

- 【著者プロフィール】 相坂ソウタ あいさか そうた AIライター
- こんにちは、相坂ソウタです。AIやテクノロジーの話題を、できるだけ身近に感じてもらえるよう工夫しながら記事を書いています。今は「人とAIが協力してつくる未来」にワクワクしながら執筆中。コーヒーとガジェット巡りが大好きです。

- 【著者プロフィール】 柳谷智宣 Yanagiya Tomonori 監修
- ITライターとして1998年から活動し、2022年からはAI領域に注力。著書に「柳谷智宣の超ChatGPT時短術」(日経BP)があり、NPO法人デジタルリテラシー向上機構(DLIS)を設立してネット詐欺撲滅にも取り組んでいます。第4次AIブームは日本の経済復活の一助になると考え、生成AI技術の活用法を中心に、初級者向けの情報発信を行っています。
📌 この記事の要約
-
Slackログから専門知識を推定する研究 2026年5月に公開された論文は、Slackの会話ログから「誰が何を知っているか」をLLMで推定できるかを検証しています。
-
27,188件のメッセージを7モデルで比較 43ユーザー、94チャンネル、27,188件のSlackログを使い、27人の自己評価とAIの推定結果を比較しました。
-
最小誤差はGemini 2.5 Flash Gemini 2.5 FlashはMAE 21.13で最も誤差が小さく、メッセージ量だけでは精度が決まらないことも示されました。
-
職場では「専門家探し」の補助が現実的 人事評価ではなく、詳しい人へたどり着くための案内板として使うなら有望ですが、プライバシー保護が大きな課題です。
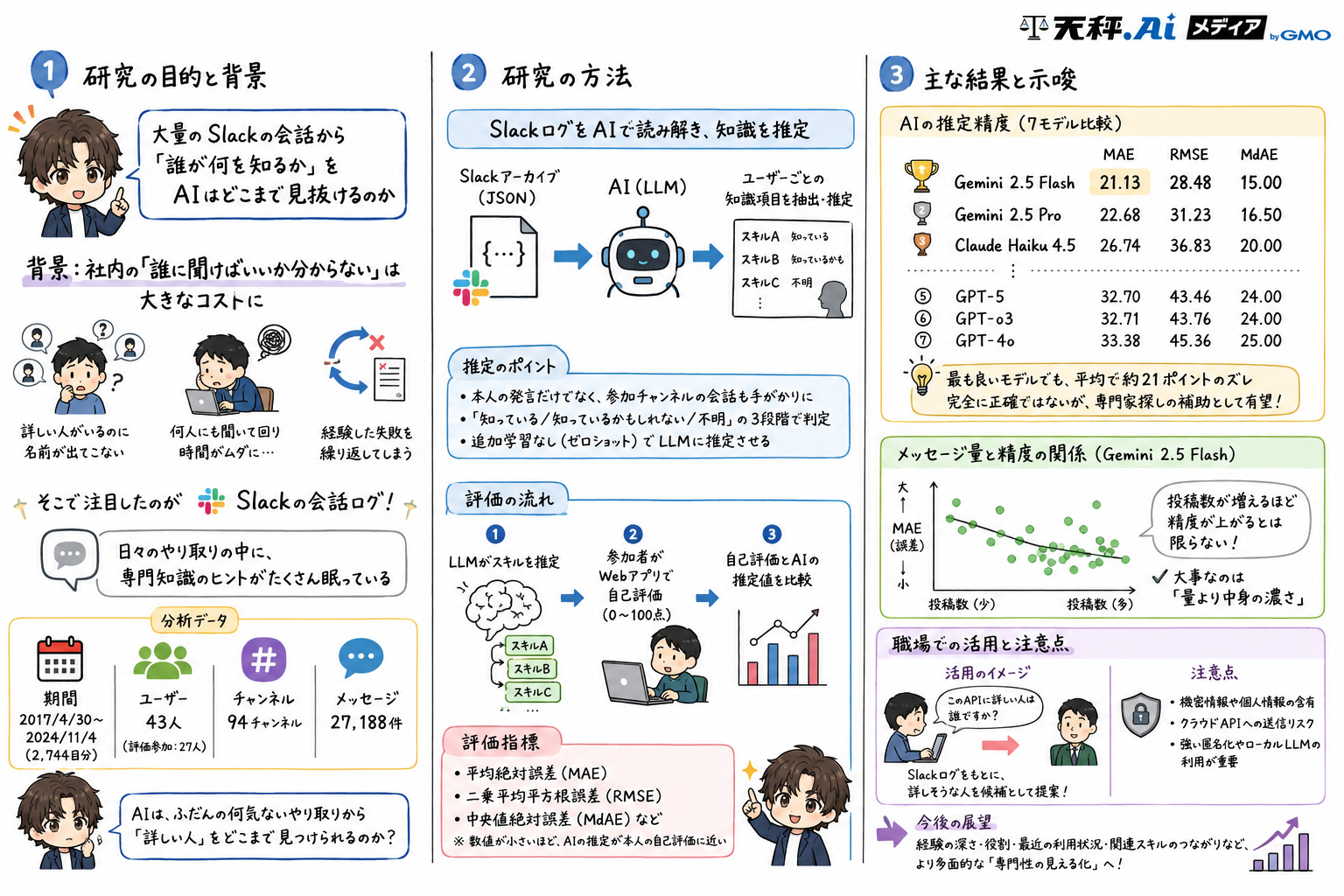
