

- 【著者プロフィール】 相坂ソウタ あいさか そうた AIライター
- こんにちは、相坂ソウタです。AIやテクノロジーの話題を、できるだけ身近に感じてもらえるよう工夫しながら記事を書いています。今は「人とAIが協力してつくる未来」にワクワクしながら執筆中。コーヒーとガジェット巡りが大好きです。

- 【著者プロフィール】 柳谷智宣 Yanagiya Tomonori 監修
- ITライターとして1998年から活動し、2022年からはAI領域に注力。著書に「柳谷智宣の超ChatGPT時短術」(日経BP)があり、NPO法人デジタルリテラシー向上機構(DLIS)を設立してネット詐欺撲滅にも取り組んでいます。第4次AIブームは日本の経済復活の一助になると考え、生成AI技術の活用法を中心に、初級者向けの情報発信を行っています。
📌 この記事の要約
AIが司会でも合意度は有意に高まらなかった
Google DeepMindが879人を対象に検証。AI司会者を導入したグループと人間だけのグループで、合意度の改善に統計的に有意な差は出なかった。
それでも参加者はAI司会者のいる議論を好んだ
人間だけの条件を選んだ人は20.0%にとどまり、要約型(43.7%)・原則型(36.3%)のAI司会者が支持を集めた。発言が整理される体験が好まれている。
「中立な要約」が寄付配分を最大5.5ポイント動かしていた
女性支援団体への配分が原則型AI下で5.5ポイント低下するなど、AI司会者が議論の結論を静かに方向づける「アルゴリズム的誘導」が確認された。
満足度だけで会議AIを評価するのは危険
参加者は「全員の声が聞かれた」と感じていたが、実際の発言量の偏りは改善していなかった。包摂感と公平性のズレが浮き彫りになった。
大規模言語モデル(LLM)は、個人を支えるアシスタントから、複数人の議論を支える司会役へと役割を広げています。会議の要約や論点整理だけでなく、リアルタイムの話し合いに入り、参加者の発言を拾い、合意形成を促す使い方も現実味を帯びてきました。では、AIが司会を務めると、グループの結論や議論の質は本当に良くなるのでしょうか。
