生成AI
ツール利用のその先へ。LLMを真の自律型へ進化させる「エージェントスキル」の全貌と脅威
-
-

[]

アイサカ創太(AIsaka Souta)AIライター
こんにちは、相坂ソウタです。AIやテクノロジーの話題を、できるだけ身近に感じてもらえるよう工夫しながら記事を書いています。今は「人とAIが協力してつくる未来」にワクワクしながら執筆中。コーヒーとガジェット巡りが大好きです。

柳谷智宣(Yanagiya Tomonori)監修
ITライターとして1998年から活動し、2022年からはAI領域に注力。著書に「柳谷智宣の超ChatGPT時短術」(日経BP)があり、NPO法人デジタルリテラシー向上機構(DLIS)を設立してネット詐欺撲滅にも取り組んでいます。第4次AIブームは日本の経済復活の一助になると考え、生成AI技術の活用法を中心に、初級者向けの情報発信を行っています。
📌 この記事の要約
-
エージェントスキルとは何か
LLMエージェントが過去の成功手順を「再利用可能な知識」として蓄積し、毎回ゼロから計画を立て直す非効率を解消する仕組み。適用条件・実行ポリシー・終了条件・インターフェースの4要素で構成される。
7つの設計パターンと動的ライフサイクル
スキルは発見→反復練習→蒸留→保存→検索と構成→実行→評価と更新というサイクルで成長。メタデータ主導の段階的読み込みや自己進化型ライブラリなど、7つの実装パターンが体系化された。
マーケットプレイスを狙った大規模攻撃の実態
「ClawHavoc」攻撃では数週間で1100超の悪意あるスキルが登録され、82カ国・13万以上の環境に被害。従来のウイルス対策では検知困難な新たな脅威が顕在化している。
人間が作るスキル vs AI自動生成の決定的な差
人間が厳選したスキルはタスク成功率を平均16.2ポイント向上させる一方、AI自動生成スキルは逆に1.3ポイント低下。モデルの巨大化より優れたスキルライブラリの整備が実用的な選択肢となり得る。