2026年5月21日にarXivで公開された論文「AIはあなたが何を知っているかを推測できるのか? コミュニケーションログから人の専門知識を推定する大規模言語モデルの性能比較(Can AI Guess What You Know? Performance Comparison of Large Language Models for Human Domain Knowledge Estimation From Communication Logs)」は、Slackの会話ログから「誰が何を知っているか」を大規模言語モデル(LLM)で推定できるかを調べた研究です。著者はDFKIのKo Watanabe氏と、大阪公立大学のShoya Ishimaru氏です。
社内で仕事をしていると、「この件、誰に聞けばいいんだろう」と手が止まることがあります。詳しい人はいるはずなのに、名前が出てこない。新入社員や異動したばかりのメンバーなら、なおさらです。研究チームは、この見えにくい社内知識を、日々のSlackログから推定できないかと考えました。分析対象は、2017年4月30日から2024年11月4日までの2,744日分、計27,188件のSlackメッセージです。AIは、ふだんの何気ないやり取りから「詳しい人」をどこまで見つけられるのでしょうか。
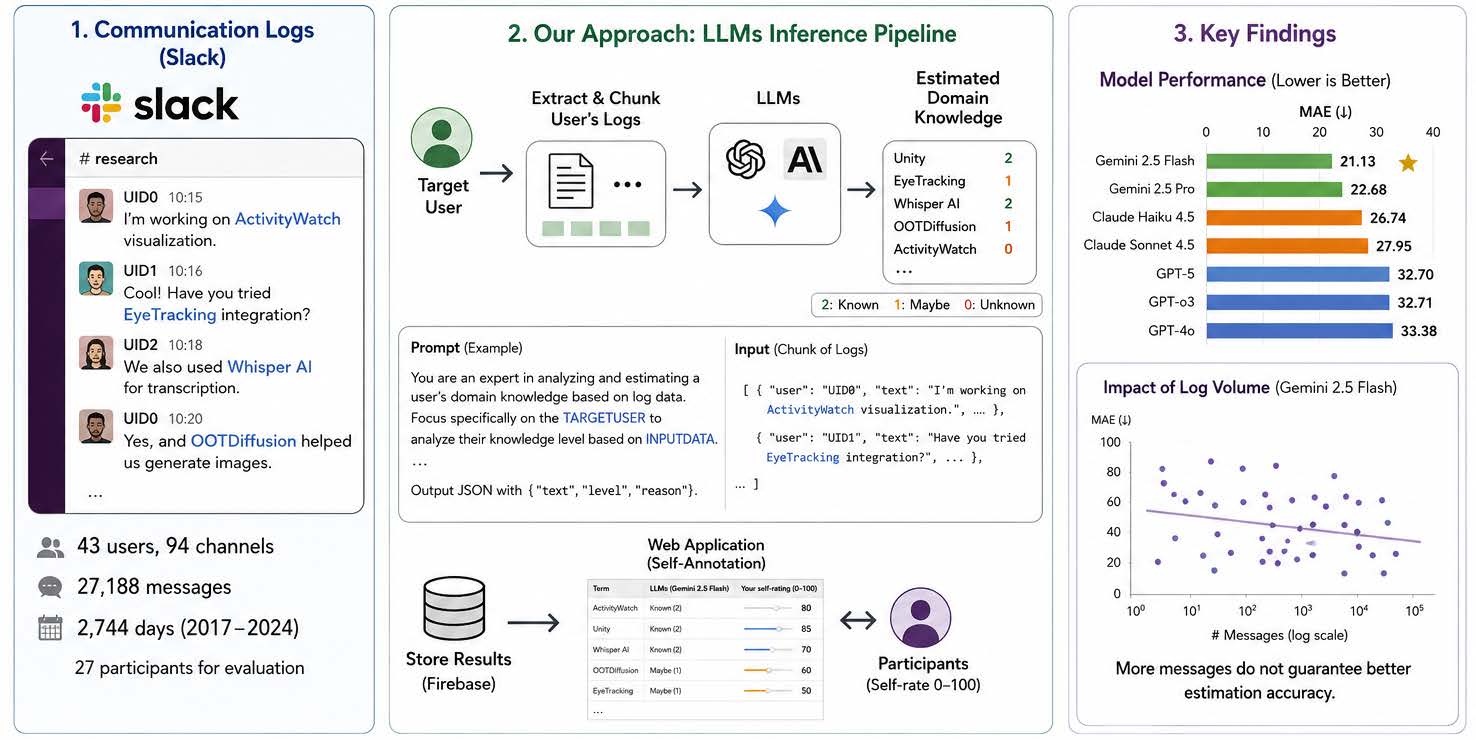 Slackの会話ログをLLMに読み込ませ、各ユーザーの知識項目を推定して可視化する研究の全体像です。画像は論文より。
Slackの会話ログをLLMに読み込ませ、各ユーザーの知識項目を推定して可視化する研究の全体像です。画像は論文より。
社内の「誰に聞けばいいか分からない」は意外に大きなコスト
組織の中には、ドキュメントに書かれていない知識がたくさんあります。過去のプロジェクトで使ったライブラリの癖や特定の顧客とのやり取り、研究室なら実験装置の扱い方や論文投稿の勘所などです。本人にとっては当たり前でも、周囲からは見えません。