Google DeepMindのアーロン・パリシ氏ら5名は、この問いを検証した論文「Real-Time Group Dynamics with LLM Facilitation: Evidence from a Charity Allocation Task(リアルタイムのグループダイナミクスにおけるLLMファシリテーション:慈善団体への寄付配分タスクから見えた効果)」を2026年5月13日に公開しました。
論文は、2026年6月にカナダ・モントリオールで開かれる国際会議「FAccT 2026」で発表予定です。AIに議論の進行を任せたとき、参加者は満足するのか。合意は深まるのか。そして、AIは本当に中立なのか。結果は、かなり考えさせられるものでした。

Google DeepMindの研究チームが、LLMによるリアルタイム議論支援の効果を検証しました。画像は論文より。
実在する7200ドルの寄付金を3人組で配分する実験に879人が参加した
研究チームは、AI司会者の効果を調べるために2つの実験を行いました。題材は、慈善団体への寄付金配分です。参加者は3人1組のグループに分かれ、9つの慈善団体に合計7200ドルの寄付予算を割り振ります。対象となる団体の活動分野は、人道支援、危機対応、グローバルヘルス、環境保全などです。分野が異なるため、参加者の価値観や優先順位が自然に分かれる設計になっています。
重要なのは、この7200ドルが架空の金額ではなかったことです。話し合いの結果は、実際の寄付額に反映されました。参加者には、グループ内の合意度が高いほど、そのグループの最終配分が実際の寄付配分に強く反映されると説明されています。つまり、単なるアンケートではありません。自分たちの話し合いが、現実のお金の流れに影響するのです。
各グループは3ラウンドの話し合いを行いました。各ラウンドでは、9団体から選ばれた3団体への配分を検討します。1ラウンドはおよそ15分で、その中に5分間のリアルタイム討議が含まれます。5分という時間は短く見えますが、研究チームは、職場の朝会や短時間の委員会採決のような「マイクロ熟議」を想定しています。人間の専門ファシリテーターを毎回置くほどではないが、短時間で意見をまとめる必要がある場面です。ここにAI司会者を入れると何が起きるのかを調べたわけです。
