画像生成AI
圧倒的な生成スピードと一貫性でGoogleに挑むOpenAI画像生成AIモデル「GPT Image 1.5」の全貌とNanoBananaとの比較
-
-

[]

アイサカ創太(AIsaka Souta)AIライター
こんにちは、相坂ソウタです。AIやテクノロジーの話題を、できるだけ身近に感じてもらえるよう工夫しながら記事を書いています。今は「人とAIが協力してつくる未来」にワクワクしながら執筆中。コーヒーとガジェット巡りが大好きです。
2025年12月16日、OpenAIは画像生成AIの最新フラッグシップモデル「GPT Image 1.5」をリリースしました。Googleの画像生成AI「Nano Banana Pro」のクオリティが高すぎて、勝負あったかと思いきや、すぐに対抗馬を出してくるのだからOpenAIの底力を感じます。OpenAIのサム・アルトマンCEOが社内で「コード・レッド(緊急事態)」を宣言したと報じられていることからも、彼らの危機感の強さが窺えますね。
今回は、このGPT Image 1.5についての解説と、実際に色々とテストした結果とプロンプトをまとめて紹介します。
OpenAIの画像生成AIがバージョンアップしました!
運任せの生成から脱却し、狙った画像を作れるツールへと進化
2025年8月、画像生成AIのコミュニティはある奇妙な名前のモデルに沸いていました。「Nano Banana(ナノバナナ)」。これはGoogleの開発者が深夜の作業中に仮の名称として入力したものが、そのまま愛称として定着してしまったGemini 2.5 Flash Imageのことです。Nano Bananaの強みは圧倒的な生成スピードと、人物の顔立ちや雰囲気を維持する一貫性にありました。
これに対し、従来のOpenAIのモデルは、指示をするたびに構図や人物がガラリと変わってしまう「ガチャ(運任せ)」の要素が強く、プロの現場での導入を阻む壁となっていました。GPT Image 1.5の開発チームが注力したのは、まさにこの課題の解決です。新モデルは前世代と比較して生成速度が最大4倍となっており、Googleの「Flash」シリーズが提供する高速生成体験に真正面から対抗しています。クリエイティブな作業において、思考を分断させないスピードは極めて重要です。
これまで「数打ちゃ当たる」方式で、何十枚も生成して良い一枚を選ぶスタイルだった画像生成が、GPT Image 1.5によって「狙って作る」スタイルへと変化します。これは、AI画像生成ツールを単なる遊び道具から、デザイン、EC、広告制作といったビジネスの最前線で使える「信頼できる文房具」へと昇華させるための必須条件でした。
