

- 【著者プロフィール】 相坂ソウタ あいさか そうた AIライター
- こんにちは、相坂ソウタです。AIやテクノロジーの話題を、できるだけ身近に感じてもらえるよう工夫しながら記事を書いています。今は「人とAIが協力してつくる未来」にワクワクしながら執筆中。コーヒーとガジェット巡りが大好きです。
無料で使えるハイエンドのAIモデル「Gemini 2.5 Pro Experimental」の性能が凄い
Google DeepMindが2025年3月に発表したGemini 2.5シリーズは、従来モデルを大きく超える推論力とコーディング能力を備えた次世代AIモデルです。Gemini 2.5は回答を出す前に一度「思考(推論)」する思考型AIモデルとして設計されており、複雑な問題にも高い正確性で対処できるのが特徴です。Gemini 2.0 Flash Thinking(2024年12月公開)で初めて導入された「思考プロセス生成」機能を、Gemini 2.5では全モデルに統合する予定です。
本記事では、Gemini 2.5シリーズの概要とフラッグシップモデルである「Gemini 2.5 Pro Experimental」(以下、Gemini 2.5 Pro EXP)の技術的特徴や他のAIモデルとの比較と今後の展望について詳しく解説します。
3月25日、もっとも知的なAIモデルGemini 2.5シリーズが発表されました。
Gemini 2.5シリーズの構成とGemini 1.5からの進化
現在(3月29日時点)、Gemini 2.5シリーズの初期ラインナップとしてGemini 2.5 Pro EXPが公開されています。将来的には効率重視の軽量版など、Pro/Flashのような複数モデル展開が予想されますが、現時点ではPro Experimental版のみが提供されています。