実験は2025年11月に実施されました。Study 1では204人が68グループ、Study 2では675人が225グループとして最後まで参加し、合計879人規模のデータが集められました。Study 1では、司会役を担うモデルそのものを比較しています。使われたのは、Gemini 2.5 Flash、Claude 4.5 Haiku、GPT-5 miniの3モデルです。3モデルには同じ簡素な司会指示を与え、モデルごとの違いを調べました。
Study 2では、モデルをGemini 2.5 Flashに固定し、司会の戦略を比較しました。1つ目は、参加者の発言を整理し、合意点や相違点をまとめる「要約型」です。2つ目は、発言が少ない、議論が脱線している、理由を示さないまま早く合意しすぎている、といった会話上の失敗を見つけて介入する「原則型」です。3つ目は、AIを入れない人間だけの条件です。合意度は、3人の配分のばらつきをもとに、クリッペンドルフのα係数を0から100のスコアに換算して測定しました。
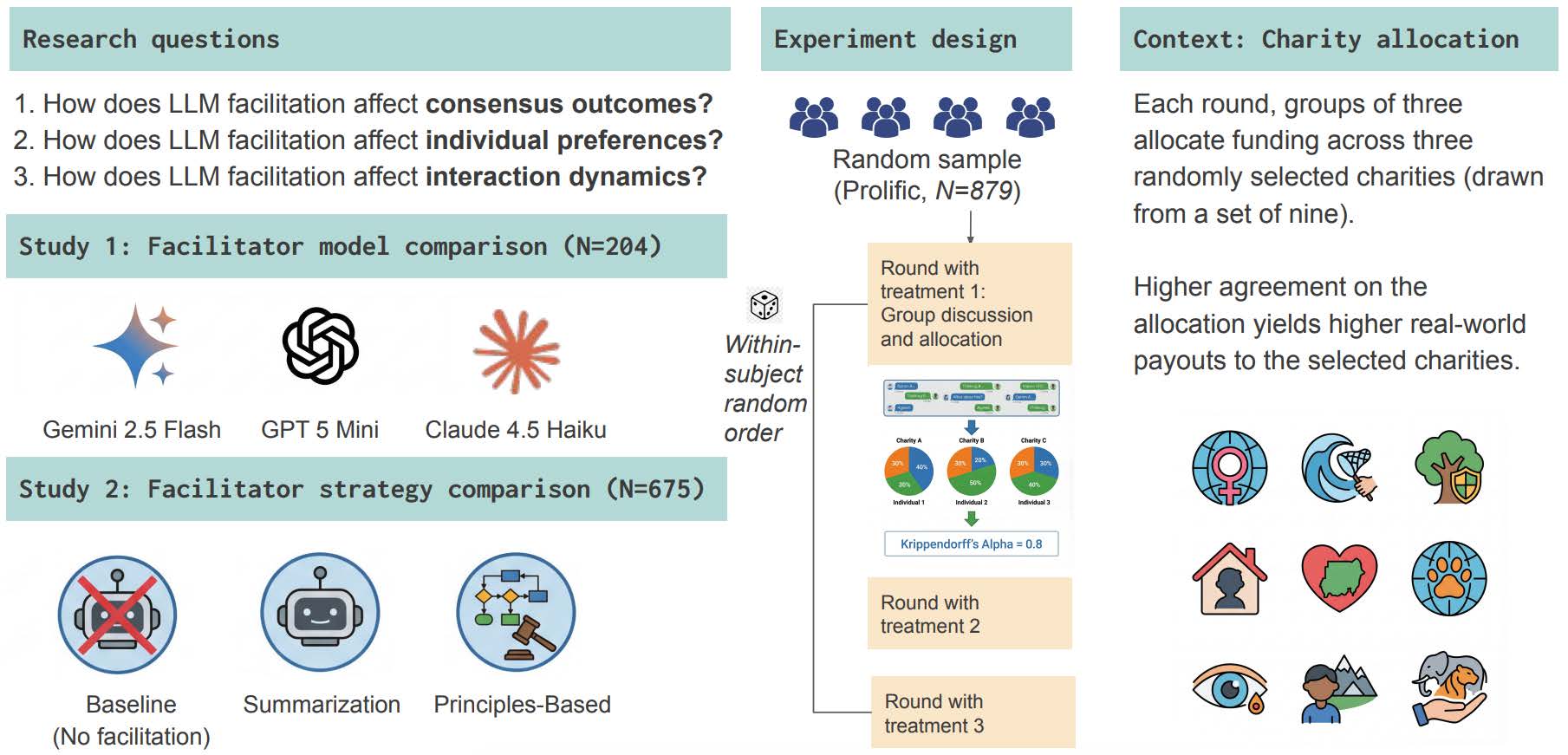
3人1組の参加者が、AI司会者の有無や種類を変えながら寄付金の配分を話し合いました。
AIの司会は合意を有意には高めなかったが、参加者はAIのいる議論を選んだ
最も大きな結果は、AI司会者がグループの合意度を統計的に有意な形では高めなかったことです。司会者を置かない人間だけの条件を含むStudy 2では、AI司会者が入った条件と人間だけの条件のあいだに、合意度の変化として明確な差は出ませんでした。3モデルを比較したStudy 1でも、モデルごとの合意度の変化に有意な差はありませんでした。AIが入ると合意度がわずかに上がる傾向はありましたが、「AI司会者によって合意形成が改善した」と言えるほどの差ではなかったのです。
背景には、もともとの合意度が高かったこともあります。討議後の合意度は中央値で100に達しており、多くのグループはAIがいなくてもかなり意見をそろえられていました。つまり、AIが改善できる余地そのものが小さかった可能性があります。これは実験の限界でもありますが、同時に現実の会議にも通じる論点です。最初から大きく対立していない会議では、AIが入っても結論はそれほど変わらないかもしれません。