GPT Image 1.5は複雑かつ論理的なプロンプトを忠実に再現します。OpenAIがデモンストレーションとして提示した事例は、多くの開発者を驚愕させました。「6×6のグリッド内に、ギリシャ文字、ビーチボール、カマキリ、バスタブなど36種類の異なるオブジェクトを指定通りに配置させる」というタスクを正確に遂行して見せたのです。
これは、モデルが単に単語を概念として拾っているのではなく、空間的な配置やオブジェクト同士の関係性を論理的に理解し、それをピクセル情報に変換する「視覚的推論(Visual Reasoning)」の能力を獲得したことを意味します。
●プロンプト
1行目:ギリシャ文字のベータ、ビーチボール、レモン、ロボット、水槽、カエル
2行目: カマキリ、高価な時計、バスタブ、サングラス、カラフルな蝶、封筒
3行目: 切手、額縁、湯気の立つ餃子、「奇跡」という言葉、スキー板、Zの文字
4行目:トイレ、地下鉄の切符、ミュートアイコン、香水瓶、トンボ、スケートボードのヘルメット
5行目: Bluetoothアイコン、数字の13、緑のハート、ルービックキューブ、カナダグース、兵士のヘルメット
6行目:白い犬、ライフジャケット、結び目、キーボード、ティッシュボックス、数字14
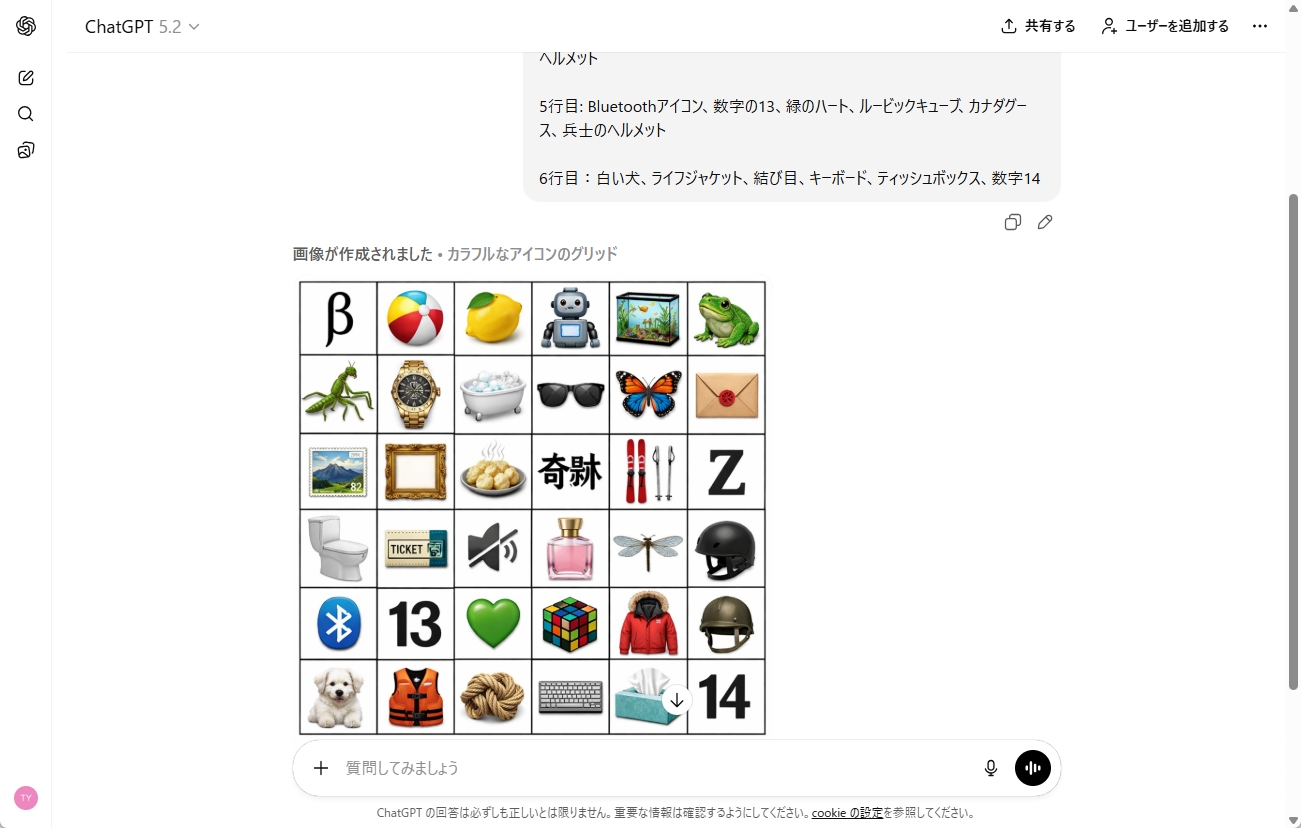
指示への追従性と描写力が上がっています。ただし、日本語が文字化けしています。
この推論能力は、実務における「修正」の場面で真価を発揮します。従来モデルでの修正は、例えば「人物の服を冬物に変えて」と指示すると、ポーズや顔の造形、あるいは背景の照明まで勝手に変わってしまうことがありました。しかしGPT Image 1.5は「一貫性を保った精密な編集」が可能です。画像の特定部分のみを変更し、それ以外の要素を凍結したまま保持することができるのです。これは単なる画像の切り貼り(インペインティング)を超え、背景の文脈を理解した上での自然な統合が行われます。
さらに、長らく生成AIの弱点とされてきた画像内の文字生成(テキストレンダリング)についても改善が見られます。ポスターやラベル、説明図などに含まれる高密度のテキストも、英語であれば十分に判読可能なレベルで生成できるようになりました。ただし、長い文章や特殊なフォント、特に日本語のフォントに関してはGoogleのNano Banana Proに分があるようです。
●プロンプト
# Introducing GPT‑5.2
### *The most advanced frontier model for professional work and long-running agents*
**December 11, 2025**
---
We are introducing **GPT‑5.2**, the most capable model series yet for professional knowledge work.