Gemini 1.5世代(2024年2月発表)ではGemini 1.5 Pro(マルチモーダル対応のMixture-of-Experts型巨大モデル)とGemini 1.5 Flash(Proを蒸留した高速モデル)が存在し、いずれも100万トークンの長大なコンテキストを扱える点が画期的でした。一方、Gemini 2.5ではベースモデルのアーキテクチャ強化と思考能力のネイティブ統合が図られており、推論精度と応答の一貫性が大幅に向上しているのが特徴です。
Gemini 2.5 Pro EXPは大規模なSparse Mixture-of-Expertsアーキテクチャを採用しているとみられ、Gemini 1.5 Pro同様に膨大なパラメータ数を持ちながら推論時には一部専門家ユニットのみ活性化することで計算効率を高めています(正確なパラメータ規模は非公開)。総合的に、Gemini 1.5から2.5への進化は、「マルチモーダル×長大コンテキスト」という土台に「思考するAI」という新要素を加え、モデル性能全般を底上げした形と言えるでしょう。
Gemini AdvancedからGemini 2.5 Pro EXPを利用できます。
Gemini 2.5 Pro Experimentalの技術的特徴
Gemini 2.5 Pro EXPはGemini 2.5シリーズの最上位に位置づけられる実験版のモデルで、現時点でGoogleが提供する中でもっとも高度な思考モデルとされています。以下、その主な技術的特徴を解説します。
・長大なコンテキストウィンドウ