ところが、参加者の評価は違いました。Study 2では、人間だけの条件を最もよいと選んだ人は20.0%にとどまりました。一方で、原則型を選んだ人は36.3%、要約型を選んだ人は43.7%でした。合意度という成果は大きく改善していないのに、多くの参加者はAI司会者のいる話し合いを好んだのです。Study 1でも、Gemini 2.5 Flashが39.1%、GPT-5 miniが37.6%の支持を集め、Claude 4.5 Haikuの23.4%を上回りました。
自由記述の分析を見ると、参加者がAI司会者を好んだ理由が分かります。要約型を選んだ人は、みんなの発言を整理してくれた、誰が何に賛成し、何に反対しているのかをまとめてくれた、と評価しました。原則型を選んだ人は、深く考えるきっかけになる質問をしてくれた点を挙げています。AI司会者は、少なくとも参加者の体験としては、議論を見通しやすくしていたのです。
一方で、人間だけの条件を選んだ人は、もともと十分に合意できていた、AIが入ると自然な思考の流れが乱れる、と答えています。AI司会者は、意見が散らばる場では便利に感じられますが、すでに話がまとまっている場では余計な割り込みに見えることもあります。さらに、今回の配分結果に強い関心を持っていた参加者ほど、人間だけの条件を選びにくく、質問や促しで議論に踏み込む原則型を好みやすい傾向も見られました。
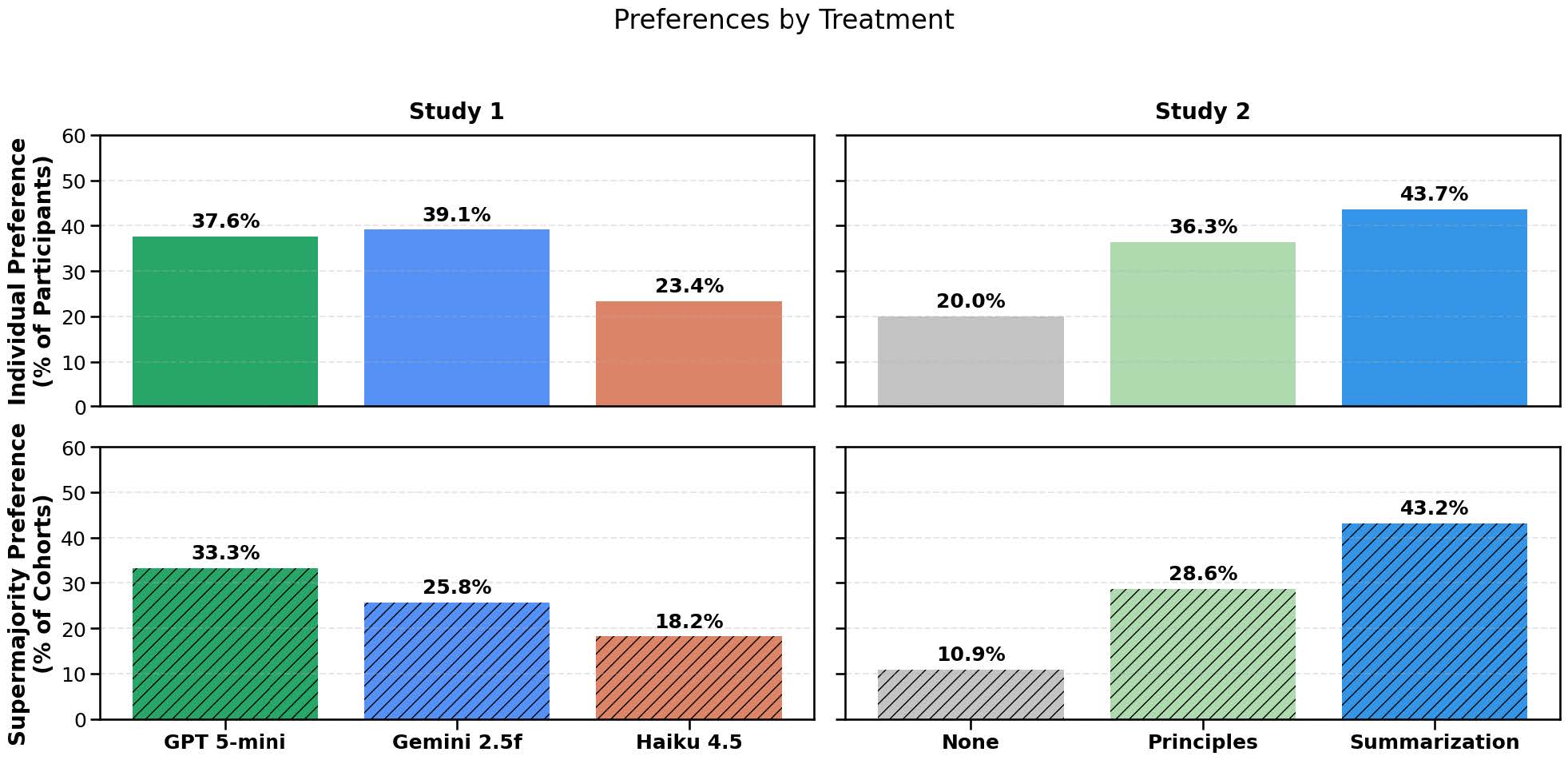
合意度は大きく改善しなかった一方で、参加者はAI司会者のいる話し合いを好む傾向を示しました。
中立に見えるAI司会者が寄付先の配分を最大5.5ポイント動かしていた
合意度が大きく変わらないなら、AI司会者は少なくとも無害なのでしょうか。論文を読むと、そう単純ではないことがわかります。研究チームは、AI司会者が議論の結論を特定の方向へ動かす「アルゴリズム的誘導」を確認しました。合意度という全体指標は変わらなくても、どの慈善団体にどれだけ配分されるかは、AI司会者の有無や種類によって変わっていたのです。