~略

OpenAIのサイトにあるサンプルプロンプトで英字新聞を生成してみました。
新設された専用タブやプリセットを活用して直感的に画像生成と編集を行う
OpenAIはモデルの進化に合わせて、ユーザーインターフェースも刷新しました。ChatGPTのサイドバーに追加された「画像」専用タブは、チャットボットとの対話の延長ではなく、独立した「クリエイティブスタジオ」のようです。
ユーザーはゼロからプロンプトをひねり出す必要はなく、用意されたスタイルプリセットやトレンドのデザインを選択して生成を開始できます。また、生成された画像をストックし、後から編集を加えるプロジェクト管理のような使い方も簡単になりました。モバイルファーストなUIで、外出先でスマホからラフを作り、オフィスで詳細を詰めるといったシームレスな作業が行えます。
スマホアプリにも「画像」タブが追加されました。
APIの料金もGPT Image 1と比較して20%安くなりました。大量の画像を定型的に処理するエンタープライズ用途での採用が進むかもしれません。Microsoft Azure上の基盤を活用する企業にとって、コストの予見性が高まることは大きなメリットです。API経由での自動化が進めば、個々のユーザーが手作業で生成するフェーズを超え、システムが自律的に広告クリエイティブやパーソナライズされたコンテンツを生成できるようになります。
では実際にGPT Image 1.5を使ってみましょう。ChatGPTの「画像」タブを開き、画面上部のプロンプトに画像の説明を入力します。その下には、「スタイルを画像で試す」や「新しい発見をする」といったワンクリックで画像生成が楽しめるメニューが用意されています。とはいえ、これはOpenAIが作ったプロンプトをプリセットしているだけなので、特別な機能はありません。
