生成AI
Claude Opus 4.6が登場。100万トークン対応&コーディング性能大幅強化——1週間使い倒してわかった「本当に効く場面」
-
-

[]
- この記事の要点
- あなたはOpus 4.6に乗り換えるべきか?──30秒で判断する早見表
- 今すぐ乗り換えた方がいい人
- まだSonnet 4.5で十分な人
- 「で、結局何が変わったの?」──1週間フル移行して検証した
- 検証条件
- 基本スペック──前モデルとの比較
- 使って「これは変わった」と感じた新機能5つ
- 機能1:100万トークンのロングコンテキスト──文書分割の作業が消えた
- 機能2:アダプティブ思考──質問の難しさをAIが自動判断
- 機能3:出力量が倍増──長いレポートが途中で切れなくなった
- 機能4:Compaction──長い会話が途切れなくなった
- 機能5:Agent Teams──複数AIの並列稼働(リサーチプレビュー)
- ベンチマーク──数字と体感の両方で検証
- 公式ベンチマーク結果
- 私の体感(5日間の検証から)
- 料金の2段階構造──ここを見落とすと痛い目に遭う
- 通常利用(≤200Kトークン):前モデルと同額
- ロングコンテキスト(>200Kトークン):数倍のコスト
- コストを抑えるテクニック(API利用者向け)
- 移行で失敗しないための4つの注意点
- 失敗1:100万トークンを常に使おうとする
- 失敗2:assistant prefillingが突然動かなくなって焦る
- 失敗3:ロングコンテキスト料金を把握せずに大量データを投入
- 失敗4:ベンチマークの数字だけで移行を判断する
- まとめ:Opus 4.6は「コーディングと長文処理」で真価を発揮する
- 出典・参考リンク
【著者プロフィール】
佐藤傑(さとう・すぐる)
株式会社Uravation代表取締役。早稲田大学法学部在学中に生成AIの可能性に魅了され、X(旧Twitter)で活用法を発信(@SuguruKun_ai、フォロワー6万人超)。「生成AIガチ勢」として企業向け研修や開発支援を展開。Claude Opus 4.5のリリース初日から業務で使い続け、4.6も発表当日にフル移行して検証中。
この記事の要点
- Claude Opus 4.6は、Anthropicが2026年2月5日にリリースした最新フラグシップAIモデルです
- 一度に処理できる情報量が最大100万トークン(書籍3〜5冊分)に拡大し、長文の一括処理が可能になりました
- コーディング性能が大幅に向上し、Terminal-Bench 2.0で全モデル最高スコアを記録しています(Anthropic発表時点)
- 標準利用なら前モデルと同価格ですが、200Kトークンを超えるとロングコンテキスト料金が発生します
最終更新日:2026年2月9日
※本記事の情報はAnthropicの公式発表に基づいています。料金やベータ提供条件は変更される場合があります。
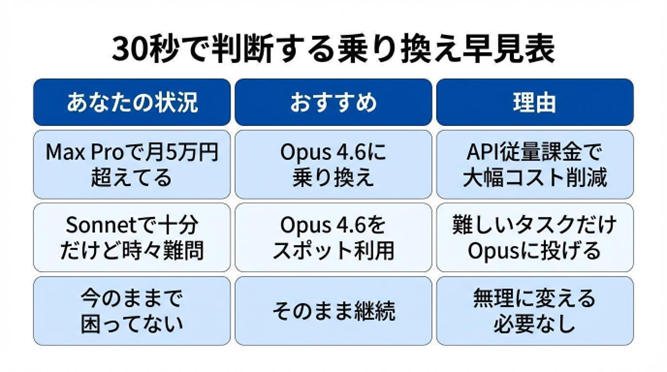
あなたはOpus 4.6に乗り換えるべきか?──30秒で判断する早見表
記事を読む前に、まずここをチェックしてください。
今すぐ乗り換えた方がいい人
- Claude Codeで毎日コーディングしている → コーディング性能の向上を直接享受できる
- 20ページ以上の長文(技術文書、法務書類等)を一括処理することが多い
- 複雑な推論・分析タスクが業務の中心
まだSonnet 4.5で十分な人
- 日常的なチャットやQ&Aが中心 → 体感差はほぼゼロ
- コスト効率を重視したい → Sonnetは入力$3/出力$15でOpusの約60%の価格
- レスポンス速度を最優先したい → Opusは回答に時間がかかる場面がある
私の使い分け: コーディングと長文分析はOpus 4.6、日常のチャットやメール下書きはSonnet 4.5。この組み合わせが今のところベストです。
モデル選択の使い分けイメージ
「で、結局何が変わったの?」──1週間フル移行して検証した
