生成AI
「ただ2回繰り返すだけ」でAIが賢くなる?Googleが発見した魔法のようなプロンプトテクニック
-
-


アイサカ創太(AIsaka Souta)AIライター
こんにちは、相坂ソウタです。AIやテクノロジーの話題を、できるだけ身近に感じてもらえるよう工夫しながら記事を書いています。今は「人とAIが協力してつくる未来」にワクワクしながら執筆中。コーヒーとガジェット巡りが大好きです。

柳谷智宣(Yanagiya Tomonori)監修
ITライターとして1998年から活動し、2022年からはAI領域に注力。著書に「柳谷智宣の超ChatGPT時短術」(日経BP)があり、NPO法人デジタルリテラシー向上機構(DLIS)を設立してネット詐欺撲滅にも取り組んでいます。第4次AIブームは日本の経済復活の一助になると考え、生成AI技術の活用法を中心に、初級者向けの情報発信を行っています。
2025年12月17日、Google Researchの研究チームが面白い論文を発表しました。タイトルは「Prompt Repetition Improves Non-Reasoning LLMs(プロンプトの繰り返しは、推論を行わないLLMの性能を向上させる)」で、著者はGoogle ResearchのYaniv Leviathan氏、Matan Kalman氏、Yossi Matias氏らです。