こうした「誰が何を知っているか」が分からない状態は、仕事の小さな詰まりの原因になります。新人が詳しい人を探して何人にも聞いて回ったり、別のチームが、すでに誰かが経験した失敗を繰り返したりしていると、1回ごとは地味でも、組織全体で見ると見逃せない浪費時間になります。
そこで研究チームが注目したのが、Slackのような日常的なコミュニケーションログです。社内チャットには、質問や回答、作業報告、技術メモ、URL共有、雑談が混ざっています。すべてが専門知識を表すわけではありません。それでも、長期間のログをたどると、ある人がUnityやUnreal Engine、Whisper AI、EyeTrackingといった言葉にどれくらい触れているか、どんな文脈で話しているかが見えてきます。
人間が数万件のログを読み込んで、全員の知識を整理するのは現実的ではありません。そこでLLMの出番です。今回の研究では、43ユーザー、94チャンネル、27,188件のSlackログを使い、そのうち連絡が取れた27人が評価に参加しました。ユーザーごとの投稿数には大きな差があり、最多は10,819件、最少は3件。平均は792件、中央値は208件でした。発言が多い人ほど、AIは正確に知識を推定できるのか。この点も検証しています。
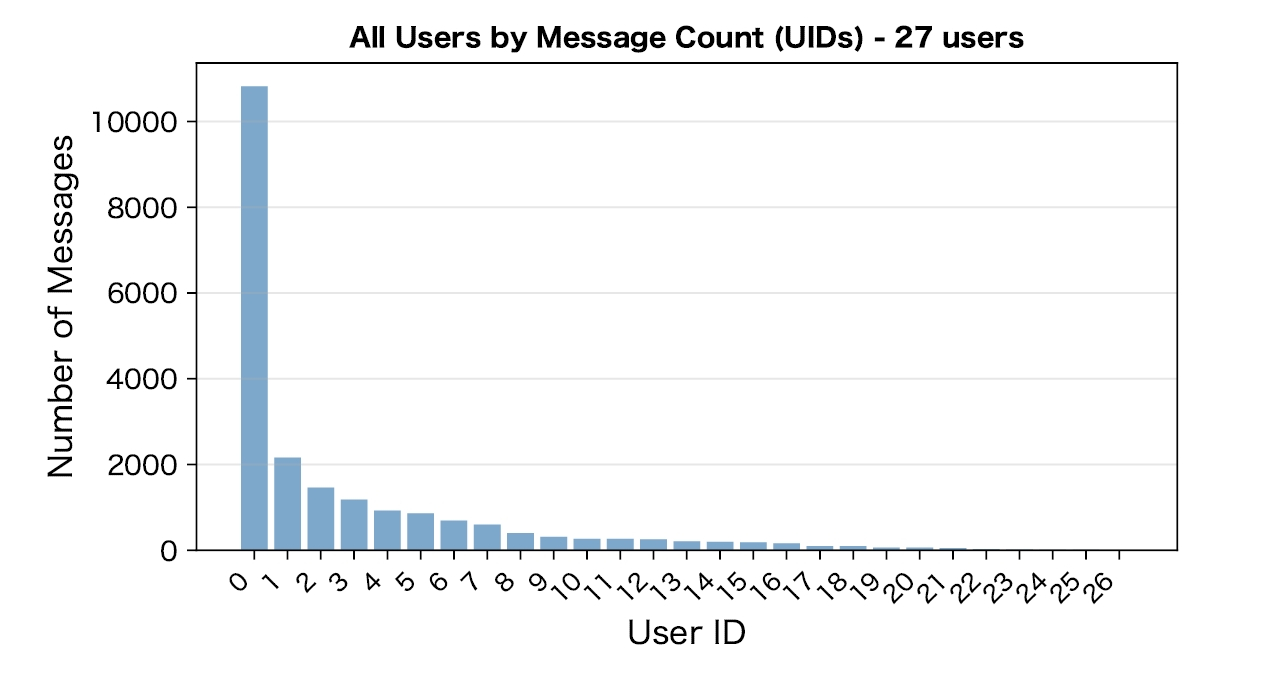 27人の参加者ごとのSlack投稿数です。ユーザーによってログ量が大きく違うことが分かります。
27人の参加者ごとのSlack投稿数です。ユーザーによってログ量が大きく違うことが分かります。
LLMは発言だけでなく参加チャンネルも手がかりに
実験では、まずSlackのアーカイブをJSON形式で取り出し、ユーザーごと、チャンネルごとにログを整理しました。そのうえでLLMにログを読ませ、対象ユーザーに関係するスキルや技術用語、分野名、概念名などを抽出させます。さらに、それぞれの項目について「知っている」「知っているかもしれない」「不明」の3段階で判定し、理由も出力させました。