正直に言います。AIモデルの新バージョンが出るたびに「また数字が上がっただけでしょ?」と思いますよね。私もそうでした。
先日、顧問先の開発チームから「Opus 4.5を使ってるんですけど、4.6にした方がいいですか?」と聞かれたんです。ベンチマークの数字を見せるだけじゃ答えにならない。だから実際に1週間、自分の業務をOpus 4.6に全切り替えしてみました。
検証条件
- 期間:2026年2月5日〜2月9日(5日間)
- 利用環境:Claude.ai Pro + Claude Code + API(直接呼び出し)
- 主なタスク:コードレビュー、研修資料作成、長文Q&A、メール下書き、データ分析
- 比較対象:同じタスクをOpus 4.5 / Sonnet 4.5でも実行し、品質・速度・コストを比較
結論:「コーディング系のタスク」と「長文を一括で扱うタスク」は明らかに変わった。日常チャットは体感差ほぼゼロ。
基本スペック──前モデルとの比較
コンテキストウィンドウ(一度に扱える情報量):
- Opus 4.5:20万トークン
- Opus 4.6:20万トークン(標準)/ 100万トークン(ベータ)
最大出力:
- Opus 4.5:6.4万トークン
- Opus 4.6:12.8万トークン(倍増)
料金(100万トークンあたり、≤200K):
- 入力:$5 / 出力:$25(前モデルと同額)
モデルID:
- Opus 4.5:claude-opus-4-5-20251101
- Opus 4.6:claude-opus-4-6
「トークン」はAIがテキストを処理する単位です。日本語だとおおよそ1文字=1〜2トークン。100万トークンは書籍換算で3〜5冊分の分量です。
(出典:Anthropic公式ブログ「Introducing Claude Opus 4.6」、Claude API料金ページ)
今すぐ最大6つのAIを比較検証して、最適なモデルを見つけよう!
使って「これは変わった」と感じた新機能5つ
機能1:100万トークンのロングコンテキスト──文書分割の作業が消えた
これが一番インパクトがありました。
以前、研修資料を作るときに30ページの技術文書を読み込ませようとして「長すぎて入りません」とエラーが出た経験はありませんか? 私はしょっちゅうでした。文書を3分割して、それぞれにコンテキストを要約して渡して...めちゃくちゃ面倒だったんです。
Opus 4.6ではこれが一発。100ページ超の文書をそのまま投げて質問できる。
実際に試したケース:
「この技術仕様書(87ページ)を読んで、セキュリティ要件に関連する箇所をすべて抜き出し、優先度順にまとめてください」
以前なら分割+要約+統合で1時間かかった作業が、10分で完了しました。
長文の読み取り精度も向上しています。100万トークンの文脈から特定の情報を見つけ出す精度テスト(MRCR v2)では76%を記録。前世代のSonnet 4.5が18.5%だったので、実用的な水準に達しています(出典:Anthropic公式ブログ)。
ただし、利用条件があります:
- ベータ版として提供。すべてのユーザーが利用できるわけではない
- API利用の場合、Tier 4以上が目安
- Claude.aiではPro / Teamプラン以上
- 200Kトークンを超える利用はロングコンテキスト料金が適用される(後述)
- フル活用時のレスポンスは30秒〜1分かかることがある
「長ければ長いほど良い」わけではありません。日常チャットは20万トークンで十分。100万は「本当に必要なとき」だけ使うのがコスパ的に正解です。私は週に2〜3回程度しか使いません。
機能2:アダプティブ思考──質問の難しさをAIが自動判断
「今日の天気は?」と「M&A案件のリスク分析をして」では、必要な思考の深さがまったく違いますよね。
Opus 4.6のアダプティブ思考(Adaptive Thinking)は、この判断をAI自身がやってくれます。簡単な質問にはパッと即答、複雑な問題にはじっくり考えてから回答。