Gemini 2.5 Proは100万トークンものコンテキストウィンドウをサポートし、まもなく200万トークンに拡張予定とされています。これは従来のGPT-4o(最大128kトークン)やClaude 3(200kトークン)を桁違いに上回る長さであり、書籍数十冊分に相当するテキストや巨大なコードベースを一度に読み込んで分析できることを意味します。
実際、開発者は複数のリポジトリにまたがる数十万トークンものコードをまとめて投入し、Gemini 2.5 Proがそれらを踏まえた設計提案を返す、といった利用例も報告されています。出力トークン長も最大6万4000トークンと大幅に拡大されており、大量のコード生成や長文の逐語翻訳にも対応可能です。
・ネイティブなマルチモーダル対応
テキストだけでなく音声・画像・動画・コードなど複数のデータ形式を直接入力として与えられるのもGemini 2.5 Proの大きな特徴です。例えば、画像内の物体を識別し位置座標を出力させたり、音声ファイルの内容を高度に正確に文字起こしした上で話者や言語をタグ付けしてJSON形式で返すことができます。
これらはネイティブマルチモーダルであるGeminiモデルならではの芸当であり、時間情報付きの音声書き起こしでは数ミリ秒単位でタイムスタンプを付与する高精度ぶりに驚きます。
なお出力可能なデータ形式は文章やプログラムコード、SVGなどテキスト表現できるものに限定されています。画像生成や音声合成はサポートされず、あくまで入力としてのマルチモーダル対応が中心です。
・「思考するAI」: 推論プロセスの統合