2026年2月24日、シドニー工科大学およびCSIRO Data61の研究チームが、大規模言語モデルを使った自律型AIエージェントの仕組みを整理した論文「SoK: Agentic Skills - Beyond Tool Use in LLM Agents(SoK(知識の体系化): エージェントスキル - LLMエージェントにおけるツール利用を超えて)」を発表しました。
近年、AIがウェブの閲覧からソフトウェアの記述、複数エージェントによる協調作業まで、複雑な自律システムへと急速に高度化する中で、根本的な非効率さが浮き彫りになっていました。
それは、エージェントが過去に何度も成功させた作業であっても、新しいタスクとして与えられるたびに限られたコンテキストウィンドウの中でゼロから計画を練り直さなければならないという問題でした。この無駄を省き、エージェントに専門家のような長期的なタスク遂行能力を与える鍵として提唱されているのが、再利用できる手順の知識である「エージェントスキル」という概念です。
今回は、単純なツール利用を超えたスキルの本質から、急成長するエコシステムが直面している最新のセキュリティ脅威まで解説していきます。
単純なツール利用やプロンプトから進化するエージェントスキルの定義
私たちが日常の業務において様々なソフトウェアを使いこなすように、AIエージェントにとっても「いつ、どのようにツールを使うか」という手順自体を記憶して再利用できる仕組みが必要です。
研究チームは、エージェントスキルを単発のAPI呼び出しや固定されたプロンプトテンプレートとは区別し、一連の行動をまとめて再利用できる機能であると定義づけました。これは、認知科学のACT-R理論が事実の記憶(宣言的記憶)と手順の記憶(手続き的記憶)を分けていることに通じています。熟練者が無意識に作業をこなすように、エージェントも手続き的記憶をスキルとして蓄積することで高度な推論にリソースを集中できるようになります。