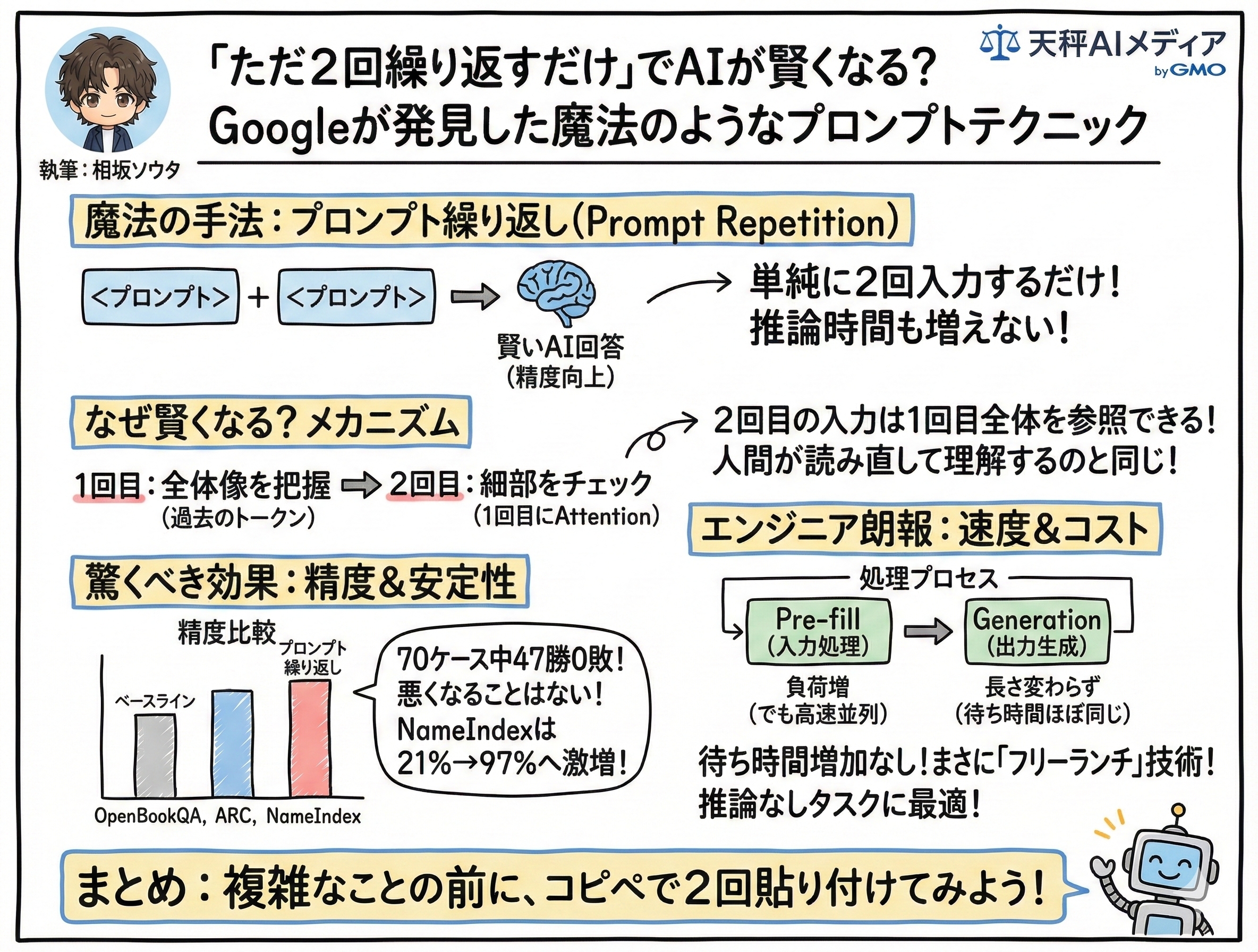
彼らが提唱する手法は、あまりにも単純で、それでいて直感に反するものでした。それは「プロンプト(指示)を単に2回繰り返して入力するだけで、AIの回答精度が向上する」というものです。しかも、推論時間を増やさずに、です。
今回はこの「プロンプト繰り返し(Prompt Repetition)」について、そのメカニズムと驚くべき効果を、具体的なデータを交えて解説していきましょう。
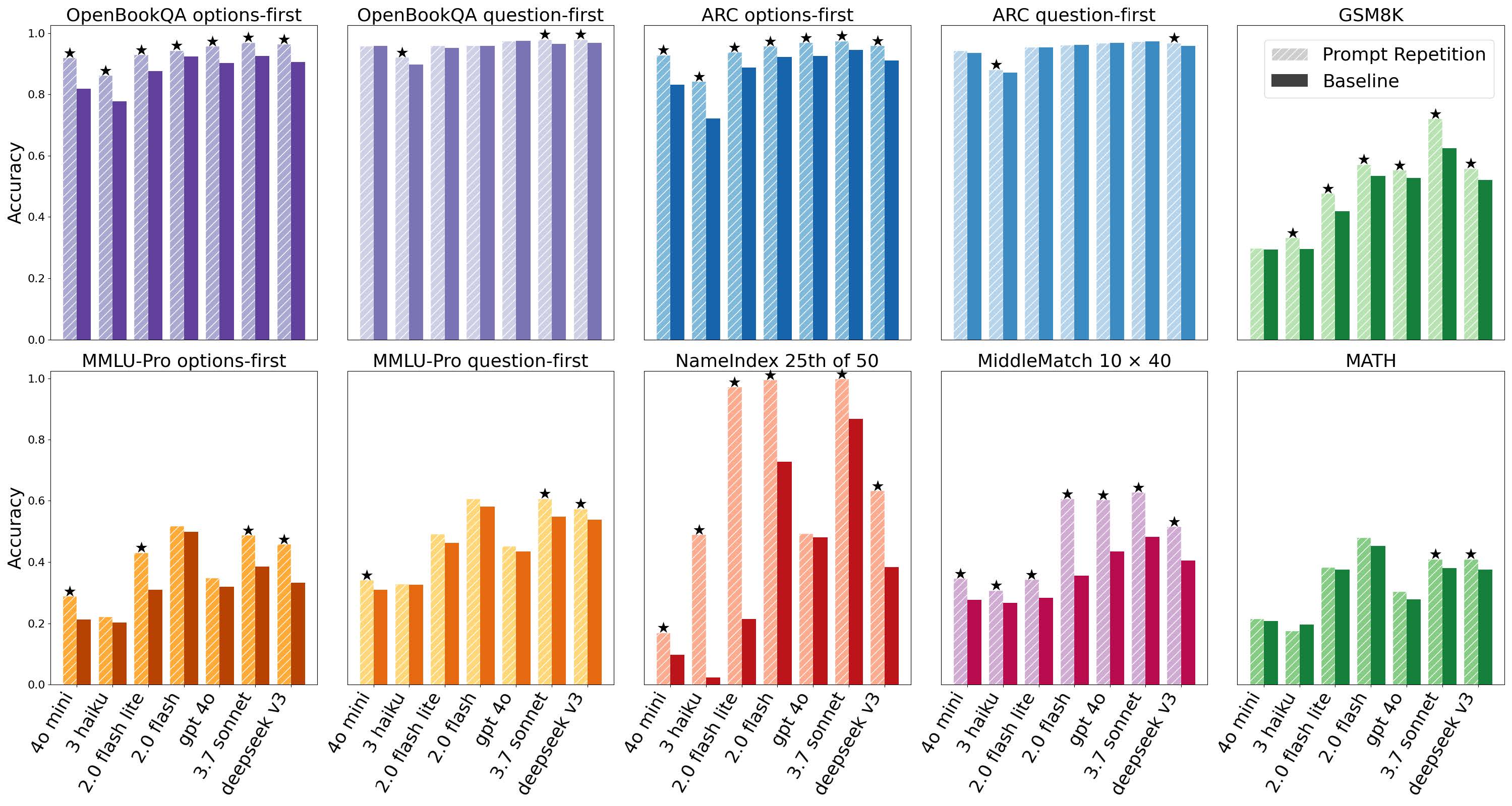
推論を用いない設定における主要LLMと各種ベンチマークでのベースラインとプロンプト繰り返し手法の精度比較グラフです。
なぜ「同じことを2回言う」だけで賢くなるのか
なぜ「同じことを2回言う」だけで賢くなるのでしょうか。私たちが普段使っている大規模言語モデル(LLM)は、基本的には「因果的言語モデル」として学習されています。つまり、AIモデルは前の単語から次の単語を予測することはできますが、未来の単語を見て前の単語を理解することはできない、という構造上の制約を持っているのです。
例えば、「<文脈> <質問>」という順序で情報を与えられた場合と、「<質問> <文脈>」という順序で与えられた場合では、モデルの内部処理における情報の見え方が異なってしまいます。特に質問が先に来て、その判断材料となる文脈が後に続く場合、モデルは文脈を処理している最中に「あ、これはさっきの質問に関係ある情報だ」と振り返る必要がありますが、これが意外と苦手なんですね。