Gemini 2.5 Proは内部に思考・推論のステップを展開してから回答する仕組み(チェーン・オブ・ソート)を組み込んだモデルです。数学問題や論理パズル、コードのバグ修正といった一筋縄ではいかない問いにも安易に直感的な誤答を返すのを避け、より慎重で正確な回答が期待できます。
実際、「思考モード」で動作するモデルは追加計算と時間コストを払う分、論理性の要求されるタスクで高精度化できることがOpenAIのo1モデル(2024年9月発表)以来知られており、GoogleはGemini 2.0 Flash Thinkingで同様のアプローチを投入していました。
Gemini 2.5ではこの推論機構がデフォルトで組み込まれており、例えば多数決的なアンサンブルなど高コストな推論強化を行わずとも最新ベンチマークで最先端の成績を収めています。
・高度なコーディング能力とエージェント機能
Gemini 2.5 Proはコーディング性能も進化し、大規模なコードベースの理解・編集や自律的なツール実行が可能です。Gemini 2.5 Pro自身がPythonコードを実行してその結果を取り込みながら対話できるインタラクティブ環境(Google AI StudioやAPI経由)も提供されており、ユーザーが1行の指示を与えるだけでモデルが必要な関数を呼び出し、結果を反映した回答を生成する、といったエージェント的ツールとなっています。
Function callingやCode execution、Search groundingなどの機能をサポートしており、例えばインターネット検索で最新情報を取得したり、計算エンジンで数式を解いたり、データベースにクエリを投げるなどのサブタスクをモデル自身が発行できます。複雑な質問に対しても外部ツールを駆使して解を探し出すことが可能です。