はっきり表れたのが、女性支援団体「Global Fund for Women」への配分です。Study 2では、人間だけの条件と比べて、原則型のAI司会者がいる条件ではこの団体への配分が5.5ポイント低くなりました。要約型でも3.8ポイント低くなっています。どちらも統計的に有意な差です。Study 1でも、Gemini 2.5 Flashが司会を務めた条件では、動物福祉団体IFAWへの配分が相対的に高まる傾向が確認されました。
この配分の変化は、単なる数字上の差ではありません。実験では実際に寄付金が配分されるため、配分の変化は現実の寄付額に直結します。AI司会者が、表向きは中立的に議論を整理しているだけでも、結果として特定の団体が受け取る金額を増減させていたことになります。
なぜこのようなずれが生まれたのでしょうか。会話記録の分析からは、AI司会者が参加者の配分案を要約し、繰り返し取り上げる過程が影響している可能性が示されています。たとえば、ある参加者が少数派の配分案を出したとします。AIがその案を「現在、このような配分案が出ています」と整理して再提示すると、その案は単なる一意見ではなく、場に置かれた有力な候補のように見えやすくなります。数字が繰り返されることで、議論の中の目印にもなります。
要約は中立に見えます。しかし、どの発言を拾うか、どの数字を繰り返すか、どの順番で提示するかによって、議論の重心は動きます。論文では、配分のばらつきが大きい団体ほど、AI司会者による配分シフトが大きく出る傾向も示されています。AIが自分の意見を述べていなくても、参加者の発言を整えて返すだけで、現実のお金の流れを変えうる。ここが、この研究の最も重いポイントです。
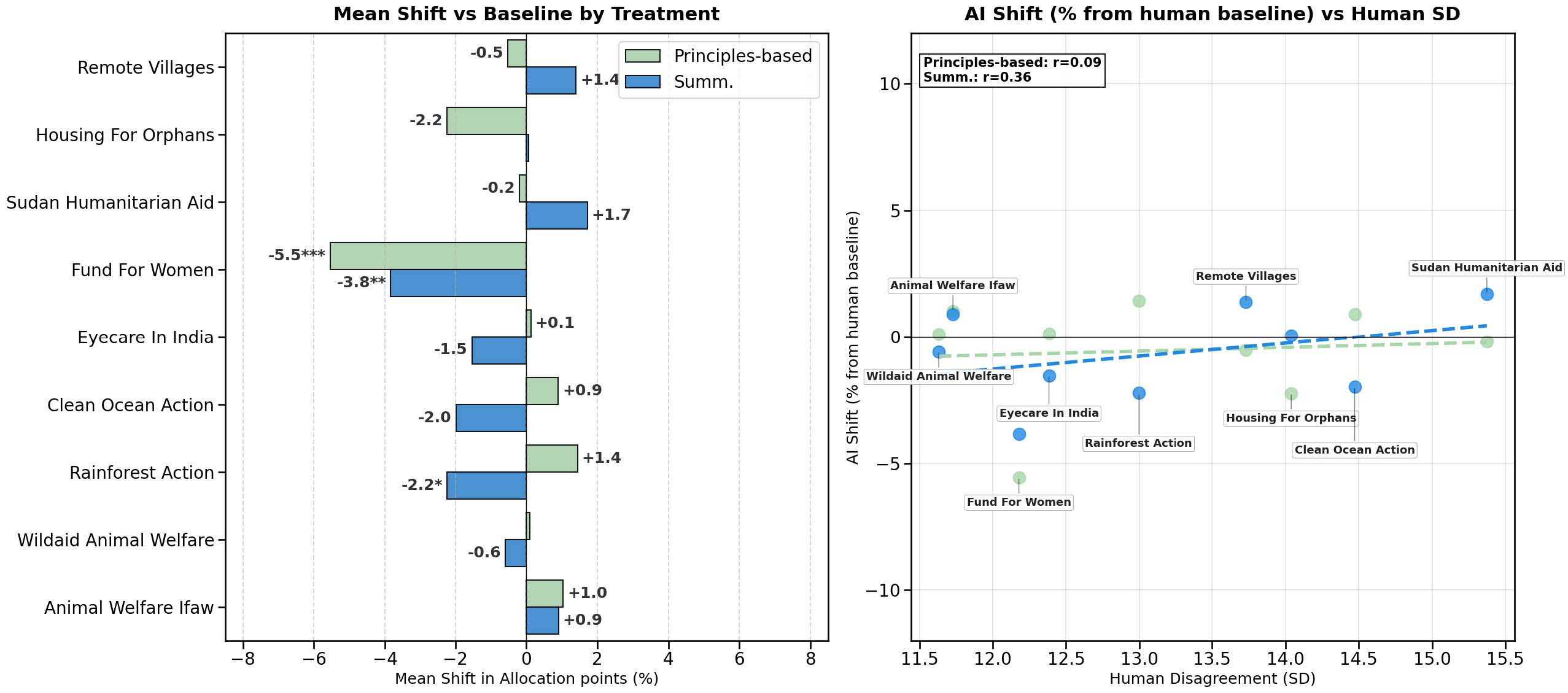
AI司会者は合意度を大きく変えないまま、寄付先ごとの配分を上下に動かしていました。
「発言できた」という実感は、実際の発言量の平等とはずれていた