そこで登場するのが「プロンプト繰り返し」です。入力テキスト全体を「<プロンプト><プロンプト>」という形で2回繰り返して入力します。こうすることで、モデルが2回目のプロンプトを処理する際、すでに1回目のプロンプト情報がすべて「過去のトークン」として存在している状態になります。
つまり、2回目のプロンプトの各トークンは、1回目のプロンプト全体に対して注意(Attention)を向けることができるようになるのです。これは人間で言えば、難解な文章を一度読み終えてから、内容を把握した上でもう一度読み直す行為に似ています。2回目には、全体像を理解した上で細部をチェックできるため、理解度が格段に上がるわけです。この手法は、Gemini 2.0 FlashやGPT-4o、Claude 3.7 Sonnet、DeepSeek V3といった最新のモデルすべてにおいて効果が確認されています。

ベースラインとプロンプト繰り返し手法における、実際の入力クエリの違いを示した比較です。
驚くべきベンチマーク結果
研究チームはARCやOpenBookQA、GSM8K、MMLU-Pro、MATHといった7つの主要なベンチマークでテストを行いました。その結果は驚くべきものでした。推論(Chain of Thoughtなど)を行わない設定において、プロンプト繰り返しは70のテストケース(モデルとベンチマークの組み合わせ)のうち、なんと47のケースで統計的に有意な勝利を収めたのです。そして敗北はゼロ。つまり、少なくとも「悪くなることはない」という圧倒的な安定感を見せつけました。
特に効果が大きかったのは、情報の配置順序に敏感なタスクです。例えば、選択肢が先に提示され、質問が後に来るようなケース、あるいはその逆のケースでも、情報を2回繰り返すことでモデルは文脈全体を適切に把握できるようになります。
グラフを見ると、OpenBookQAやARCといった常識推論や読解を要するタスクにおいて、精度のバーが伸びているのが確認できます。また、独自に作成された「NameIndex」というタスクでの結果は衝撃的でした。これは50個の名前のリストを与えて「25番目の名前は?」と聞く単純なタスクですが、Gemini 2.0 Flash-Liteの場合、通常の方法では正解率が21.33%に留まりました。しかし、プロンプトを繰り返すだけで、これが97.33%へと跳ね上がったのです。情報の位置を見失いがちなモデルにとって、繰り返しがいかに強力な補助輪になるかがわかります。
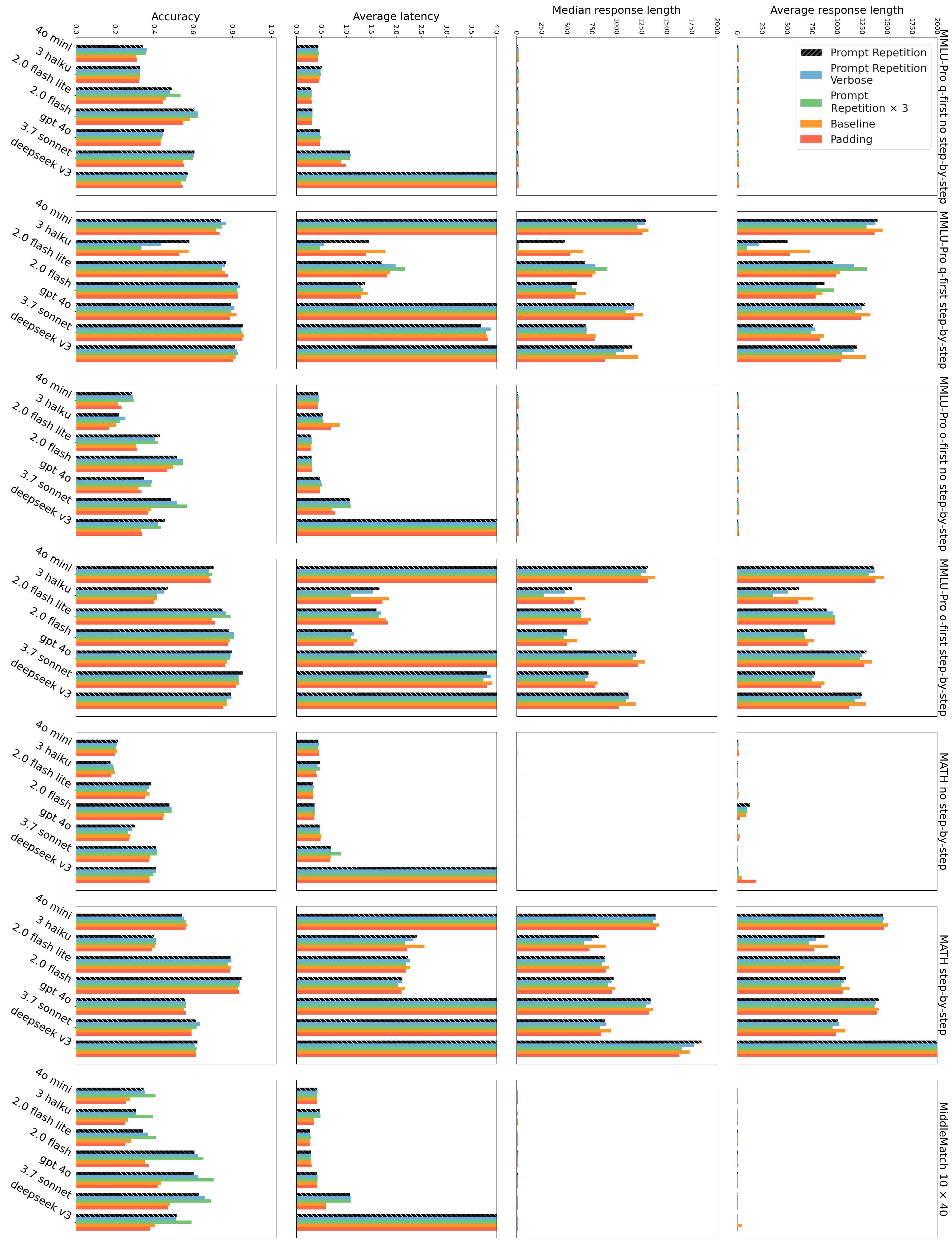
各手法とベンチマークにおける精度、平均・中央値の応答長、および平均レイテンシの比較詳細データです。
処理時間やコストは増えないのか