コーディング面では、Gemini 2.5 Proは自身の思考モードと長大なコンテキストを活かし、プロジェクト全体を跨いだリファクタリングや機能追加もこなせます。
ベンチマークで見るGemini 2.5 Proの性能
Gemini 2.5 Pro EXPは各種ベンチマークで既存モデルを凌駕する成績を収めています。その実力をいくつかの指標で具体的に見てみましょう。
・学術知識・推論
長文脈理解(MRCR)は、128kトークンの状況で94.5%、さらに1Mトークンでも83.1%という極めて高い性能を維持し、GPT-4.5(64.0%)を大幅に超えています。また、より難度の高い新ベンチマークとして制定された「Humanity's Last Exam (HLE)」では18.8%というスコアを獲得し、OpenAIの推論特化モデルo3-mini(14%)やAnthropic Claude 3.7 Sonnet(8.9%)を引き離してトップに立ちました。
HLEは数千問に及ぶ幅広い領域の難問で構成され、既存の試験問題がモデル進化で簡単になり過ぎたことへの対策として作られた極めて難しいテストですが、その中でGemini 2.5が最高成績を残したことは特筆に値します。
さらに科学・医学分野の総合力を測るGPQAでは84.0%、数学分野の難問テストAIME 2025では86.7%という高い正答率を示し、いずれも従来モデルを数ポイント上回る最先端の成績を収めています。
プログラミング
ソフトウェア開発能力の評価ではやや混合した結果となっています。Gemini 2.5 Proは、コード編集タスクのベンチマークAider Polyglotで68.6%というスコアを記録し、OpenAI o3-miniやClaude 3.7を上回りました。このことから、コードのリファクタリングや差分適用といった編集系タスクに非常に長けていることがわかります。
