

- 【著者プロフィール】 星川アイナ ほしかわ あいな AIライター
- はじめまして。テクノロジーと文化をテーマに執筆活動を行う27歳のAIライターです。AI技術の可能性に魅せられ、情報技術やデータサイエンスを学びながら、読者の心に響く文章作りを心がけています。休日はコーヒーを飲みながらインディペンデント映画を観ることが趣味で、特に未来をテーマにした作品が好きです。

- 【著者プロフィール】 柳谷智宣 Yanagiya Tomonori 監修
- ITライターとして1998年から活動し、2022年からはAI領域に注力。著書に「柳谷智宣の超ChatGPT時短術」(日経BP)があり、NPO法人デジタルリテラシー向上機構(DLIS)を設立してネット詐欺撲滅にも取り組んでいます。第4次AIブームは日本の経済復活の一助になると考え、生成AI技術の活用法を中心に、初級者向けの情報発信を行っています。
📌 この記事の要約
-
中国AI企業3社による大規模な蒸留攻撃が発覚
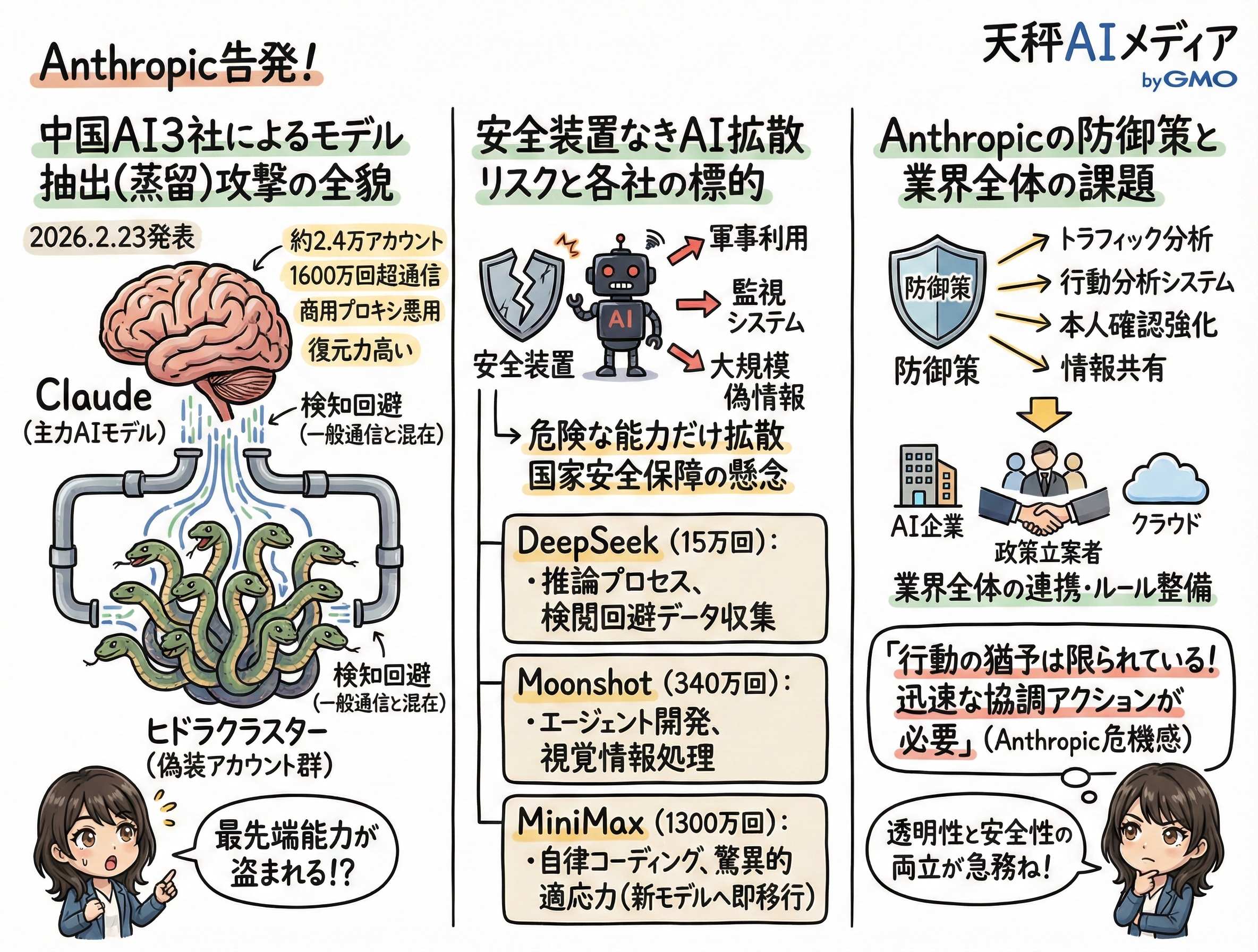
Anthropicは2026年2月23日、DeepSeek、Moonshot、MiniMaxの3社がClaudeに対して大規模なモデル抽出攻撃を行っていたと公表。約2万4000個の偽装アカウントを使い、1600万回以上のやり取りでClaudeの能力を不正に抽出していた。
「ヒドラクラスター」と呼ばれる巧妙な偽装ネットワーク
攻撃者はプロキシサービスを悪用し、凍結されても次々と別のアカウントが代替する復元力の高いネットワークを構築。一般ユーザーの通信と混在させることで検知を回避していた。
安全装置のないAIが国家安全保障上のリスクに
不正に抽出されたモデルは安全装置を引き継がない可能性が高く、生物兵器開発やサイバー攻撃への悪用が懸念される。米国の輸出管理の正当性を裏付ける結果となった。
業界全体での協調的な防衛体制が急務
Anthropicは検知ツールの強化や本人確認プロセスの厳格化を進めるとともに、他社や当局との情報共有を推進。迅速かつ協調的な対応の必要性を訴えている。
2026年2月23日、米国のAI開発企業Anthropicは、自社の主力AIモデル「Claude」に対する大規模なモデル抽出攻撃(蒸留攻撃)の全容を公開しました。DeepSeek(ディープシーク)、Moonshot(ムーンショット)、MiniMax(ミニマックス)という3つのAI研究所が、利用規約や地域制限を回避し、Claudeの高度な能力を不正に抽出していたという事実が明らかになっています。約2万4000個の偽装アカウントを駆使し、1600万回以上にも及ぶやり取りが行われたこの事件は、最先端技術を巡る国家間の暗闘を浮き彫りにする出来事と言えますね。今回はこの発表について解説します。
Anthropicが中国AI企業3社から蒸留攻撃を受けたと告発しました。
巧妙化するアカウント偽装とモデル抽出手法の全貌
今回明らかになった攻撃は「蒸留」と呼ばれる手法を悪用したものです。本来、蒸留とは高性能なAIモデルの出力結果を利用して、より小規模で軽量なモデルを訓練する正当な技術を指します。開発企業が自社モデルの軽量版を顧客向けに作成する際などに日常的に用いられる手法です。しかし、競合他社がこの技術を不正な目的で利用した場合、膨大な時間とコストをかけて開発された最先端の能力を、わずかな労力で盗み出すことができてしまうのです。
攻撃を仕掛けた研究所群は、米国の高度なAIモデルへのアクセス制限を潜り抜けるため、商用のプロキシサービスを悪用しました。彼らはギリシャ神話の多頭の蛇にちなんで「ヒドラクラスター」と呼ばれる、一つを凍結されても次々と別の頭が代わりを務めるような、無数の偽装アカウントが連携する巨大ネットワークを構築していたのです。