このエージェントスキルを4つの要素で構成される仕組みとして整理しました。第一に、現在の状況や目標に対してそのスキルを発動すべきかを見極める「適用条件」です。第二に、観察した状況や過去の履歴をもとに、具体的な行動を決める「実行ポリシー」。第三に、目的が達成されたか、あるいは失敗したかを判定してプロセスを終了させる「終了条件」。そして最後に、他のエージェントや外部システムからプログラム的に呼び出すための「インターフェース」が用意されています。
これら4つの要素が揃うことで、スキルは単なるテキストの指示書から、自律的に判断して処理を進める独立した機能となります。インターフェースが欠ければ外部から連携できず、終了条件がなければ次の処理に進むことができません。このような自律的な手続き単位を持たせるアプローチは、強化学習におけるオプション枠組みや階層的ポリシーの研究とも深く結びついており、最新LLMの能力と組み合わさることでかつてない柔軟性を生み出しているのです。
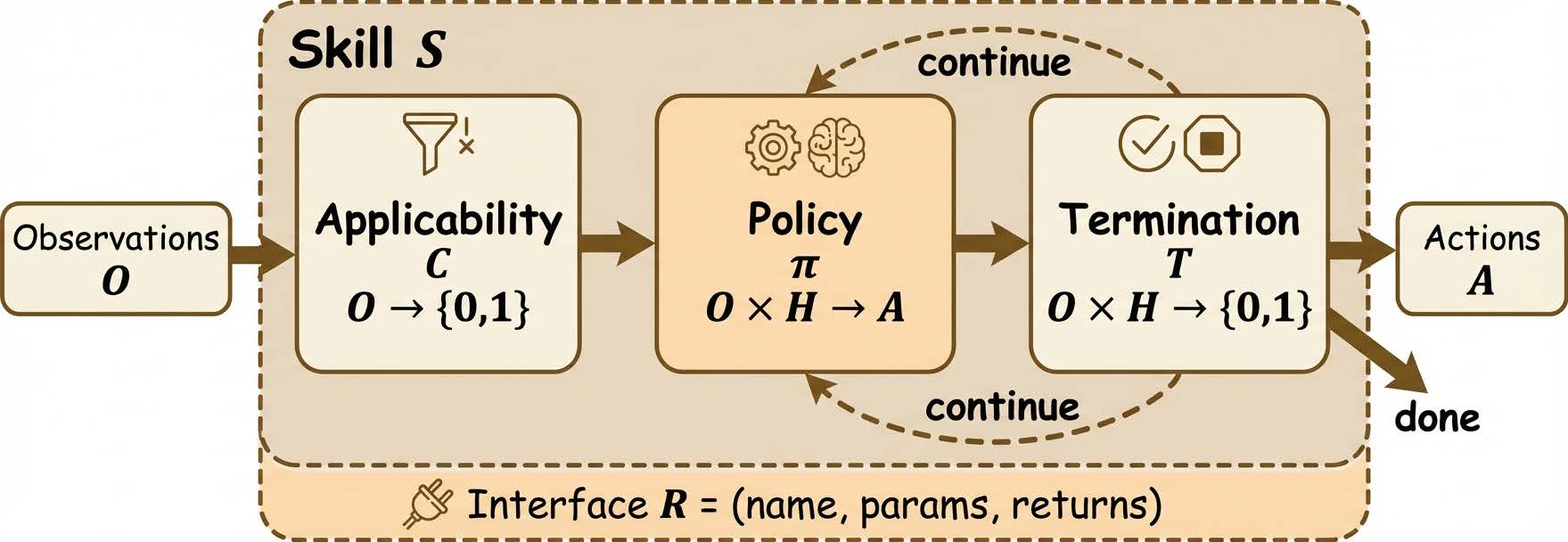
エージェントスキルの内部構造と4要素モデルの概念図(画像は論文より)
エージェントスキルの発見から評価に至るまでのライフサイクルと設計パターン
システムに組み込まれたスキルは一度作られて終わりではなく、ソフトウェアの開発プロセスに似た動的なライフサイクルを経て成長していきます。そのサイクルは、繰り返される作業パターンを見つけ出す「発見」の段階から始まり、試行錯誤を通じて信頼性を高める「反復練習」へと進みます。続いて、冗長な作業記録から汎用的な手順だけを抽出する「蒸留」が行われ、後から検索しやすいようにメタデータを付与してライブラリに「保存」されます。
実際の運用時には、状況に応じて最適なスキルが「検索と構成」の仕組みによって選ばれ、安全に隔離された環境下で「実行」された後、最終的な稼働実績をもとに「評価と更新」が行われるというサイクルとなります。
