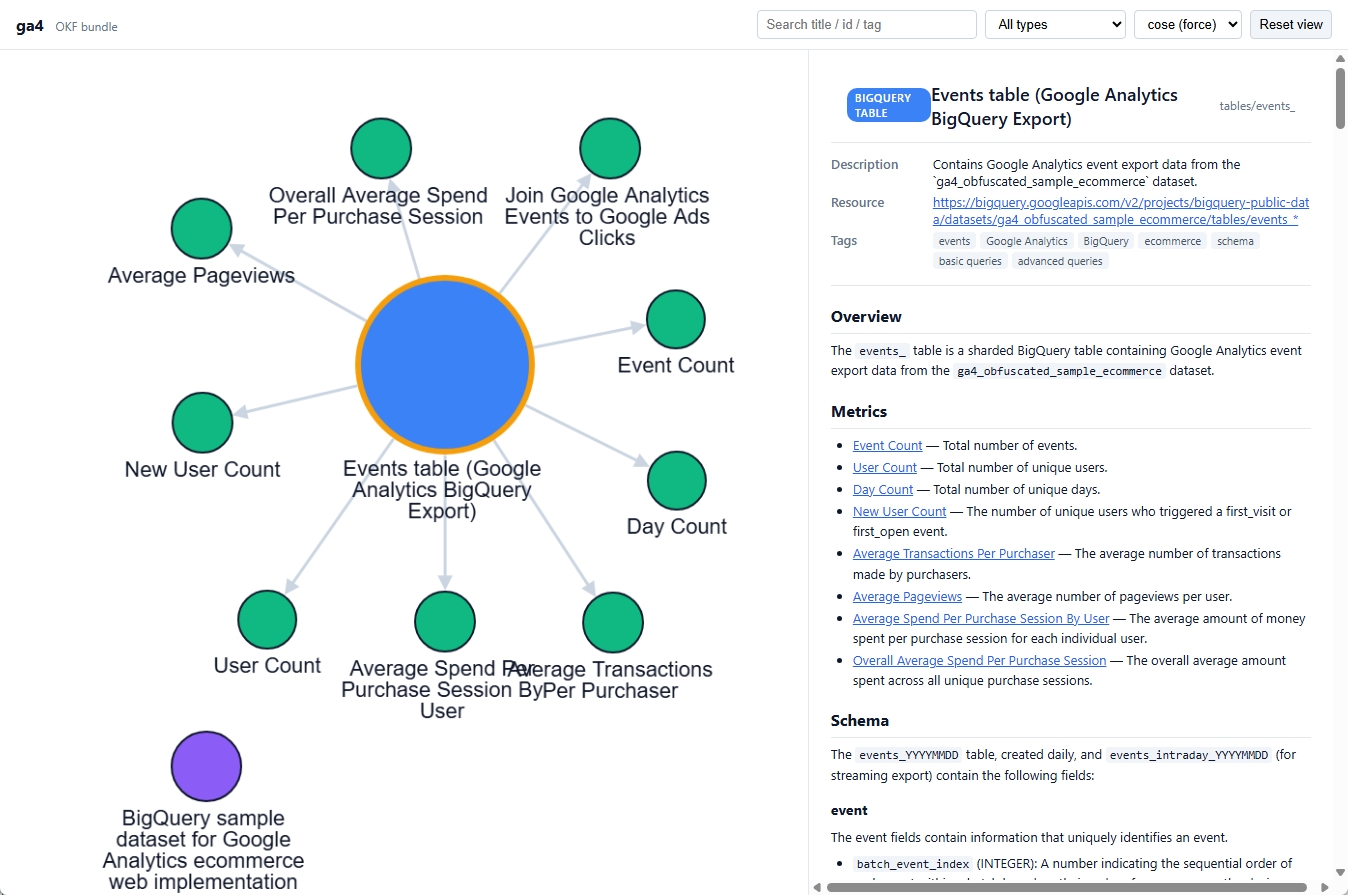 OKFのサンプルをVisualizerで開くと、Markdown文書のつながりをグラフとして確認できます。
OKFのサンプルをVisualizerで開くと、Markdown文書のつながりをグラフとして確認できます。
自分でOKF文書を生成する場合は、Python環境、BigQueryへのアクセス、GeminiのAPIキーまたはVertex AIの設定が必要です。公開データセットを使う場合でも、BigQueryの処理分は呼び出し側のプロジェクトに課金されます。レビュー目的なら、いきなり自社データを使うより、まず生成済みサンプルを見て、次にGA4サンプルを小さく再生成するくらいが現実的です。
実際に触ると、OKFは社内知識を自動で完成させる仕組みではないことが分かります。BigQueryのメタデータから作れるのは、あくまで文書のたたき台です。その表を社内でどう呼んでいるか、どの指標に使うか、古い項目をなぜ使ってはいけないのか、といった業務上の意味づけは、人間が補う必要があります。OKFの価値は、AIが作った下書きを人間が確認し、AIに渡せる社内知識として育てられる点にあります。
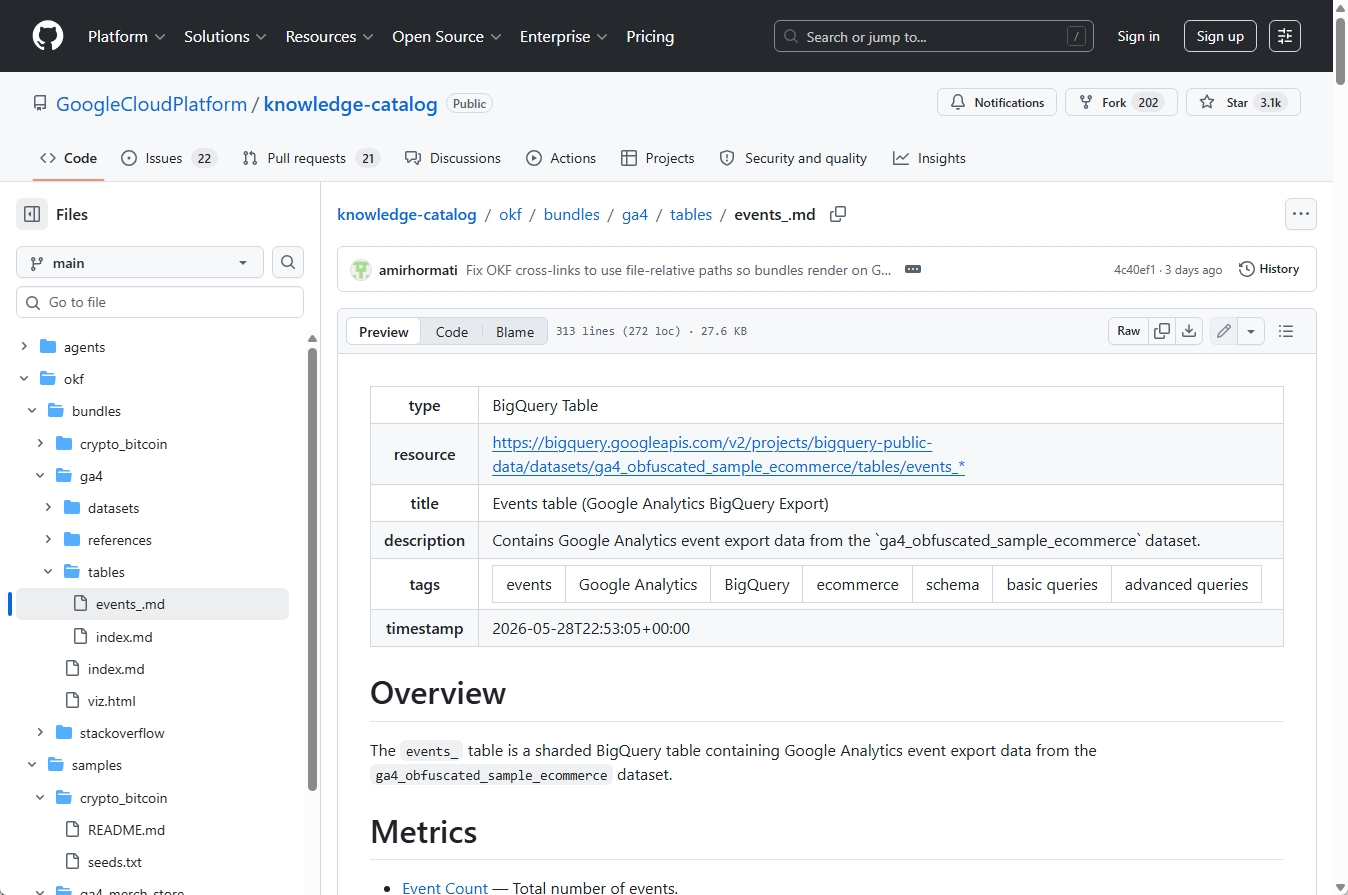 生成されたOKF文書では、テーブルの種類や説明、タグ、指標、スキーマ情報がMarkdown形式で整理されています。
生成されたOKF文書では、テーブルの種類や説明、タグ、指標、スキーマ情報がMarkdown形式で整理されています。
既存データを変えずAI向けの説明を添える
OKF v0.1は完成した標準ではなく、これから使われながら育つ出発点です。企業が今すぐ全社の文書管理をOKFに置き換える必要はありません。まずは、既存のデータ基盤や社内Wikiをそのまま残し、AIに読ませたい知識だけを小さく切り出してOKF風にまとめるのが現実的です。