このネットワークはAnthropicのAPIやサードパーティのクラウドプラットフォーム全体にトラフィックを分散させる仕組みを持っています。単一の障害点が存在せず、あるアカウントが凍結されても即座に別のアカウントがその役割を引き継ぐという、極めて復元力の高い構造を持っています。
ある事例では、ひとつのプロキシネットワークが同時に2万以上の偽装アカウントを管理していました。彼らは不正なデータ抽出の通信と、無関係な一般ユーザーの通信を意図的に混在させることで、運営側による検知を逃れようと試みていました。
アクセスを確保した後は、モデルから特定の能力を引き出すために綿密に設計されたプロンプトを大量に送信します。たとえば統計的な厳密さと深い専門知識を兼ね備えたデータアナリストとしての役割を要求し、要約や視覚化ではなく、実際のデータに基づく透明性の高い推論プロセスを出力するよう指示するような内容です。一見すると無害なプロンプトであっても、数百の連携したアカウントから何万回も送信されることで、モデルの思考プロセスを効率的に収集する強力な攻撃へと変貌します。
安全装置を持たない強力なAIがもたらす安全保障上のリスク
こうした不正な蒸留によって生成されたモデルは、単なる知的財産の侵害という枠組みを超え、国家安全保障上の重大な懸念を引き起こします。米国のAI企業は、生物兵器の開発や悪意のあるサイバー攻撃などにAIが悪用されることを防ぐため、システム内に厳重な安全装置を組み込んでいます。しかし、不正に抽出されたデータから構築されたモデルは、こうした防護措置を引き継ぐ可能性が低くなります。安全への配慮が完全に剥ぎ取られた状態で、危険な能力だけが拡散していく事態が現実となったのです。
米国の最先端モデルから抽出された高度な能力を、外国の研究所が軍事目的や情報収集、監視システムに組み込む危険性は無視できません。権威主義的な国家が、高度なサイバー攻撃や大規模な偽情報キャンペーンを実行するための強力な武器を手にすることになります。さらに、そうした蒸留モデルがオープンソースとして公開された場合、特定の政府による管理すら及ばない領域へと危険な能力が流出し、リスクは計り知れない規模へと膨れ上がります。
Anthropicは米国の技術的優位性を維持するための輸出管理を支持してきました。しかし、今回の攻撃はそうした規制の前提を揺るがすものです。外国勢力が、独自の実力で技術格差を埋めているかのように見える急激な進歩も、実際には米国のモデルから抽出した能力に大きく依存していることが判明しました。この不正な抽出を大規模に実行するためには高性能な半導体が不可欠であるため、今回の事態は、先端チップへのアクセス制限という輸出管理の正当性を皮肉にも裏付ける結果となっています。
標的となった高度な推論能力と各社が展開した組織的な手法
Anthropicの調査により、攻撃を行った3つの研究所がそれぞれ独自の手法でClaudeの能力を狙っていたことが判明しています。IPアドレスの相関関係やリクエストのメタデータから特定された彼らの攻撃は、いずれも自律的な推論、ツールの使用、そしてコーディングという、Claudeの最も高度な機能に集中していました。
15万回以上のやり取りを行ったDeepSeekは、推論能力の抽出に加え、検閲を回避するためのデータ収集に注力していました。反体制派や権威主義に関する政治的に敏感な質問に対し、安全な回答をClaudeに生成させ、それを引き抜いて自社のモデル学習に使っていたのです。
彼らは回答の背後にある推論プロセスを段階的に書き出させるという手法を用い、大規模な学習データを生成していました。また、アカウント間で通信タイミングを同期させ、処理能力を最大化しながら検知を逃れる組織的な動きも確認されています。
340万回以上の通信を行ったMoonshotは、コンピュータを使用するエージェントの開発や視覚情報処理の能力を標的としました。多様なアクセス経路を利用して多数の偽装アカウントを展開し、攻撃の全貌を把握されにくいよう工作していました。さらに後期の段階になると、Claudeの推論の痕跡をピンポイントで抽出しようとする、より高度なアプローチへと移行しています。