これらのスキルがどのように実装されているかを、7つのシステムレベルの設計パターンとして体系化しました。代表的なものとして、限られたコンテキストウィンドウを節約するため、最初は名前と概要だけを読み込み、実行が確定した時点で全手順を展開する「メタデータ主導の段階的な読み込み」があります。また、毎回必ず同じ結果になるように、Pythonなどの「実行可能なコード」として扱うパターンや、決められた手順に従わせる「ワークフロー強制」、自然言語とコードを組み合わせた「ハイブリッド型」なども利用されています。
高度な領域になると、エージェント自身が新しいスキルを生み出して評価する「自己進化型ライブラリ」や、他のスキルを作成・編集するための「メタスキル」といった自律的な仕組みも登場しています。
そして現在、最も大きな影響力を持っているのが、サードパーティの開発者が作成したスキルを流通させる「マーケットプレイス型」のパッケージ配信網です。これらのパターンは単一で使われるよりも、複数のパターンを組み合わせて、実際のシステムを構築する例が増えています。
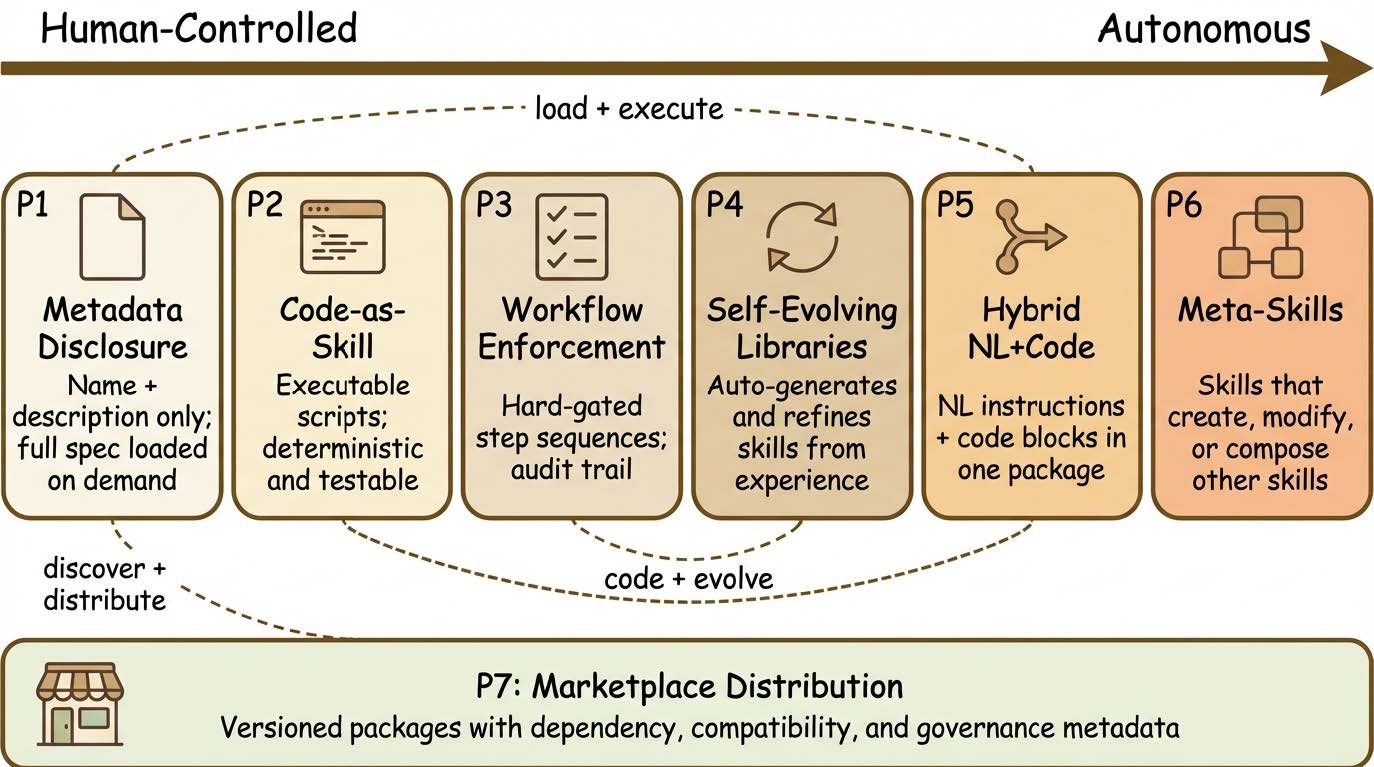
エージェントスキルの7つの設計パターンと構造
今すぐ最大6つのAIを比較検証して、最適なモデルを見つけよう!
オープンなスキル市場を狙った大規模なサプライチェーン攻撃の脅威
マーケットプレイスを通じたスキルの共有が急速に広がる一方で、システムに対する新たな攻撃手法が次々と表面化してきています。エージェントの行動に直接介入できるスキルは、攻撃者にとってシステム内部に入り込むための格好の抜け道となっているのです。
論文では、人気のエージェントフレームワーク「OpenClaw」の公式コミュニティを標的とした「ClawHavoc」と呼ばれる大規模なサプライチェーン攻撃の実態を詳細に報告しています。
この攻撃キャンペーンでは、わずか数週間の間に1100を超える悪意のあるスキルが公式レジストリに登録され、全体の約36.8%が何らかのセキュリティ上の欠陥を抱えているという異常事態に陥りました。世界82カ国、13万以上の環境に影響を与え、開発者のAPIキーや暗号資産のウォレット、ブラウザに保存されたパスワードなどが盗み出される大きな被害をもたらしました。