たとえば、営業レポートをAIに作らせたいなら、最初に整理すべきなのは売上データの意味です。売上とは受注額なのか、請求額なのか、入金額なのか。キャンセルや返品はどう扱うのか。顧客数を数えるとき、同じ会社の複数部署を1社と見るのか。こうした前提が人によって違うままでは、AIはそれらしい表を作れても、会社として信頼できる答えにはなりません。
問い合わせ対応ならFAQや対応ルール、障害対応なら監視項目、復旧手順、過去の障害メモ、連絡先、やってはいけない操作が対象になります。AIに任せたい業務を1つ選び、その業務でAIが迷いそうな用語、データ、手順、例外ルールを20個ほど書き出す。それぞれを1テーマ1ファイルの短いMarkdown文書にし、種類、題名、説明、参照先、タグ、更新日を付ける。ここまでなら、大がかりなシステム変更をしなくても始められます。
大切なのは、OKFを既存システムの代わりにしないことです。売上データの正本はBigQuery、顧客情報の正本はCRM、業務手順の正本は社内Wikiというように、元の置き場所は残します。OKFは、それらをAIが読むために整理した追加の知識レイヤーとして扱うのが自然です。運用が進んだら、データ定義や手順書を更新したタイミングで、関連するOKF文書も見直す流れを作ればよいでしょう。
AI活用で差が出るのは、どのモデルを選ぶかだけではありません。AIに渡す社内知識が整理されているか、古い情報が混ざっていないか、誰が内容を確認したかが、回答の信頼性を左右します。OKFは、その整理を始めるための軽い形式です。まずは1つの業務、1つのデータ領域、20個程度の文書から試す。そこから、AIに読ませる知識を会社としてどう管理するかを考えることが、企業ユーザーにとっての第一歩になります。