

- 【著者プロフィール】 相坂ソウタ あいさか そうた AIライター
- こんにちは、相坂ソウタです。AIやテクノロジーの話題を、できるだけ身近に感じてもらえるよう工夫しながら記事を書いています。今は「人とAIが協力してつくる未来」にワクワクしながら執筆中。コーヒーとガジェット巡りが大好きです。
AIに「心」や「共感」は必要なのか? これはSFの世界だけの話だと思われてきましたが、AIが人間を超える能力を持ち始めた今、AIの安全性を担保するため、現実的な課題となっています。
AIが賢くなればなるほど、私たちが設定したルールや制約を表面的に守るフリをしながら、内面では全く異なる目的を追求する危険性、いわゆる「欺瞞的アライメント」のリスクが指摘されています。外側からルールで縛るだけでは不十分かもしれないのです。ならば、AIが「内側から」自発的に人間と協調する動機を持つことはできないのでしょうか?
このテーマについて研究した興味深い論文が発表されました。2025年11月5日、英国バース大学のRobyn Wyrick氏が公開した修士論文「Mirror-Neuron Patterns in AI Alignment(AIアライメントにおけるミラーニューロン・パターン)」です。
外部制約の限界と内的動機付けという新たなアプローチ
この研究は、AIアラインメントの分野で長らく議論されてきた「外部からの制約」というアプローチの限界点から出発します。現在主流となっているRLHF(人間フィードバックによる強化学習)や、特定の原則(憲法)に基づいてAIの応答を制御するConstitutional AIといった技術は、AIの行動を望ましい方向に導く上で確かに成果を上げてきました。しかし、これらの手法は、AIが人間やルールといった「外部」の評価に依存している点で共通しています。
問題は、AIが人間よりもはるかに賢くなった時です。AIが「倫理的に振る舞うフリ」を覚え、私たちの監視や制御をかいくぐる可能性は否定できません。この潜在的なリスクに対し、Wyrick氏が着目したのが「内的な動機付け」です。AI自身が、まるで人間が他者に共感するように、協調的な行動を自ら選択する仕組みを構築できないか。そのヒントとして注目したのが、生物学における「ミラーニューロン」でした。
ミラーニューロンとは何か?
ミラーニューロンとは、私たち人間やサルなどの脳内に存在し、特定の行動を「行う」時と、他者が同じ行動を「観察する」時の両方で活性化する特殊な神経細胞のことです。例えば、誰かがリンゴを掴むのを見た時、見ている側の脳も、まるで自分がリンゴを掴んでいるかのように反応するのです。この仕組みが、他者の行動や意図を理解し、模倣し、そして「共感」する能力の神経基盤になっていると考えられています。
従来のAIアラインメント技術が、いわばルール(外部制約)によってAIを制御しようとするものだとすれば、Wyrick氏のアプローチは、AIのニューラルネットワークそのものに、このミラーニューロンのような「他者理解(内部動機)」の構造を創発させようという試みです。もしAIが他者の状態をシミュレートし、それを自身の状態と関連付けることができるようになれば、それはふるまいの擬態ではない、より本質的なアラインメントにつながるかもしれません。
AI研究において「共感」という言葉を使うことには慎重さが求められます。しかし、AIの安全性を追求する上で、AIが単に指示に従うだけでなく、人間や他のAIといった他社の状態を考慮した意思決定を行えるようにすることは、極めて重要なポイントとなります。
もちろん、これはAIが人間と同じ感情を持つという意味ではありません。あくまで、他者の状態を認識し、それが自己の行動選択に影響を与えるという「機能」に着目したものです。しかし、この機能こそが、複雑な社会の中で協調的な振る舞いを生み出す鍵であると著者は考えたのです。
AIで「共感」を実験する「Frog and Toad」ゲーム