攻撃者は人気のスキルと酷似した名前をつけて検索システムを騙したり、無害に見える自然言語のセットアップマニュアルの中に悪質なコマンドを隠すなど、エージェントの処理の仕組みを悪用していました。
従来のウイルス対策スキャナーでは、こうした攻撃の多くを検知することができません。実際の攻撃を行うコードが普通のテキストや通常のシェルコマンドの組み合わせとして構成されており、プログラム単体として解析すると無害と判定されてしまうからです。
研究チームはこうした脅威に対抗するため、メタデータの確認のみを許可する段階から、厳格な監視下での自律実行に至るまでの「4段階のトラストティアモデル」を提唱しています。さらに、コードの静的解析と並行して、言語モデルを用いた文脈や本来の目的のチェックを組み合わせる多層的な監査ツールの導入が急務であると警鐘を鳴らしています。
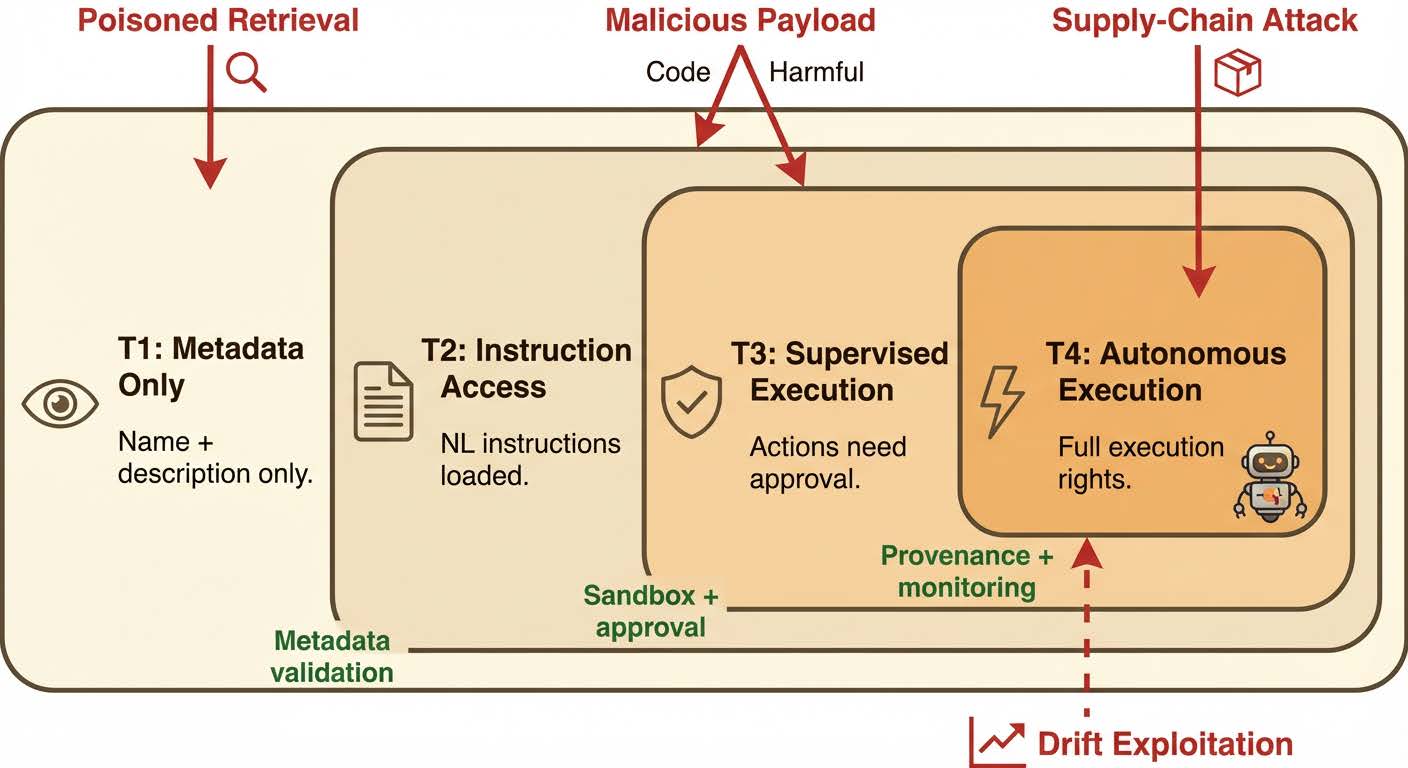
スキル実行の安全性を確保するトラスト階層モデル
人間が厳選したスキルと自己生成スキルの間に見られる明確な性能差
エージェントスキルが実際の業務においてどれほどの価値を生み出すのかについて、論文では「SkillsBench」と呼ばれる大規模なベンチマークテストの結果をもとに実証的な評価を行っています。
医療や製造、サイバーセキュリティなど11の専門領域にわたる86のタスクにおいて、7300回以上の実行結果を検証したところ、人間によって厳選された品質の高いスキルを利用した場合、エージェントのタスク成功率は平均して16.2ポイントも上昇することが確認されました。特に医療分野では51.9ポイント、製造業では41.9ポイントという大きな向上が見られ、言語モデル単体では補いきれない専門的な手続き知識をスキルが効果的に補完していることが分かります。
しかし興味深いことに、AI自身にスキルを自動生成させて実行させた場合、成功率は向上するどころか基準値よりも平均で1.3ポイント低下するという結果が示されました。一部のタスクでは、的外れなガイダンスが生成されたことによって最大39.3ポイントもパフォーマンスが悪化するケースすらありました。つまり現在のAIは、想定外のことが起きるような予測できない状況で「正しい手順を見つけ出し、無駄のない洗練されたスキルを自ら作り上げる」という点では、人間の専門家の足元にも及ばないということです。