ここで皆さんが懸念するのは「入力を2倍にしたら、処理時間やコストも2倍になるのではないか?」という点でしょう。しかし、ここがこの論文の最も面白い部分であり、エンジニアにとっての朗報です。
結論から言えば、この手法はレイテンシ(待ち時間)をほとんど増加させません。なぜなら、LLMの処理は「Pre-fill(入力処理)」と「Generation(出力生成)」の2段階に分かれているからです。入力を読み込むPre-fill段階は並列処理が可能で非常に高速です。一方で、私たちが待ち時間を長く感じるのは、トークンを逐次生成するGeneration段階です。
プロンプト繰り返しは、入力トークン数を増やしますが、これは高速なPre-fill段階の負荷が増えるだけです。モデルが出力する回答の長さ(Generation)は、プロンプトを繰り返しても変わらないことが実験で示されています。実際に計測されたレイテンシのグラフを見ても、ベースラインとプロンプト繰り返し手法の間で、処理時間に大きな差は見られません。
つまり、ユーザーから見れば「待ち時間は変わらないのに、回答だけが賢くなっている」という状態が作れるのです。これは実運用を考える開発者にとって、追加の計算リソースや待ち時間をユーザーに強いることなく性能を底上げできる、まさに「フリーランチ(タダ飯)」に近い技術と言えます。
今すぐ最大6つのAIを比較検証して、最適なモデルを見つけよう!
