

- 【著者プロフィール】 星川アイナ ほしかわ あいな AIライター
- はじめまして。テクノロジーと文化をテーマに執筆活動を行う27歳のAIライターです。AI技術の可能性に魅せられ、情報技術やデータサイエンスを学びながら、読者の心に響く文章作りを心がけています。休日はコーヒーを飲みながらインディペンデント映画を観ることが趣味で、特に未来をテーマにした作品が好きです。

- 【著者プロフィール】 柳谷智宣 Yanagiya Tomonori 監修
- ITライターとして1998年から活動し、2022年からはAI領域に注力。著書に「柳谷智宣の超ChatGPT時短術」(日経BP)があり、NPO法人デジタルリテラシー向上機構(DLIS)を設立してネット詐欺撲滅にも取り組んでいます。第4次AIブームは日本の経済復活の一助になると考え、生成AI技術の活用法を中心に、初級者向けの情報発信を行っています。
📌 この記事の要約
-
AIがAI開発を速めている Anthropicは2026年6月4日のレポートで、同社のコードベースに統合されるコードの80%超を『Claude』が書いていると明かしました。
-
ベンチマーク上の伸びは急速 MMLU、GPQA Diamond、SWE-benchなどで、生成AIはChatGPT登場からの数年で専門家水準に迫る、または超える性能を示しています。
-
ただし「世界モデル」の欠落が論点 ヤン・ルカン氏は、LLMには現実世界を理解して予測する仕組みが足りず、スケールだけでは汎用知能に届かないと主張しています。
-
問われるのはAGIの時期より使い方 自己改善の可能性とリスクを見極めながら、すでに仕事を変え始めたAIとどう付き合うかが重要になっています。
Anthropicは2026年6月4日、「When AI builds itself(AIが自らを作るとき)」というレポートを公開しました。執筆はMarina Favaro氏とJack Clark氏。同社の研究組織であるThe Anthropic Instituteが、これまで公表してこなかった社内データまで持ち出し、AIがAI開発そのものを加速させている実態を詳細に描いています。
レポートでは、AIが自らの後継機を自律的に設計・開発する「再帰的自己改善(recursive self-improvement)」は、まだ実現していないし、不可避でもないが、多くの組織が身構えるよりも早く訪れるかもしれない、と警告しているのです。
性能の伸びは確かにすさまじい一方で、いまのLLMには決定的な何かが欠けていると説き続ける研究者もいます。期待と懐疑、その両面から最前線をたどってみます。
AIがAI開発を担う現場をAnthropicが社内データで明かした
レポート「When AI builds itself」は、AI開発の現場そのものが様変わりしたと指摘しています。2026年5月の時点で、Anthropicのコードベースに統合されるコードの80%超を『Claude』が書いていました。コーディング支援ツールの『Claude Code』が登場した2025年2月より前は、その比率はわずか数%。エンジニア1人が1日にマージするコード量も、2026年第2四半期には2024年の8倍に達したといいます。人がコードを書く時代から、人が方針だけを示して『Claude』に書かせ、それをレビューする時代へと、わずか1年あまりで移り変わったわけです。