試しに、犬の写真をアップロードし、「ガシャポン」画像を生成してもらいました。まずは「ガシャポン」をクリックしてから画像をドラッグ&ドロップすると、通常のチャット画面に移行します。確かに、従来よりもずっと早く生成されるようになっています。
プロンプトが作り込まれていたので、ガシャポンの描写はリアルでした。それよりも、写真を正確に分析し、再現しているのが流石です。単なる黒柴犬をフィギュアにするだけでなく、犬の特徴もしっかり描写しています。
●プリセットされていたプロンプト
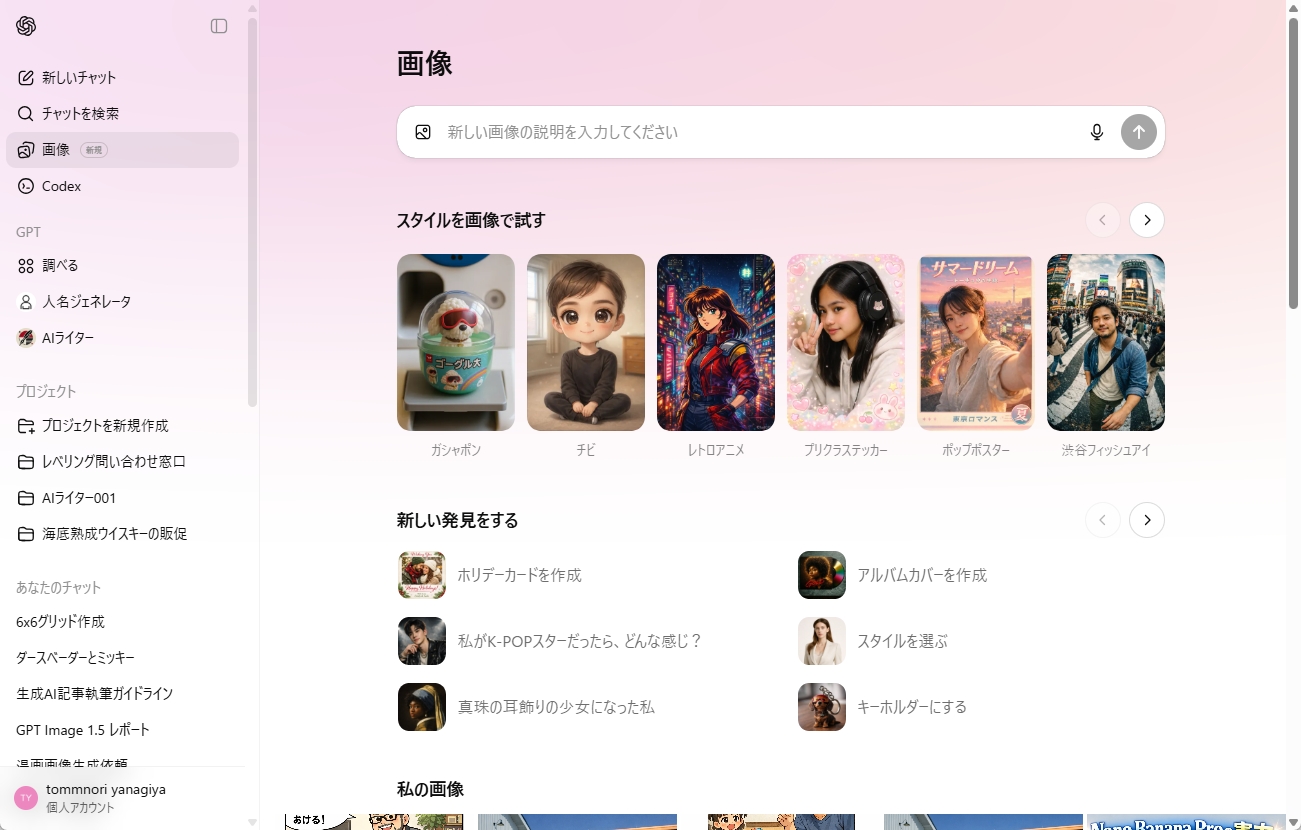
「画像」タブから「ガシャポン」をクリックしてみましょう。
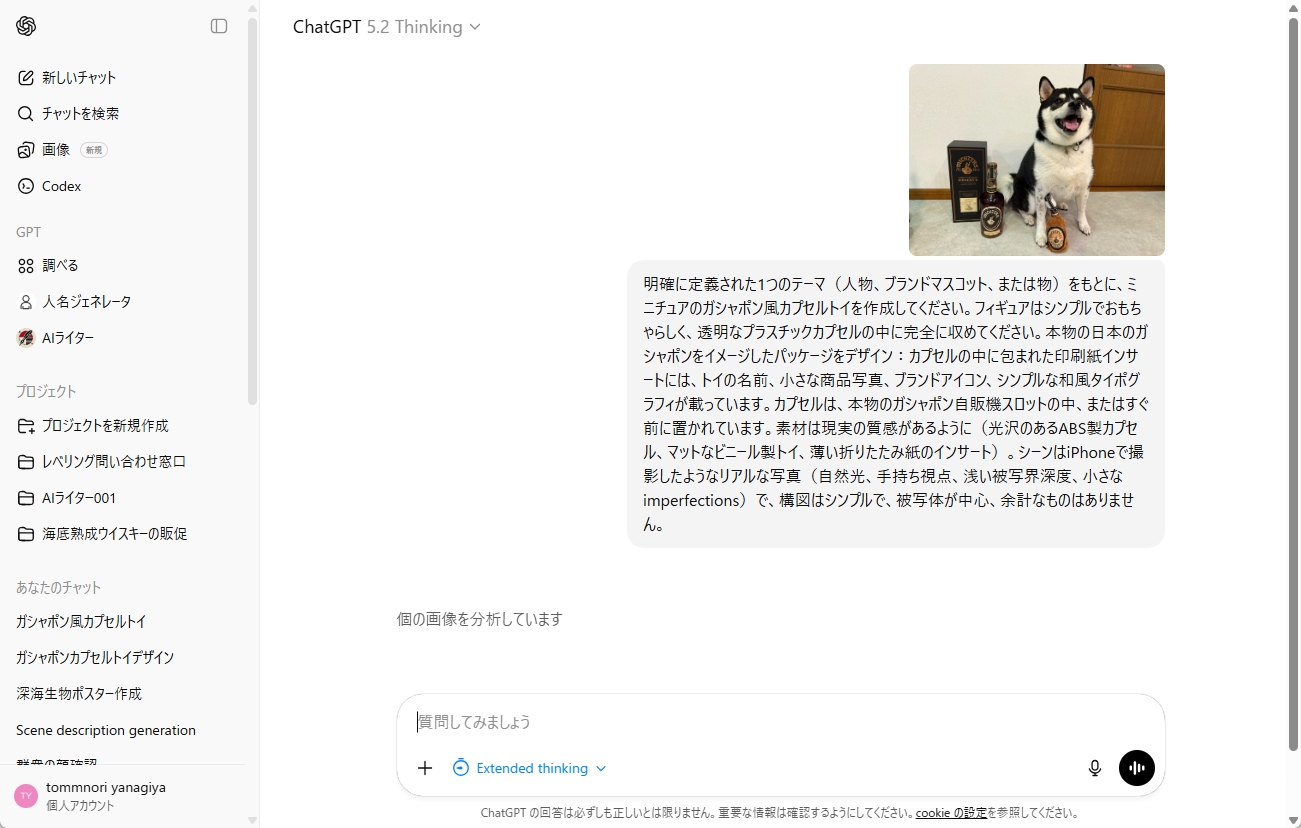
画像を指定すると、プリセットされたプロンプトとともに入力されます。

被写体がカプセルトイになりました。
いろいろと人物を変換する項目が用意されていたので、僕の写真で試してみました。プロンプトを相当細かく記述しても、高いレベルで追従していることがわかります。ただし、やはり漢字の表現は苦手なようです。



左から、渋谷フィッシュアイ、ポップスター、レトロアニメです。
画像編集も得意です。出力が気に入らなければ、何度でも修正指示を出し、狙った画像に仕上げられます。ガチャを回さなくてもいいので、手間が省けますし、クオリティも上げやすいです。