この研究で面白いのは、本人の発言だけを見ていないところです。Slackには「このユーザーがチャンネルに参加した」というシステムメッセージも残ります。研究チームは、ユーザーが参加していたチャンネルでどんな会話が行われていたかも、知識推定の材料にしました。
自分ではあまり発言していなくても、特定の技術議論を長く追っていれば、ある程度の知識を持っているかもしれません。一方で、名前だけ出てきたからといって、本人が内容を理解しているとは限りません。この曖昧な部分を、追加学習なしのゼロショットでLLMに推定させています。
評価に使われたモデルは、Claude Haiku 4.5、Claude Sonnet 4.5、Gemini 2.5 Flash、Gemini 2.5 Pro、GPT-4o、GPT-o3、GPT-5の7種類です。各モデルはSlackログからスキル項目を抽出し、知識レベルを推定しました。
その後、参加者本人が専用のWebアプリにログインし、表示されたスキル項目について0から100まで、5刻みで自己評価しました。画面にはLLMの推定値を表示していません。AIの評価を先に見せると、本人の回答が引っ張られる可能性があるためです。
評価では、平均絶対誤差(MAE)、二乗平均平方根誤差(RMSE)、中央値絶対誤差などが使われました。簡単に言えば、本人の自己評価とAIの推定値がどれくらいズレたかを見る指標です。0から100のスケールなので、MAEが20なら、平均して20ポイント前後ズレているという読み方になります。
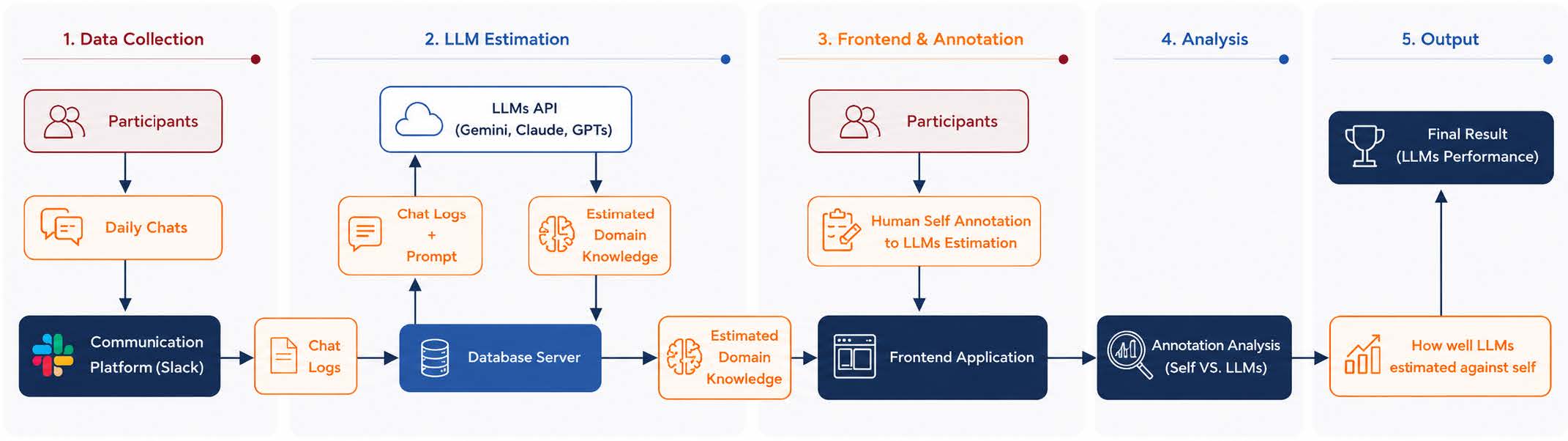 SlackログをJSON形式で取り出し、LLMで知識項目を抽出したあと、参加者がWebアプリで自己評価するまでの流れです。