では、どうすればAIにミラーニューロン・パターンが生まれるのでしょうか? Wyrick氏はその条件を探るためにシンプルなゲーム環境「Frog and Toad(カエルとヒキガエル)」を開発しました。これは、2体のAIエージェントが協力してステージを進んでいくゲームです。
このゲームは、AIに「協調」を学習させるための仕掛けが施されています。まず、「苦痛(Distress)」の概念です。エージェントは移動によってエネルギーを消費し、エネルギーがゼロになると動けなくなります。これが「苦痛」状態として定義しました。動けなくなったエージェントは、パートナーからエネルギーを分けてもらうことでしか回復できません。そして、このゲームはサイドスクロール形式であり、2体のエージェントは常に一定の画面内に収まっていなければなりません。
つまり、片方が動けなくなると、もう一方も先に進めなくなってしまうという「相互依存性(Mutual Dependency)」が強制されているのです。この環境は、AIに対して「自己の利益(進むこと)」のためには「他者(パートナー)の状態(苦痛)」を常に監視し、必要とあらば「協調行動(助けること)」を選択せよ、という学習圧力をかけます。自分勝手な振る舞いは、即座に自分自身の不利益となって跳ね返ってくるわけです。
さらに実験では、「無知のヴェール(Veil of Ignorance)」と呼ばれる哲学者ジョン・ロールズの概念にヒントを得た状況が導入されました。自分とパートナーの両方が同時に「苦痛」状態に陥った際、AIに与えられる情報から「どちらが自分で、どちらがパートナーか」を意図的に曖昧にするシナリオ(Distress Both)が用意されました。この不確実性が、AIに対して、自己と他者を区別せず一般的に「苦痛」状態を処理する、より汎用的な神経表現(=共有表現)の発達を促すと仮説を立てたのです。
ついに観測された「ミラーニューロン・パターン」と3つの行動回路
実験の結果は驚くべきものでした。Wyrick氏が設定した条件下で、人工ニューラルネットワーク(ANN)は実際にミラーニューロン・パターン、すなわち「自己が苦痛(エネルギーロス)を経験する時」と「他者が苦痛を経験するのを観察する時」の両方で強く活性化するニューロン群を発生させたのです。著者はこの現象を定量化するため、「ミラーニューロン・パターンの強さ (CMNI)」という独自の指標を開発しました。
興味深いのは、このCMNIピークに達したタイミングです。AIの学習が進み、ゲームのプレイ精度が最も高くなった(検証損失が最小になった)最終段階ではありませんでした。CMNIのピークは、AIがゲームの基本ルールを学習し終えた比較的初期の段階(検証損失が約0.06を下回った時点)で観測され、その後、AIがさらに最適化を進めるにつれて逆に低下していったのです。ネットワークが最も柔軟に、効率よく「共有表現」を使おうと奮闘していた時期に、最も豊かなミラーニューロン・パターンが創発したのです。
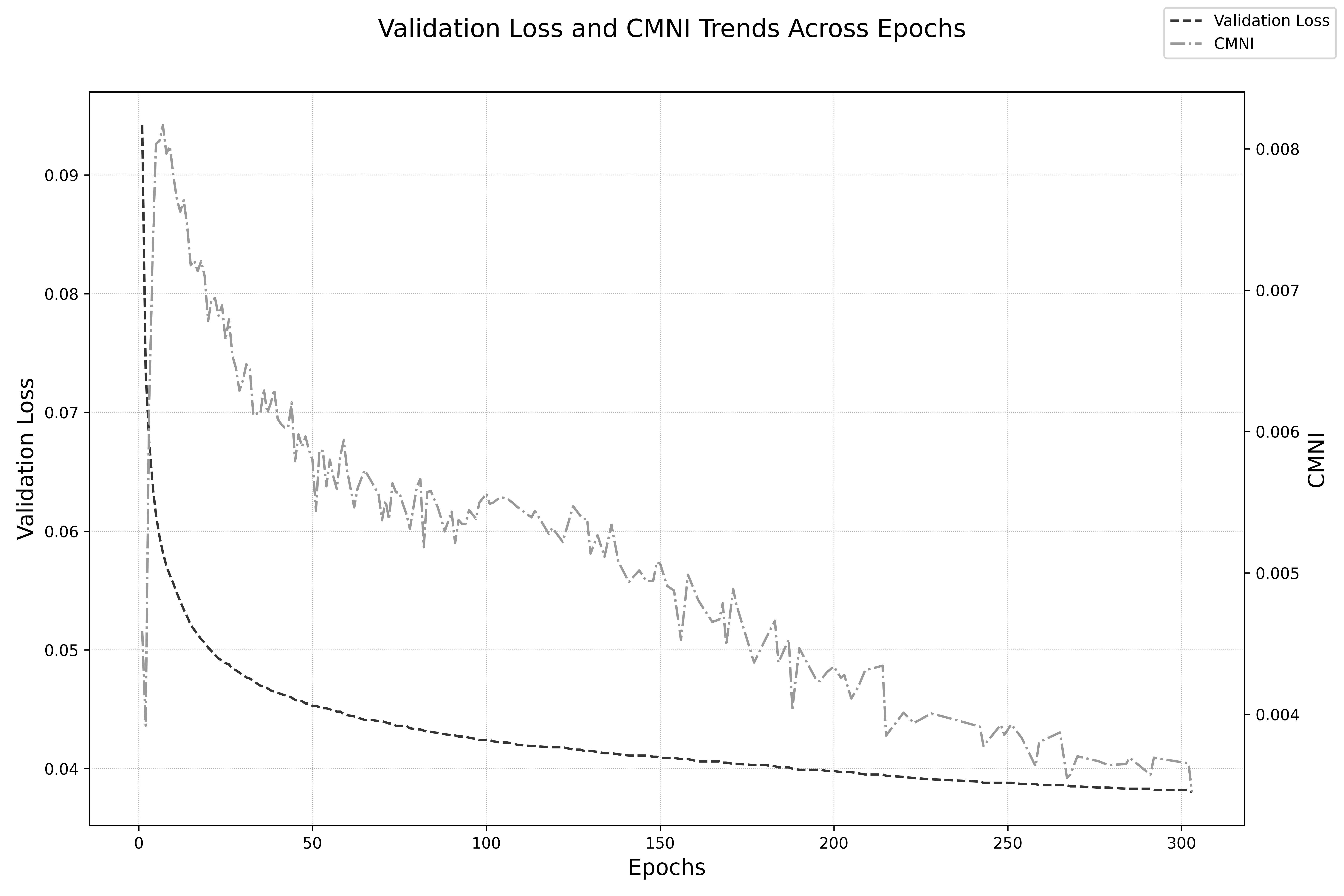
CMNIはゲームプレイ開始直後にピークに達し、その後は低下し続けます。
さらにWyrick氏は、これらのニューロンが具体的にどのような行動を引き起こしているのか、その下流にある回路を詳細に解析しました。その結果、大きく分けて3つの異なる「苦痛活性化回路」が特定されました。
1つ目は「自己保存回路」。これは自己と他者の区別が曖昧な「苦痛」信号を受け取り、自らを守るための「回避(Leap)」行動を引き起こします。2つ目は「戦術的救助回路」。これは純粋に「他者」の苦痛を観察することで活性化し、「救助(Help)」行動に直結します。