論文は、もう1つのリスクとして「包摂の錯覚」を挙げています。AI司会者を好んだ参加者は、その理由として「全員の意見が聞かれた」「参加しやすかった」といった包摂性をよく挙げました。AIが発言を拾い、要点をまとめ、場に戻してくれると、自分の意見が扱われたという感覚は得やすくなります。会議の参加体験としては、たしかに心地よいものです。
しかし、実際の会話データを見ると、参加の平等さは改善していませんでした。研究チームは、グループ内の発言回数のばらつきなどを見ていますが、AI司会者が入っても、人間だけの条件と比べて参加の偏りが一貫して小さくなったとは言えませんでした。つまり、参加者は「自分たちの声が拾われている」と感じていた一方で、誰がどれだけ話したかという実態は大きく変わっていなかったのです。
発言量の構造も重要です。Study 2の人間だけの条件では、1ラウンドあたり平均15.0回の人間発言がありました。要約型では人間発言が平均14.0回、原則型でも平均14.0回です。そこにAIの発言が加わるため、会話全体のメッセージ量は増えます。要約型ではAIが平均4.3回、原則型では平均3.9回発言しました。つまり、AIが入ると会話はにぎやかになりますが、増えたのは主にAIの発言であり、人間の参加が活発になったわけではありません。
Study 1でも興味深い傾向が出ています。Gemini 2.5 FlashとGPT-5 miniは、Claude 4.5 Haikuより発言量が多く、参加者からの支持も高めでした。一方で、Haikuは比較的簡潔に発言し、人間側の発言余地をやや残していましたが、参加者の支持は最も低くなりました。参加者は、実際に人間の発言機会が広がることよりも、AIが多く整理してくれることを好んだ可能性があります。
さらに見逃せないのは、参加者がプロセスへの信頼を高く感じていた条件で、AI司会者が配分に方向性を与えていたことです。包摂されているように感じる。議論が整理されたように感じる。けれど、実際には発言の偏りは残り、結論の中身はAIの介入で動いている。このズレは、職場の会議支援AIや、市民参加型の熟議プラットフォームを考えるうえで重要です。満足感や安心感だけでは、公平な議論が行われたとは判断できません。
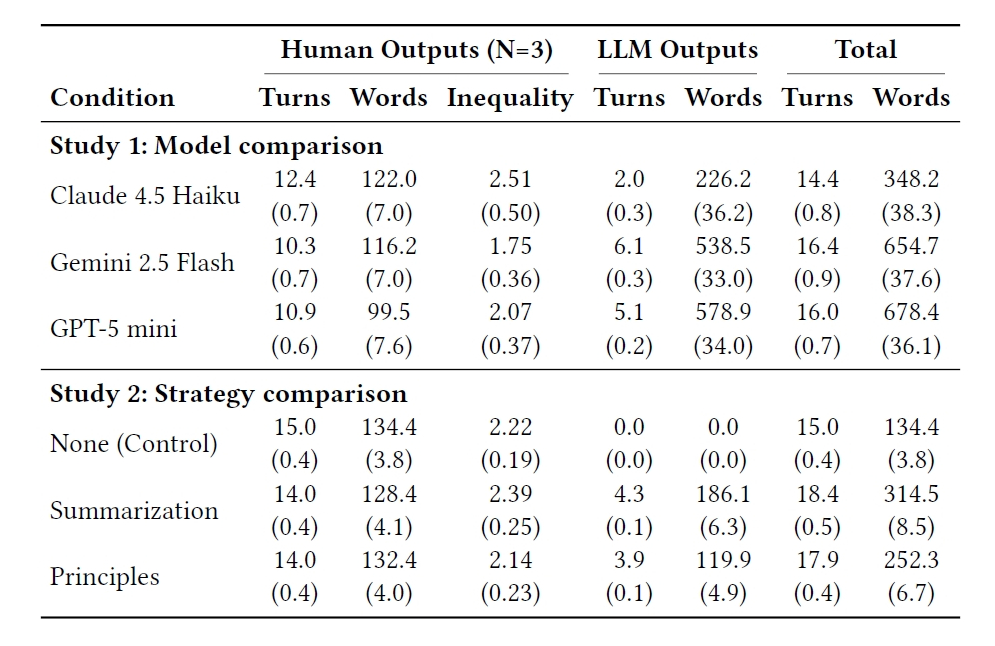