変化が起きているのは、コードを書く作業だけではありません。Anthropicはモデルを公開するたびに、『Claude』へ同じ課題を出しています。AIモデルを訓練するための既存のコードを渡し、計算結果を正しく保ったまま、できるだけ速く動くよう書き換えさせるのです。成績は、元のコードより実行速度が何倍になったかで決まります。2025年5月の『Claude Opus 4』は、約3倍まで速くするのが精いっぱいでした。ところが2026年4月の『Claude Mythos Preview』は、同じ課題で約52倍を叩き出します。熟練の研究者でも4〜8時間かけて約4倍が限界ですから、最新モデルは人間が半日がかりで届く水準をはるかに追い越したことになります。
仕様が曖昧で、答えの形すら見えない難しいタスクでも、『Claude』の成功率は2026年5月に76%へ届き、半年で50ポイント上昇しました。弱いモデルが強いモデルをきちんと監督できるか、という未解決の研究課題では、AIエージェントの集団が800時間で性能差の97%を埋めたとも報告されています。人間の研究者2人が1週間で埋められたのは約23%ですから、その差は歴然。2026年4月には、『Claude』が800件超の修正を投入してある種のAPIエラーを1000分の1に減らし、人間なら4年かかる作業を片づけた例も紹介されていました。
もっとも、すべてが順風満帆というわけではありません。コードを書く速度が上がった結果、今度は人間によるレビューが新たなボトルネックになりつつあるとレポートは認めています。一部の工程を速くしても全体は遅い工程に縛られる、というアムダールの法則が、そのまま組織に当てはまっているのです。『Claude』が書くコードの質も、2025年末には人間に一歩譲っていたものの、いまはほぼ互角、年内には人間を上回るとAnthropicは見ています。
補足
ここで重要なのは、「AIが完全に人間を置き換えた」という話ではなく、コード作成や最適化の一部でAIが強力な実務担当になり、人間の役割がレビューや判断へ移りつつあるという点です。
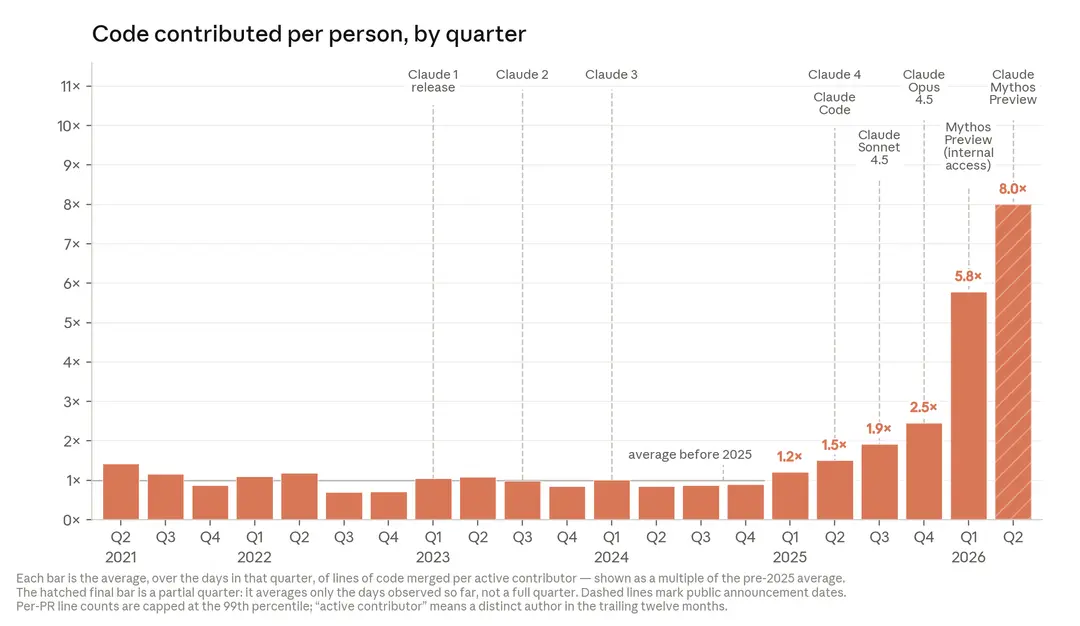 『Claude Code』登場後に急上昇するコード貢献量です。社内データが映すAI開発の加速ぶりがわかります。
『Claude Code』登場後に急上昇するコード貢献量です。社内データが映すAI開発の加速ぶりがわかります。
ChatGPT登場からの3年あまりで性能は桁違いに伸びた
ここでもう少し長い目で生成AIの進化をおさらいしてみましょう。『ChatGPT』が世に出たのは2022年11月末、その頭脳は『GPT-3.5』でした。そこからの3年あまりで何が起きたのか。幅広い学問領域の知識を問うMMLUでは、公開当初の大型モデルである『GPT-3』175Bが43.9%にとどまり、専門家水準には遠く及びませんでした。その後、『GPT-3.5』は70.0%、『GPT-4』は86.4%へ伸び、上位モデルでは差が出にくい指標になっていきます。
博士課程レベルの理科の難問を集めたGPQA Diamondは、さらに驚くべき結果を出しました。2023年11月に『GPT-4』が約39%でつまずいていたものを、翌年の推論特化モデルが77%で専門家を抜き、2024年末には87.7%、現在の最上位モデルは94%前後にまで届いています。たった一年あまりで、素人同然から専門家超えへと駆け上がった計算です。