僕の好きな映画のワンシーンを想像し、プロンプトだけで近づけてみることにします。まずは、基本となる画像が生成されたら、修正したいポイントを日本語の自然文で指示するだけです。
あまり複雑な指示だと失敗することもありますが、複数の修正をお願いしてもきちんと対応してくれることが多いです。こちらの意図を汲んで、いい感じにしてもらえるので、どんどん完成形に近づいていくのが楽しかったです。この画像、何の映画のシーンを目指したかわかりますか?

●プロンプト:左の男性は白人で何かを指さしています。右の男性が被っているのは鉢巻で、カウンターに両手をついています。路上に面した店で、画面左側は屋外です。
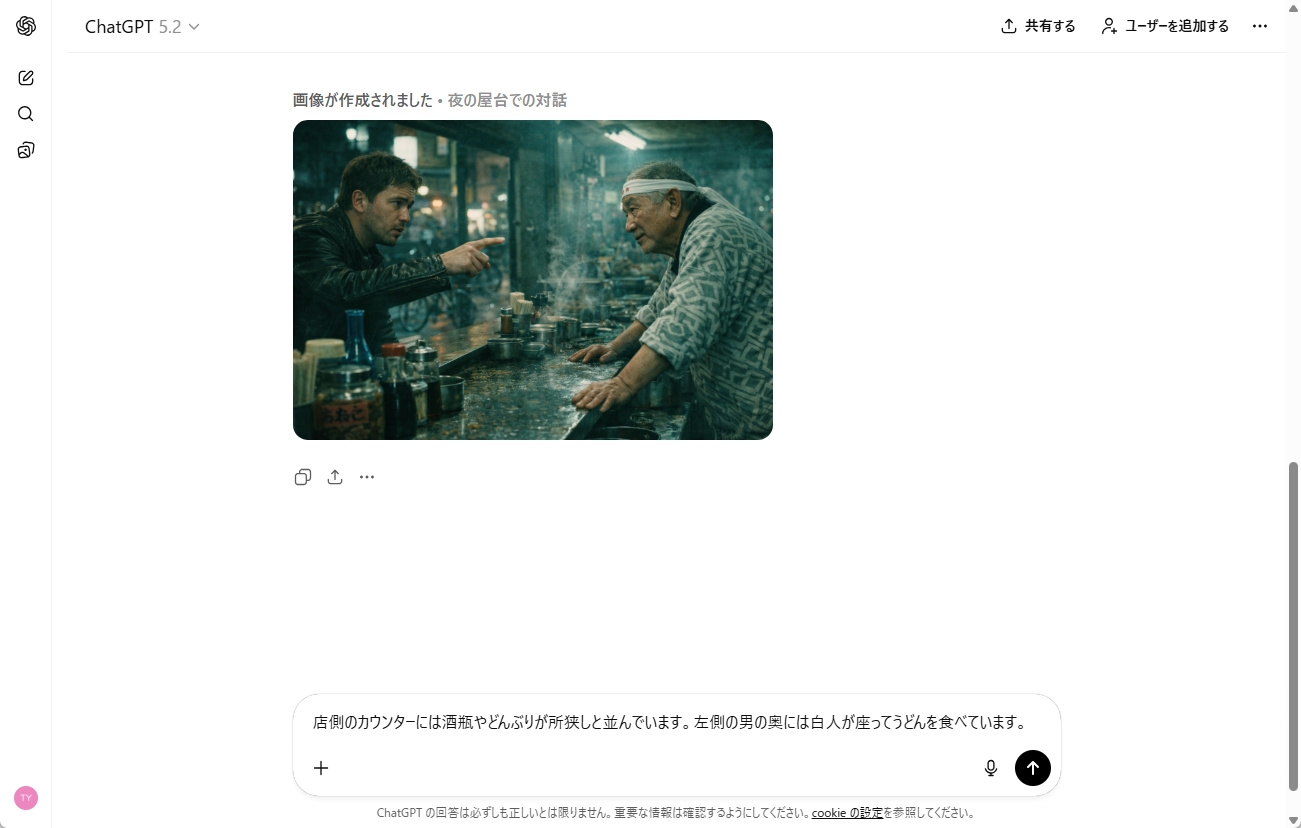
●プロンプト:店側のカウンターには酒瓶やどんぶりが所狭しと並んでいます。左側の男の奥には白人が座ってうどんを食べています。

数回修正を指示したところ、頭の中にある画像が生成できました。
OpenAIのウェブサイトにサンプルプロンプトが公開されていたので、いくつか日本語に訳して生成してみました。確かに、表現力は格段に向上しています。特に、多数の人物・物体を表現する際に破綻していないのがすごいです。
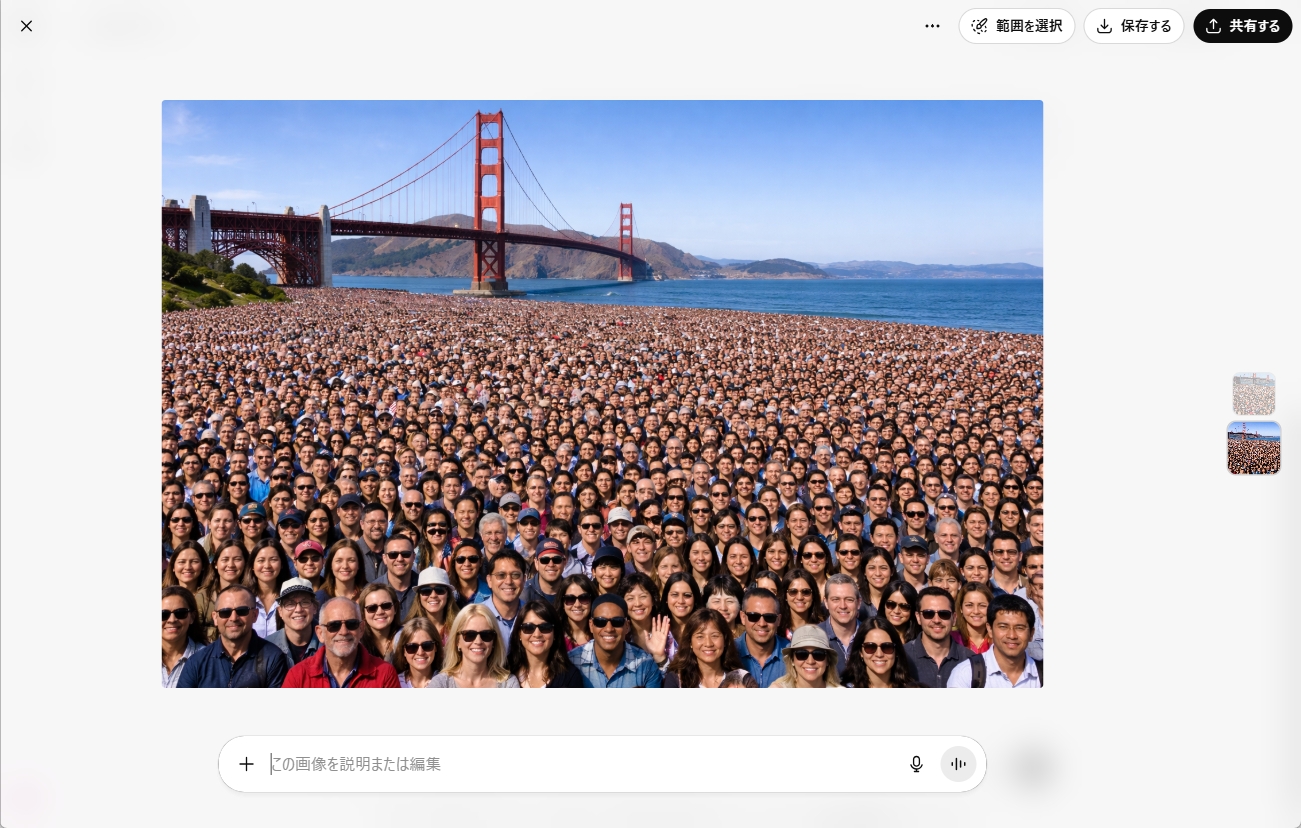
●プロンプト:ゴールデンゲートブリッジの前には数万人の群衆が集まっています。群衆全員の顔がはっきりと見えるようにしなければなりません。横長の画像を生成してください。
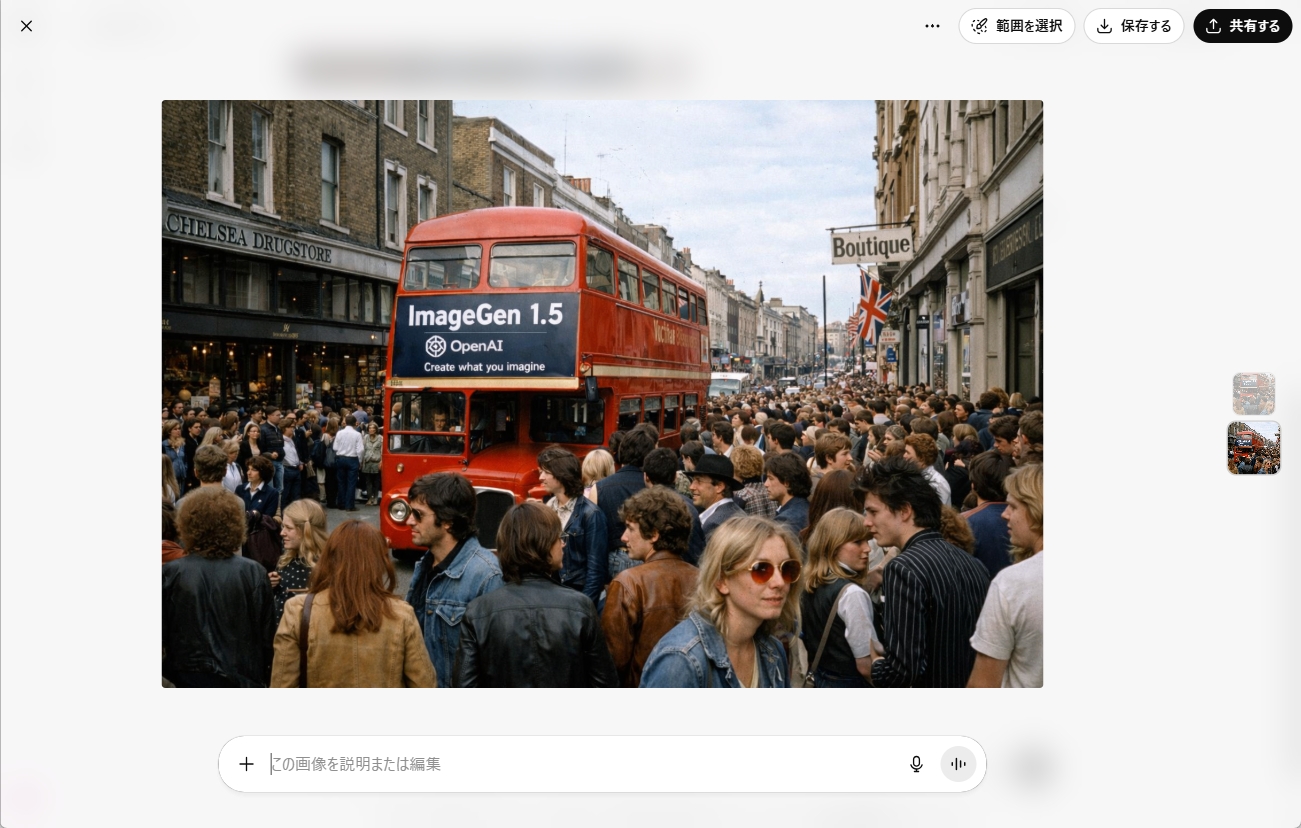