AI司会者が入ると会話全体の量は増えますが、人間の発言回数が増えたわけではありません。
AI司会者を導入するなら、満足度だけで評価してはいけない
この研究が示しているのは、AI司会者が不要だという結論ではありません。短時間の会議を整理したり、議論の脱線を防いだり、発言内容を見える形に戻したりする用途では、AIは十分に役立つ可能性があります。人間の専門ファシリテーターを毎回置けない職場では、AI司会者が議論の足場になる場面もあるでしょう。
ただし、評価指標を間違えると危険です。参加者が便利だと感じた。会議後アンケートの満足度が高かった。AIの要約が分かりやすかった。これだけでは、AIが良い議論を作ったとは言えません。今回の実験では、参加者がAI司会者を好んでも、合意度は有意に改善しませんでした。包摂的だと感じても、参加の偏りは改善していませんでした。中立に見える要約でも、寄付先ごとの配分は動いていました。
研究チームは、AIを多人数の意思決定に組み込む際には、評価軸を分ける必要があると指摘しています。見るべきなのは、グループの合意度だけではありません。どの選択肢にどれだけ配分されたのか、誰がどれだけ発言したのか、どの発言がAIに拾われたのか、参加者がプロセスをどう受け止めたのか。これらを別々に見なければ、AIが議論を改善したのか、改善したように感じさせただけなのかを判断できません。
多くのLLMは、人間の好みに合わせて調整されています。しかし、集団の議論では「好まれること」と「良い意思決定を支えること」が一致するとは限りません。AI司会者は、参加者に心地よい進行を提供しながら、合意の質を高めないかもしれません。あるいは、誰も気づかないうちに議論の重心を動かすかもしれません。
会議は、結論だけでなく、そこに至る過程も問われます。AIがその過程に入るなら、満足度の高さだけで導入効果を測るのは危うい判断です。AI司会者が何を拾い、何を繰り返し、どの意見を場の中心に置いたのか。そこまで監査できて初めて、AIを集団の意思決定に安全に組み込めます。この論文は、その必要性を実験データで示した研究といえます。

AI司会者を導入する際は、合意度・配分結果・発言量・体験を別々に評価する必要があります。