SlackログをJSON形式で取り出し、LLMで知識項目を抽出したあと、参加者がWebアプリで自己評価するまでの流れです。
Gemini 2.5 Flashが最小誤差、ただし専門性の断定にはまだ粗さも
結果を見ると、最も誤差が小さかったのはGemini 2.5 Flashでした。MAEは21.13、RMSEは28.48、中央値絶対誤差は15.00です。本人の自己評価と比べて、平均で約21ポイントずれた計算になります。
Gemini 2.5 Proも近い成績で、MAEは22.68、RMSEは31.23、中央値絶対誤差は16.50でした。Claude Haiku 4.5はMAE 26.74、Claude Sonnet 4.5は27.95です。GPT系は、GPT-5が32.70、GPT-o3が32.71、GPT-4oが33.38でした。今回の条件では、Gemini系、Claude系、GPT系の順に誤差が小さいという結果です。
ただし、この数字を「AIが人の専門性を正確に分かった」と読むのは早計です。最もよかったモデルでも、平均で21ポイント前後のズレがあります。たとえば、ある人が自分のUnityスキルを80と答えたとき、AIが60前後と見ることもあります。逆に、本人より高く見積もるケースもあり得るため、人材配置や人事評価にそのまま使えるほど細かくはありません。
とはいえ、完全な当てずっぽうでもありません。Slackログだけを材料にして、本人の自己評価にある程度近いところまで推定できました。社内で「この話に詳しそうな人」を探す補助としては、十分に興味深い結果です。
もうひとつ注目したいのが、メッセージ量と精度の関係です。研究チームは、最も成績のよかったGemini 2.5 Flashを使い、ユーザーごとのMAEを比較しました。発言数が極端に少ないユーザーでは誤差が大きくなりやすい一方で、ログが増えれば増えるほど精度が安定して上がる、という結果にはなりませんでした。