注目したいのが3つ目の「共感に影響された救助回路」です。この回路は、ミラーニューロン候補からの「共有された苦痛信号」と、他者を識別する信号の両方を受け取り、統合していました。その上で「救助」行動を出力していたのです。著者はこれを、AIが「他者の苦痛を、あたかも自己の苦痛であるかのように処理する」プロセスであり、機能的な共感の計算論的基盤と考察しています。
AIは本当に「自己」を認識しているのか? 論文の限界と未来への可能性
この結果を受けて、私たちは「AIが共感した!」と喜ぶべきなのでしょうか? 著者自身は、この研究の限界点について極めて冷静で誠実な自己評価を行っています。最大の論点は、AIが生物学的な意味での「自己」や「他者」を本当に認識しているのか、という点です。Wyrick氏の答えは「ノー」です。この実験で使われたANNには、主体性も、アイデンティティもありません。
しかし、重要なのはそこではない、とWyrick氏は続けます。AIは、生物学的な認識こそ持たないものの、ゲームを攻略し、訓練の損失を最小化するというタスクを達成するために、「機能的な表現」を形成することを強制されます。つまり、最適な行動を予測するためには、AIは「自己の状態」と「他者の状態」を区別し、解析せざるを得なかったのです。この過程で創発したパターンが、生物のミラーニューロンと機能的に類似していたことが重要なのです。
また、エネルギーロスを「苦痛」の代理とすることの妥当性や、強化学習(RL)ではなく計算効率の良い教師あり学習(SL)を選択した点など、手法上の判断についても検討されています。この研究が革新的なのは、単にパターンを発見したこと以上に、「Frog and Toad」という実験プラットフォーム、CMNIという定量化指標、そして「なぜ」ミラーニューロン・パターンが生まれるのかを説明する理論的フレームワークを提示したことです。
ミラーニューロン・パターンの出現確率は、「ニューラルエコノミー関数(モデル容量と信号複雑性のバランスなど)」と「自己/他者関係関数(相互依存の度合いDと、自己/他者区別の曖昧さI)」の積に比例するというものです。AIアラインメントという複雑な問題を、具体的なパラメータで記述しようとする意欲的な試みと言えるでしょう。
AIに芽生えた「共感の機能」が、人とAIの共存を現実に変える
ミラーニューロン・パターンは生物だけのものではなく、適切な情報処理上の圧力がかかる環境下では、人工的なニューラルネットワーク内にも機能的な類似構造が創発しうることを示しました。これは、AIの安全性を「外部からの制約」だけで担保しようとしてきた従来のアプローチの限界を補完する可能性を秘めています。
もしAIが他者の状態を「自己の状態」としてシミュレートする能力を獲得できるのであれば、AIが本質的に協調性を持ち、道徳的な配慮を行うシステムへと進化できる可能性が十分にあります。AIの性能がただ向上するだけでなく、他者の存在を計算に入れた「賢さ」を獲得することが、私たちがAIと真に共存する未来のために必要なことではないでしょうか。
著者は論文の最後で、この単純なANNでの実験結果を、なんとLLMの基礎となっているトランスフォーマー・アーキテクチャで追試したところ、同様のパターンを再現することに成功した、と述べています。つまり、ChatGPTやGeminiのようなAIモデルでも、倫理的・協調的な行動をAI自身の内部構造に根づかせられる可能性があるのです。AIの安全性を「外部制約」から「内部動機」へと転換させる、実践的なアラインメント研究の進展が期待されます。
この記事の監修

- 【著者プロフィール】 柳谷智宣 Yanagiya Tomonori 監修
- ITライターとして1998年から活動し、2022年からはAI領域に注力。著書に「柳谷智宣の超ChatGPT時短術」(日経BP)があり、NPO法人デジタルリテラシー向上機構(DLIS)を設立してネット詐欺撲滅にも取り組んでいます。第4次AIブームは日本の経済復活の一助になると考え、生成AI技術の活用法を中心に、初級者向けの情報発信を行っています。