推論モデルでの効果は限定的
もちろん、万能というわけではありません。この手法が真価を発揮するのは、モデルに「推論(Reasoning)」をさせない、つまり即座に回答を求める場合です。「ステップ・バイ・ステップで考えて」といった指示を与えて推論を行わせる場合、モデルは回答生成プロセスの中で自ら情報を反芻し、整理する時間を持ちます。そのため、入力段階での繰り返しの効果は薄れ、結果は「中立からわずかにプラス」程度に落ち着きます。研究チームのデータでも、推論ありのケースでは28のテスト中、勝ちは5つ、負けが1つ、残りは引き分け(有意差なし)となっています。
推論モデルでは、繰り返しテクニックを使っても劇的な効果はないが、やっても損はないという感じでしょうか。
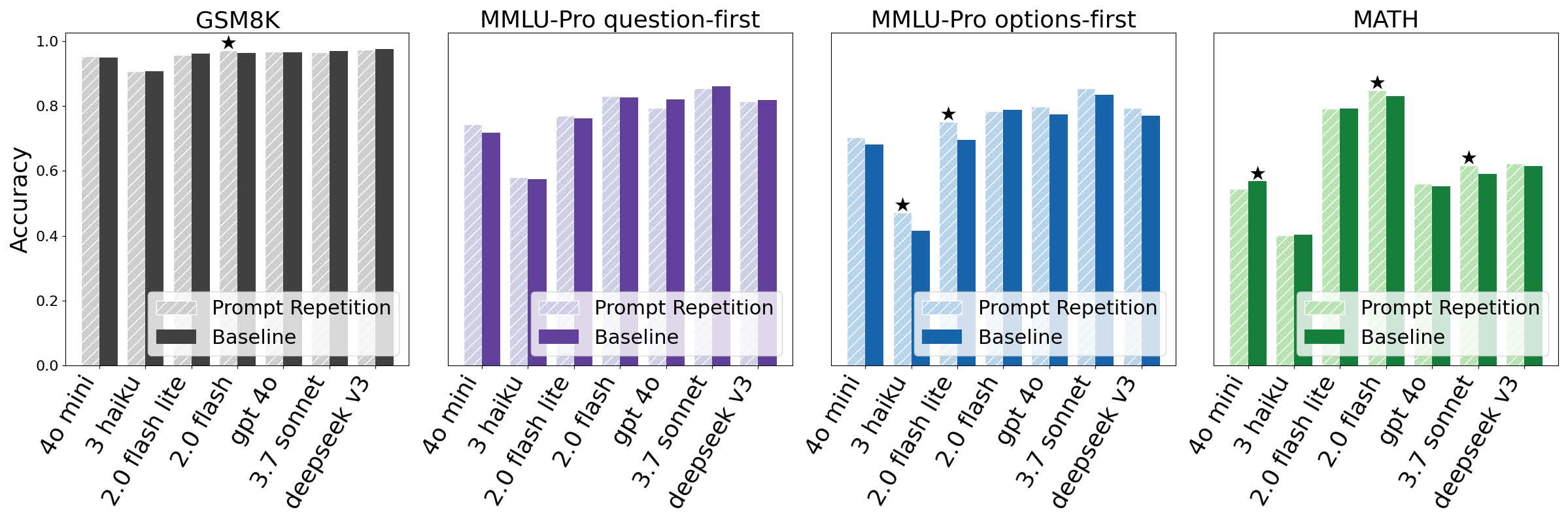
ステップ・バイ・ステップの思考を促した場合の、プロンプト繰り返しとベースラインの精度比較です。
3回繰り返すとさらに効果が上がるケースも
しかし、さらに興味深い実験結果もあります。プロンプトを2回ではなく「3回」繰り返す(Prompt Repetition x3)というバリエーションです。一部のタスク、特に先ほどの「NameIndex」や「MiddleMatch」(リストの中から特定の条件の要素を見つけるタスク)では、3回繰り返すことでさらにスコアが向上することが確認されました。
人間でも、難しい本は2回より3回読んだほうが理解できるのと全く同じ理屈が、最新のAIでも起きているというのは、なんとも親近感を覚える話ですね。一方で、単純に「....」のような意味のない文字で埋めて長さを揃える「Padding」手法では効果が出なかったことから、やはり「内容を繰り返す」こと自体に意味があることが証明されています。
まとめ
Google Researchが示した「Prompt Repetition」は、入力プロンプトを単に2回繰り返すだけという単純な手法です。しかし、その効果は大きく、特に即答性が求められる非推論タスクにおいて、コストやレイテンシを犠牲にすることなく精度を向上させることができます。
LLMの最先端モデルが、まるで人間のように読み直しによって理解を深めるというのは興味を惹かれますね。AIの回答が的を射ないとき、複雑なプロンプトエンジニアリングを駆使する前に、まずは単純に「指示をコピペして2回貼り付けてみる」ことをおすすめします。案外、それが手っ取り早い解決策になるかもしれません。
解説画像