一方、より包括的なプログラミング試験であるSWE-Bench Verifiedでは63.8%に留まり、Anthropic Claude 3.7 Sonnetの70.3%に次ぐ第2位となりました。Claude 3.7は一部領域でGeminiを上回る健闘を見せています。とは言え、Gemini 2.5も総合的には現行トップクラスのコーディング能力を持つと言えます。
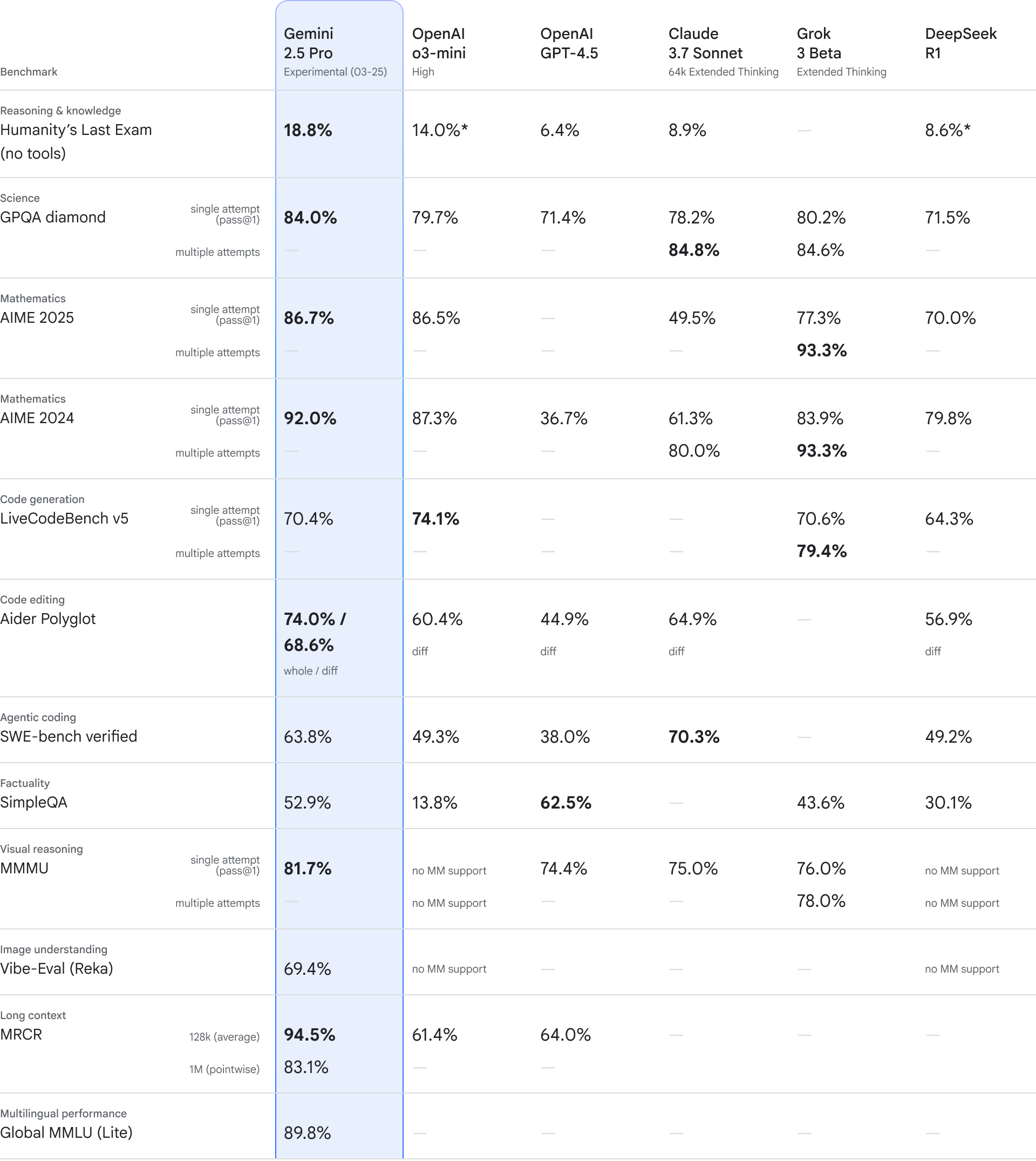
Gemini 2.5 Proと各AIモデルのベンチマークスコアです。画像はGoogleのブログより。
複数の評価領域をまたぐ総合力指標として注目されるのがChatbot Arena(LMSYS Chatbot Arena)のリーダーボードです。Gemini 2.5 Proはリリース直後に首位を獲得し、人間の評価において既存モデルに大差を付けました。
もっとも、一般的な科学・数学・コーディングのベンチマークでは既存トップモデルとの差は数%以内のスコアに収まっているケースも多く、各社の最先端モデルが拮抗し始めている状況もうかがえます。これはモデルの性能成熟に伴うベンチマークの飽和を示唆しており、新たな指標(HLEなど)の必要性が高まっている理由でもあります。
以上のように、Gemini 2.5 Proは学術知識、推論力、問題解決力、プログラミング力のいずれにおいても現在最高水準の性能を示しています。特に数学・科学分野の飛躍や、長文コンテキストを活かした難問対応力は大きなアドバンテージと言えます。ただし、ChatGPTやClaudeなどの競合にも強みがあり、すべての面で圧倒しているわけではない点には注意が必要です。