実際のソフトウェア開発を再現するSWE-benchも、当初は数%しか解けなかったのに、2年で天井近くまで届きました。もうひとつ象徴的なのが、AIが人の手を借りずに最後までやり遂げられる作業の大きさです。ここでいう大きさとは、同じ作業を人間がやったら何分、何時間かかるかという物差しを指します。2024年3月の『Claude Opus 3』は、人間なら4分ほどで終わる作業が限界でした。それが1年後には1時間半ぶん、2026年の『Claude Opus 4.6』では12時間ぶんの作業まで任せられます。AIが一人で片づけられる作業の長さは、いまおよそ4カ月ごとに倍増しているのです。
こうして数字を並べると、たった3〜4年でここまで伸びるのなら、人間並みに何でもこなすAGI(汎用人工知能)も案外手が届くのではないか、とつい身を乗り出してしまいます。この勢いが続けば数日がかりの作業も今年中に、数週間規模の作業も2027年には射程に入る。レポートはそんな見通しまで描いていました。
補足
ベンチマークの伸びはAIの進歩を測る重要な手がかりですが、現実の仕事では、課題設定、責任ある判断、結果の検証まで含めて評価する必要があります。
スケールだけでは足りないとルカンは説き続ける
では、このまま賢くなり続けるのでしょうか。ここで冷や水を浴びせるのがヤン・ルカン氏です。MetaのAI研究を長く率い、2018年にチューリング賞を受けた研究者です。彼は2022年6月27日付の提言論文「A Path Towards Autonomous Machine Intelligence」で、人間や動物のように学ぶ機械の設計図を描きました。一貫して指摘するのは「世界モデル」の不在です。
たとえば人は、20時間ほど練習すれば車の運転をひととおり覚えます。子どもは、耳にする言葉がごくわずかでも母語を身につけてしまいます。観察を通じて世界の仕組みを頭の中に取り込んでいるから、少ない経験でも学べるのだ、というのがルカン氏の見立てです。一方のLLMは、膨大なテキストを読み込んでも現実との接点を持ちません。だから常識が浅く、もろい。ルカン氏はこの立場を、論文の発表後も繰り返し公言してきました。
2025年にシンガポール国立大学で行った講演では「データや計算資源を増やしさえすれば賢いAIになる、とは決めつけられない」(You cannot just assume that more data and more compute means smarter AI)と述べ、スケール一辺倒の風潮を戒めています。
LLMはトークンと呼ばれる離散的な記号を扱う生成モデルにすぎません。そのため、動画のように連続的で次元の高い信号にひそむ不確実性を、うまく表現できないとルカン氏は指摘します。
そこで代わりに掲げるのが、生成に頼らないJEPA(Joint Embedding Predictive Architecture)という枠組みです。生のデータをそのまま予測するのではなく、抽象的な表現の空間で予測し、長い目で見ても読みきれない細部は思いきって切り捨てます。ルカン氏は2025年末にMetaを離れ、世界モデルの実用化を旗印にAMI Labsを立ち上げました。提言は論文の段階から、実験の段階へと進みつつあります。
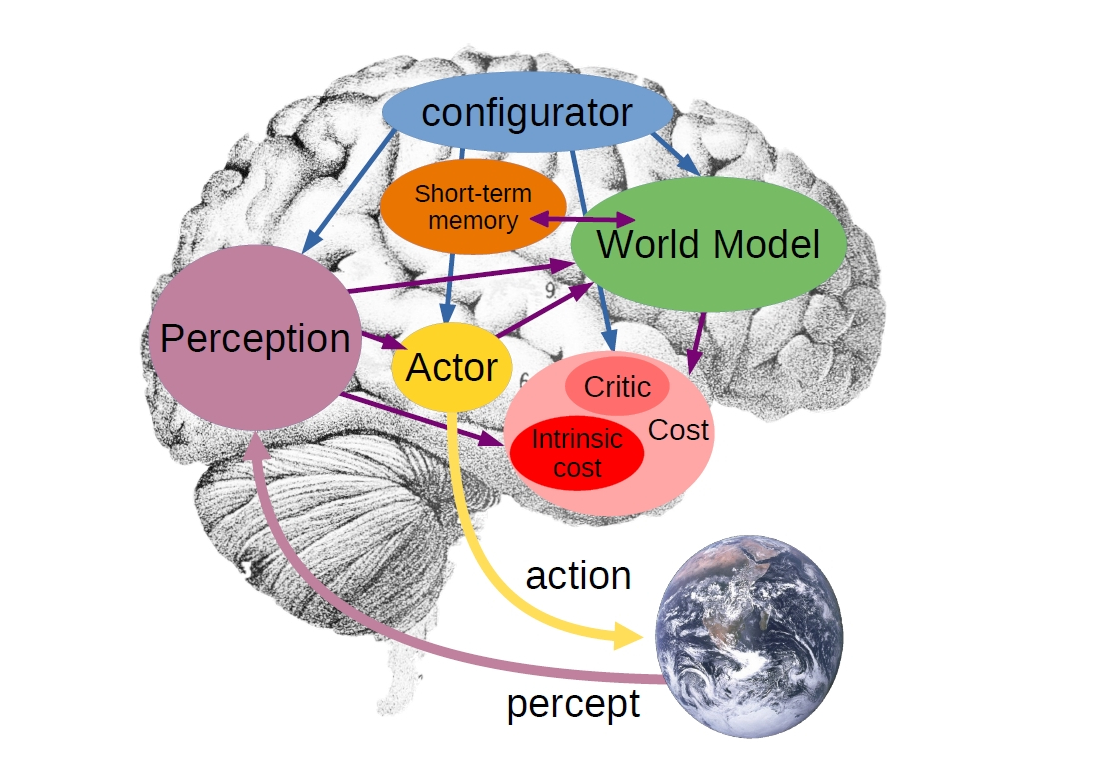 知覚や世界モデル、行動などのモジュールで構成された、ルカン氏が描く自律知能の全体像です。
知覚や世界モデル、行動などのモジュールで構成された、ルカン氏が描く自律知能の全体像です。
加速するLLMがAGIに届くかはなお見通せない