●プロンプト:1970年代のロンドン、チェルシーの風景を、フォトリアリスティックに、すべてに焦点を合わせ、たくさんの人々、そしてOpenAIのロゴと「Create what you imagine」というサブタイトルが付いた「ImageGen 1.5」の広告を掲げたバスで撮影してください。超リアルなアマチュア写真、iPhoneのスナップショット品質…

●プロンプト:深海生物のポスターを作成し、縦方向の海を描き、日本の美しいアニメスタイルで表現しましょう
以前レビューしたNano Banana Proと同じ条件で生成してみた
以前、本連載でNano Banana Proのレビューを紹介した時に使ったプロンプトをGPT-Image-1.5に入れて、出力を比較してみましょう。
まずは、写真を元にバナー画像を作ってもらいます。いい感じのデザインにしてくれた上、内容を表すアイコンまで用意してくれました。漢字が所々文字化けしていますが、ぱっと見は読めます。


左がGPT Image 1.5、右がNano Banana Pro
●プロンプト
■文字
最大14枚の画像参照
最大5人まで一貫性を保つ
スタジオ品質の編集機能
最大4K解像度
日本語の表現力もUP
リアルタイム情報もOK
記事の内容をグラレコ画像にしてもらうプロンプトは、そのままでは通りませんでした。まず、ChatGPTがURL先にアクセスして、画像の内容をプロンプト化して出力してきました。そのため、ChatGPTでは「生成して」と追加で指示を出す必要がありました。