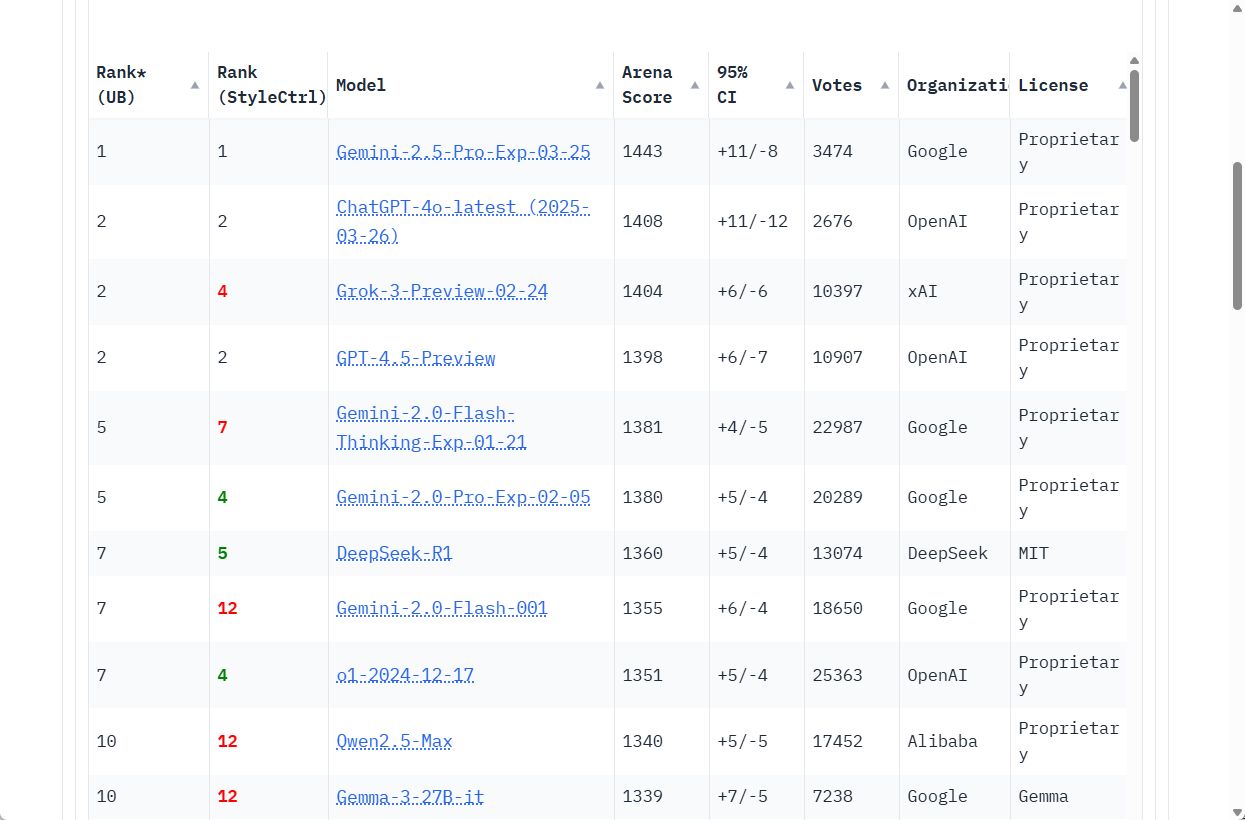
1443ポイントのスコアをたたき出し、Gemini 2.5 Pro EXPがトップを取りました。
Gemini 2.5 Pro EXPの実力を試してみた
Gemini 2.5 Pro EXPはGemini AdvancedやGoogle AI Studioで利用できます。今のところ、追加料金はかからず使えますが、今後本番運用する際の料金体系が発表される見込みです。
まずは、マルチモーダル機能を試してみましょう。先日開催された「GMOサイバーセキュリティ大会議&表彰式2025」のYouTube動画を読み込ませて、文字起こしをしてもらったところ、あっという間に生成されました。
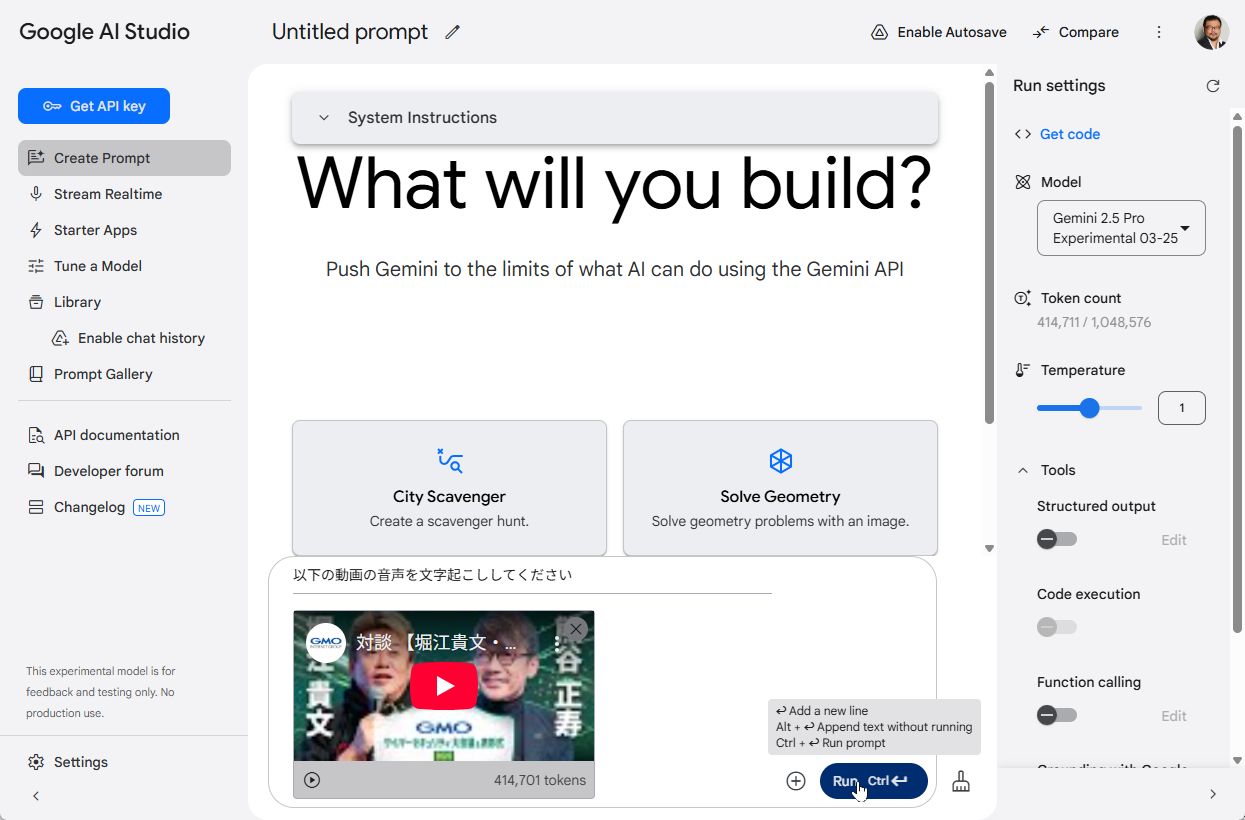
「Google AI Studio」でYouTubeの動画を読み込ませてみました。
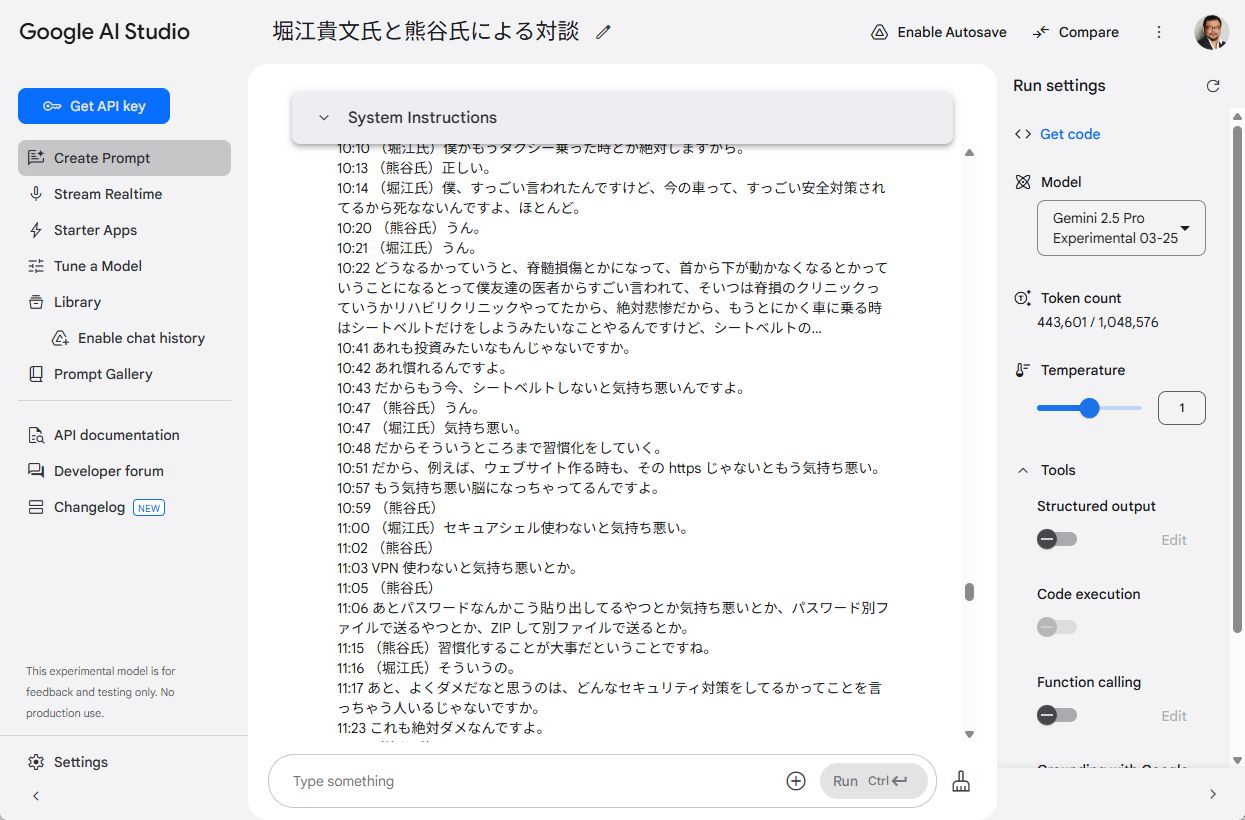
見事文字起こししてくれました。
コード性能を試すためにゲームを作ってもらいました。適切な指示文を作るのが難しいなら、それもAIで作ってもらいましょう。今回は、ハングマンというゲームを作ってもらいました。単語リストはRPG頻出ワードにするといった指示だけ追加し、作成してらうとサクッとコードが生成されました。Pythonで実行すると、あっけなくきちんとプレイできるゲームが実行できました。今回はシンプルなゲームでしたが、しっかりと指示すれば複雑なプログラムも開発できます。