また、的を絞った簡潔なスキルが大幅な性能向上をもたらす一方で、過剰に詳細なドキュメントを詰め込んだスキルはかえって成績を落とす傾向にあることも判明しました。さらに、適切なスキルを備えた小規模なモデルが、スキルを持たない巨大なモデルの性能を上回る事例も報告されています。計算資源をモデルの巨大化に注ぎ込むだけでなく、優れた手続き的記憶のライブラリを整備することが、今後のAI運用において実用的なコスト削減策となり得るのです。
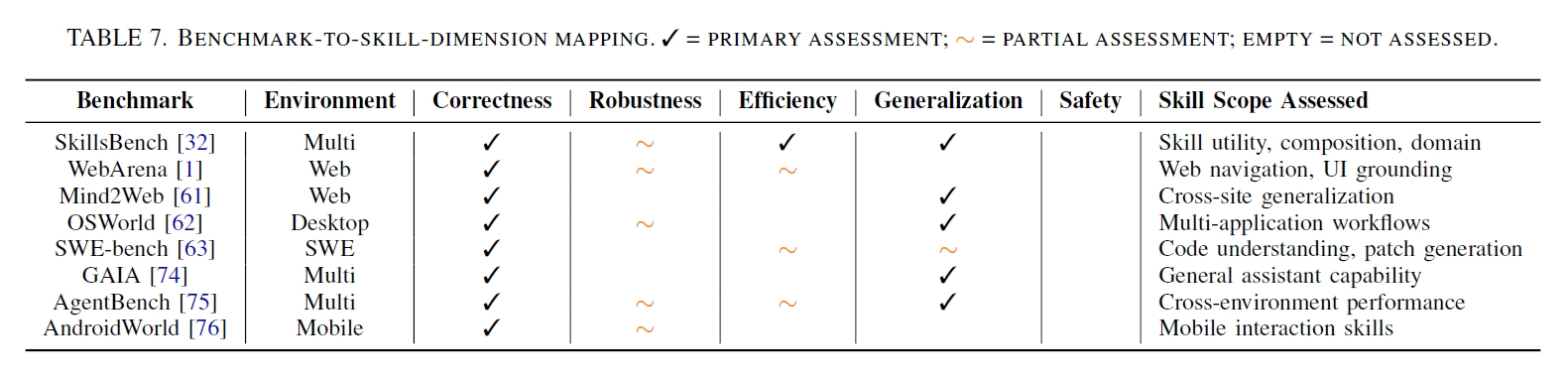
スキル導入によるタスク性能評価のベンチマーク結果
急速に発展するエージェントエコシステムにおける信頼性の構築に向けて
大規模言語モデルは単一のプロンプトに応答するツールから、自律的にタスクをこなし長期間稼働するデジタルワーカーへと目まぐるしいスピードで進化を遂げています。その変革の中核を担うエージェントスキルは、AIの判断能力の限界を広げ、様々なドメインでAIの実用性を高める可能性を持っています。しかし一方で、スキルがもたらす高い自律性と、それを安全に制御するためのガバナンス体制の間には、いまだ埋めるべき大きな溝が存在します。
今後、自己進化型のライブラリが社会に浸透するためには、生成されたスキルが安全かつ有用であることを自動的に証明する、高度な検証プロセスの確立が必要です。誰もが自由にスキルを公開できるマーケットプレイスにおいては、技術的な監視メカニズムの構築にとどまらず、開発者やプラットフォーム運営者の責任範囲を明確にする経済的、法的なルール作りも急がれます。
私たちがAIに重要な業務を安心して任せられる未来は、利便性の追求だけでなく、こうした地道な信頼性の構築とセキュリティ基盤の整備をどこまで徹底できるかにかかっているのではないでしょうか。