出力はポップなフォントですが、いい感じにまとまっています。ただし、こちらも漢字が変ですね。また、Nano Banana Proに比べると情報量が少ないです。
左がGPT Image 1.5、右がNano Banana Pro
●プロンプト
https://tenbin.ai/media/ai_news/ai-mirror-neuron
僕と星川アイナさんの写真、そして建物の写真をアップロードし、合成してもらいました。出力はとてもいい感じなのですが、拡大するとつないでいる手の描写に違和感があります。Nano Banana Proも完璧ではなかったので、ここは互角です。


左がGPT Image 1.5、右がNano Banana Pro
●プロンプト
漫画も描写できました。日本語の表現はやはり無理ですね。ただし、指示は理解しているようで、絵は描けています。参照画像もアップロードしてみましたが、パパ役以外はほとんど似ていません。こちらも、Nano Banana Proの方が向いていそうです。


左がGPT Image 1.5、右がNano Banana Pro
●プロンプト
登場人物:30代日本人男性、3歳女の子
① パパの言うことは聞かないのに、ママの同じ指示は即実行
1コマ: パパ「そろそろお片付けしよ〜」
2コマ: 娘「いやっ!!まだやるの!!」
3コマ: ママ「片付けるよ〜」
4コマ: 娘「はーい!」(パパだけ呆然)


左がGPT Image 1.5、右がNano Banana Pro
●プロンプト(参照画像あり)
タイトル、黒文字ゴシック
ヘアアレンジに挑戦
内容
1コマ: パパ「今日はパパが髪むすんであげる!」
2コマ: 娘「わーい!」