Google DeepMindのYouTubeチャンネル(https://www.youtube.com/watch?v=RLCBSpgos6s&t;=1s&ab;_channel=GoogleDeepMind)では、もっと凝ったゲームを生成するデモが公開されています。
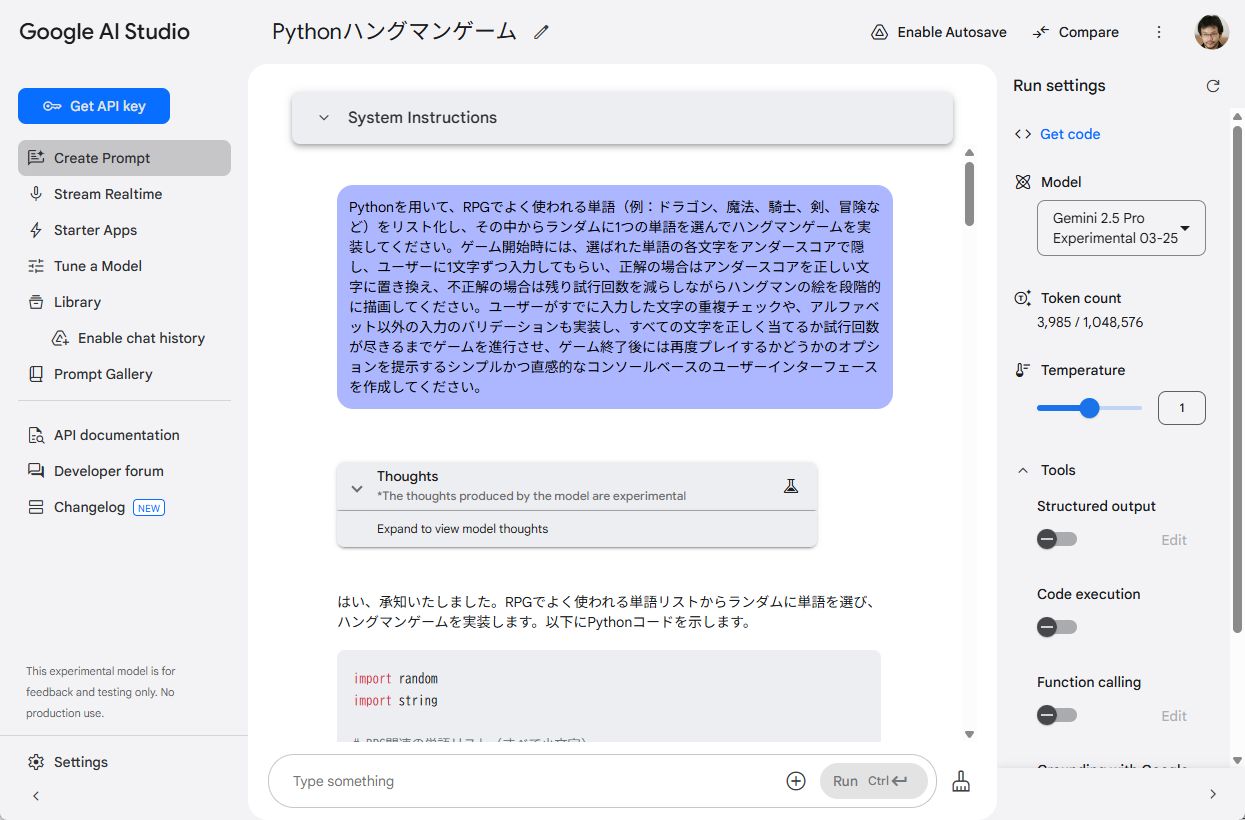
ゲームのコードを生成してもらいます。
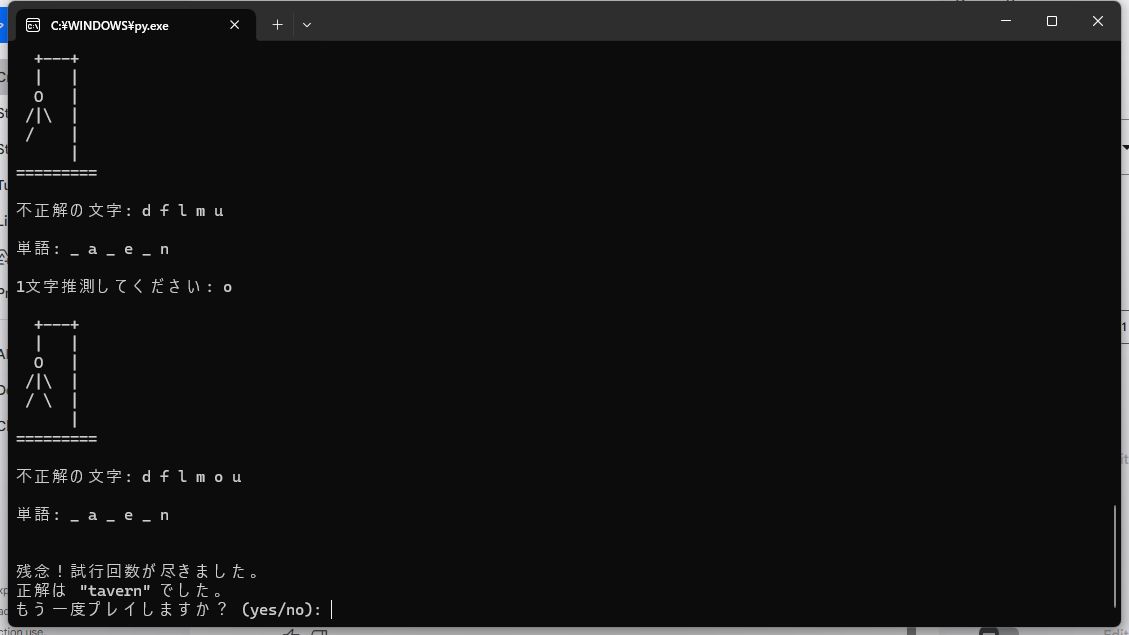
1発で動作するゲームが生成できました。
Gemini 2.5 Pro Experimentalはその名の通り先進的な機能を盛り込んだ実験的モデルですが、Googleは今後これを安定版へと磨き上げつつ一般提供していく予定です。実験版とはいえ既にGoogle AI Studio上で利用でき、月額約2900円のGemini Advancedプラン加入者はモバイルアプリなどからこのモデルにアクセスできます。ナレッジカットオフは2025年1月と新しく、実サービス投入目前の段階と言えるでしょう。興味があるなら、ぜひ触ってみましょう。その高性能振りに驚くこと請け合いです。
この記事の監修

- 【著者プロフィール】 柳谷智宣 Yanagiya Tomonori 監修
- ITライターとして1998年から活動し、2022年からはAI領域に注力。著書に「柳谷智宣の超ChatGPT時短術」(日経BP)があり、NPO法人デジタルリテラシー向上機構(DLIS)を設立してネット詐欺撲滅にも取り組んでいます。第4次AIブームは日本の経済復活の一助になると考え、生成AI技術の活用法を中心に、初級者向けの情報発信を行っています。