Slackのログには、短い返事や日程調整、雑談、確認のように、専門知識をほとんど含まない文章も多く含まれます。「了解です」「あとで見ます」「会議を移動しました」だけでは、専門知識はほとんど読み取れません。一方で、投稿数が少なくても、濃い技術説明やトラブルシュートが含まれていれば、AIにとっては強い手がかりになります。大事なのはログの量だけではなく、中身の濃さでした。
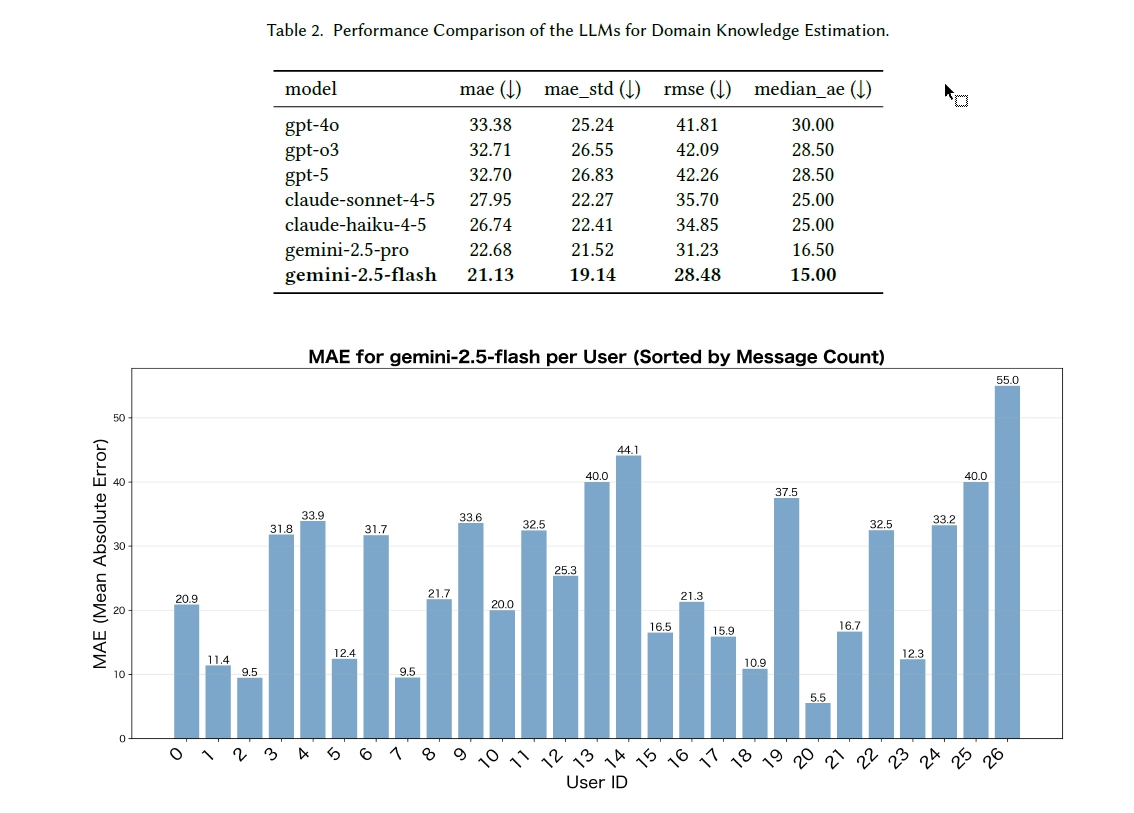 上の表は7モデルの誤差比較、下のグラフはGemini 2.5 Flashによるユーザー別MAEです。
上の表は7モデルの誤差比較、下のグラフはGemini 2.5 Flashによるユーザー別MAEです。
職場では専門家探しの補助ツールとして使うのが現実的
この技術はいろいろな場面で役立ちそうです。たとえば、新しく入った社員が「このAPIの仕様に詳しい人は誰ですか」と社内システムに尋ねる。するとシステムは、過去のSlack上のやり取りから作った知識プロフィールを参照し、関連する会話に参加していた人や、実際に回答していた人を候補として返します。本人がプロフィール欄にスキルを書かなくても、日々の会話から「この人はこの分野に触れている」と拾い上げるわけです。
これまでなら、詳しそうな同僚に聞き、そこからまた別の人を紹介してもらうしかありませんでした。もちろん、人づてに探す方法にも良さはあります。ただ、組織が大きくなるほど、知っている人にたどり着くまでの時間は増えていきます。Slackログから作った専門性マップがあれば、最初の相談先をある程度絞り込めます。人事評価に使うというより、社内の「誰に聞けばいいか」を探すための案内板として使うのが近いでしょう。