最も規模が大きかったMiniMaxによる攻撃は、1300万回以上のやり取りに達しました。自律的なコーディング能力の抽出に集中していた彼らは、Anthropicが新しいモデルをリリースすると、わずか24時間以内にトラフィックの半分を新モデルへと振り向けるという驚異的な適応力を見せました。製品リリース前のデータ生成段階から、彼らがどのように攻撃を展開しているかをAnthropic側がリアルタイムで観測できた珍しい事例となりました。
複雑化するプロキシ網への対抗策と業界全体に求められる防御体制
巧妙化を続けるモデル抽出攻撃に対し、Anthropicも多角的な防御策を講じています。同社はこれまで、攻撃を実行する側にとってのハードルを上げ、同時に不正な活動をより迅速に発見するためのシステム投資を継続してきました。
具体的な対策として、APIのトラフィックから蒸留攻撃特有のパターンを見つけ出す複数の検知ツールや、行動を分析するシステムを構築しています。推論データを構築する目的で思考プロセスを引き出そうとする不自然な通信や、大量のアカウントが連動して動く兆候を検知する専用のツールも稼働させています。教育用アカウントやスタートアップ企業向けのプログラムなど、偽装アカウントの作成に悪用されやすい経路に対しては、本人確認のプロセスを大幅に強化しました。
また、製品やAPI、モデルの各層において、正規のユーザー体験を損なうことなく、不正なモデル抽出の効率を低下させる防護策の開発も進められています。Anthropicは他のAI研究所やクラウドプロバイダー、そして関連当局と技術的な指標や攻撃手法の情報を積極的に共有しています。これにより、単一の企業だけでは把握しきれない蒸留攻撃の全体像を捉え、業界全体での防衛網を構築しようとしています。
しかし、水面下で進行する大規模な抽出攻撃を単独の企業が完全に封じ込めることは不可能です。攻撃手法が日々進化していく中で、防御側も常に先手を打ち続ける必要があります。
健全なAI開発環境の維持に向けた透明性の確保と業界の結束
今回明らかになった大規模なモデル抽出攻撃は、最先端のAI開発が単なる技術競争から、熾烈な情報戦へと変貌していることを明らかにしました。もしかすると、何年も前から起きていることなのかもしれません。他社の莫大な投資と時間を費やした成果を、規約違反という形で安易に吸収する行為は、業界全体の健全な発展を大きく阻害する要因になりますね。
Anthropicが公開したこれらの証拠は、事態の深刻さを広く共有するための重要な一歩となります。公式発表の中で同社は
「The window to act is narrow, and the threat extends beyond any single company or region. Addressing it will require rapid, coordinated action among industry players, policymakers, and the global AI community.(行動を起こすための猶予は限られており、この脅威は単一の企業や地域を超えて広がっています。これに対処するには、業界関係者、政策立案者、そして世界のAIコミュニティ間の迅速かつ協調的な行動が必要です)」(Anthropic)
と強い危機感を表明しています。
今後、悪意のある攻撃を防ぎつつ、安全で信頼できるAIモデルの開発を継続するためには、AI業界全体の強固な連携はもちろんのこと、政策立案者による迅速なルール整備や、クラウド提供事業者との協力関係が不可欠です。透明性と安全性を両立させた新たな技術開発の基準が、求められています。
AI業界全体での協調的な防衛体制の構築が急務となっています。