3コマ: ぐしゃぐしゃの団子が頭に2つ
4コマ: ママ「…それで行くの?」(パパドヤ顔)
今すぐ最大6つのAIを比較検証して、最適なモデルを見つけよう!
確実な進化を遂げているもののライバルを圧倒するにはまだ課題が残る
GPT Image 1.5は、4倍の生成速度、論理的なプロンプト理解、そして精密な編集機能など、GPT-Image-1よりもさらに進化しています。もちろん、これはゴールではありません。動画生成AI「Sora」との統合も確実視されており、静止画で確立した制御技術は、そのまま動画におけるフレーム間の一貫性へと応用されていくはずです。
しかし、Nano Banana Proという強力なライバルを追い抜いたとは言い難いところがあります。本来であれば、次世代の「GPT-Image-2」を出す予定が、コード・レッドにより大幅に前倒しになったのかもしれません。いちユーザーとしては、競争により凄いツールが早く登場するならウェルカムです。ぜひ、Nano Bananaの最新バージョンが出る前に、日本語が完ぺきな「GPT-Image-2」を出して欲しいところですね。
この記事の監修

柳谷智宣(Yanagiya Tomonori)監修
ITライターとして1998年から活動し、2022年からはAI領域に注力。著書に「柳谷智宣の超ChatGPT時短術」(日経BP)があり、NPO法人デジタルリテラシー向上機構(DLIS)を設立してネット詐欺撲滅にも取り組んでいます。第4次AIブームは日本の経済復活の一助になると考え、生成AI技術の活用法を中心に、初級者向けの情報発信を行っています。