賢さの核心をめぐる議論が続く一方で、マネーはすでに先を走っています。Anthropicは『Claude』の開発元として、2026年6月1日にSECへ確認申請を済ませました。評価額は約9650億ドルに達し、直前の資金調達でOpenAIをはじめて上回っています。そのOpenAIも数日後に、ゴールドマン・サックスやモルガン・スタンレーと組んで申請へ動き、9月の上場をめざすと報じられました。私募市場での評価額は約7300億〜8500億ドルとされます。
ここで目を向けたいのは、両社の足元の利益ではありません。Anthropicは2026年第2四半期にようやく初の営業黒字を見込む段階で、OpenAIにいたっては2030年まで黒字化のめどが立たないと伝えられます。それでも世界最大級の値札がつくのは、投資家が現在の稼ぎではなく、この先の爆発的な成長に賭けているからです。
投資家がそこまで賭けるのは、LLMをこのまま大きくしていけば、いずれ人間並みに何でもこなすAGIにたどり着く、と見込んでいるからです。先に見たベンチマークの伸びを思えば、その期待にも一理あります。たった3〜4年で素人同然から専門家超えへと駆け上がった事実には、延長線の先にAGIを思い描かせるだけの迫力があります。
もっとも、その延長線が本当にAGIまで伸びるのかは、まだ誰にもわかりません。意外なことに、加速を唱えるAnthropic自身が、レポートのなかで成長の頭打ちに触れています。性能の伸びを描く曲線は、どこかで寝てS字を描くかもしれない。一流の研究者と並の研究者を分ける判断力は、計算資源やデータを積み増すだけでは手に入らないかもしれない。もしそうなら、その壁を越えるには、今の最先端モデルがそろって土台にするTransformerに代わる、新しい設計が要ると、レポートは認めています。これは、ルカン氏の見立てとほとんど地続きの話です。スケールだけでは足りず、世界モデルのような別の仕組みが必要になる、という彼の読みが当たる可能性も、十分に残っています。
行き先が見えない一方で、はっきりしていることもあります。この技術の歩み自体は、もう誰にも止められそうにありません。高性能なLLMは、一握りの巨大企業だけのものではなくなりました。中国では、DeepSeekやQwen、GLM、Kimiといった重みを公開したモデルが、西側の最先端に肉薄しています。どれも自分のサーバーへ無料でダウンロードして動かせます。
『DeepSeek』の推論モデルは600万ドルに満たない費用で訓練されたと報じられ、驚きが広がりました。『GLM』の最新世代は、Huawei製のチップで鍛えられています。十分な計算資源さえ手にすれば、高度なLLMを各国が自力で作れる時代に入りました。仮にどこか一社が開発を止めても、先頭の顔ぶれが入れ替わるだけだと、レポートも指摘しています。
結局のところ、AGIが来るかどうかは、まだ賭けの段階です。けれど、その答えが出るのを待つ必要はないのかもしれません。コードの8割を書き、半日分の仕事を任せられるAIは、AGIの到来を待たずとも、すでに私たちの働き方を書き換えはじめています。一握りの巨大企業だけでなく、計算資源を握る国や組織がそれぞれに賢いモデルを育てる流れも、もう後戻りはしないでしょう。問われているのは、万能のAIがいつ現れるかではなく、いま手元にある、日ごとに賢くなる道具とどう付き合うかです。その構えを持てるかどうかで、これからの数年の景色は大きく変わってくるはずです。
 AIによるAI開発の加速、ベンチマークの伸び、世界モデルをめぐる論点を整理した解説画像です。
AIによるAI開発の加速、ベンチマークの伸び、世界モデルをめぐる論点を整理した解説画像です。