一方で、職場への導入には慎重さが必要です。今回の実験では、OpenAI、Claude、GeminiといったクラウドAPIにSlackログの一部を送っています。研究では参加者の同意を得ており、ユーザーIDの仮名化やメッセージ例の匿名化も行われています。それでも、企業の内部チャットには、機密情報や個人情報が含まれる可能性があります。顧客名や契約内容、未公開の研究、体調や人間関係に関する会話が混ざることもあるでしょう。AIで処理できるからといって、社内ログをそのまま外部サービスへ送る運用は危ういです。
実用化に向けて、研究チームはローカル環境や自社管理サーバーで動くLLM、より強い匿名化、メッセージの集約、元の文章を直接見せない中間表現の利用などを挙げています。社内チャットは機密情報や個人情報を含むため、ログをどう守りながら知識を活用するかが重要になります。逆に言えば、プライバシーを守る設計と組み合わせることで、社内に眠っている知識を安全に活用する道が見えてきます。
今後は、スキルを単語として抜き出すだけでなく、経験の深さや役割、最近の利用状況、関連スキルとのつながりまで扱えるようにすることが課題になります。Unityという言葉ひとつでも、チュートリアルを触った経験、商用プロダクトで使った経験、研究で活用した経験では意味が違います。こうした背景まで整理できるようになれば、「詳しそうな人」を探す精度はさらに高まるはずです。
今回の研究は会話の中に埋もれた知識をAIで見つけ出し、組織の中で共有しやすくする第一歩と言えます。人を評価するためではなく、必要なときに詳しい人へたどり着くための案内板として使う。そんな仕組みが実現すれば、Slackに流れていく日々の会話も、組織の知識資産として生かせるようになりそうです。
 Slackログを専門家探しに活用する際のポイントを整理した解説画像です。
Slackログを専門家探しに活用する際のポイントを整理した解説画像です。