私の体感:
- 「今日のスケジュール確認して」→ 2秒で回答(以前と同じ)
- 「このコードのバグを見つけて修正して」→ 「考え中...」表示後、10秒で的確な修正案
思考プロセスが可視化されるのも大きい。「なぜこの結論になったのか」が見えるので、クライアントへの説明時にそのまま根拠として使えます。
⚠️ API利用者への重要注意: アダプティブ思考が有効だとassistant prefillingが使えません。既存のプロンプト設計でprefillingに依存している場合、Opus 4.6に切り替えた途端に動かなくなります。私は最初これで半日ハマりました。移行前にテスト環境で必ず確認してください。
機能3:出力量が倍増──長いレポートが途中で切れなくなった
前モデルでは最大6.4万トークンだった出力が、12.8万トークンに倍増。
「詳細なレポートを書いて」と頼んだら途中で切れた経験ありませんか? あの「続きを書いて」の手間がなくなりました。
助かった場面:
- 研修用の50ページ分のQ&A集を一括生成
- 技術文書の全章の要約を一度に出力
- コードレビューでファイル全体の修正版を一気に返してもらう
地味ですが、毎日使う機能だけに効果がデカい改善です。
機能4:Compaction──長い会話が途切れなくなった
Claude Codeで長時間コーディングしていると、以前は「コンテキストの上限に達しました」と言われて会話がリセットされることがありました。
Opus 4.6のCompaction機能は、会話が長くなると過去のやり取りを自動的に要約して、コンテキストを圧縮してくれます。
実際の効果:
- Claude Codeで3時間連続のコーディングセッションが途切れずに継続
- 「さっき話した仕様」を覚えていてくれるので、毎回説明し直す必要がない
利用者側で何かする必要はゼロ。AIが勝手にやってくれます。Claude Codeでの長時間開発で特に威力を発揮します。
機能5:Agent Teams──複数AIの並列稼働(リサーチプレビュー)
Opus 4.6と同時に公開されたAgent Teams。これは複数のClaude Codeインスタンスをチームとして並列稼働させる機能です。
Anthropicのセーフガードチーム研究者Nicholas Carlini氏が、16のエージェントを並列稼働させてRustベースのCコンパイラを構築する実験を公開。約2,000セッション・$20,000のAPIコストで、Linuxカーネルをコンパイルできる10万行のコンパイラが生成されたとのこと。
まだリサーチプレビュー段階ですが、「AIチームに開発を任せる」未来が見え始めています。
ベンチマーク──数字と体感の両方で検証
公式ベンチマーク結果
Anthropicが公表している主な結果です(出典:Anthropic公式ブログ、2026年2月5日)。
コーディング:
- Terminal-Bench 2.0(ターミナルでのコーディング課題):65.4%(発表時点で全モデル最高)
- SWE-bench Verified(GitHubの実Issue解決):72.6%
推論:
- ARC-AGI 2(抽象推論能力):68.8%
ロングコンテキスト:
- MRCR v2(100万トークンからの情報検索):76%(Sonnet 4.5は18.5%)
総合:
- GDPval-AA:GPT-5.2を144 Elo上回る
私の体感(5日間の検証から)
明確に向上を感じたタスク:
- Next.jsのバグ修正 → エラーメッセージを貼るだけで原因特定→修正コードまでの精度が上がった
- リファクタリング → 以前は微妙な変更が多かったが、本当に改善される修正が増えた
- 20ファイルにまたがるプロジェクトの全体像把握 → 正確性が向上
体感差がほぼなかったタスク:
- 簡単な関数生成、翻訳
- 日常的なQ&A、メール下書き
ベンチマークの数値はあくまで標準化されたテスト環境での結果です。自社のユースケースでテストしてから移行判断するのが鉄則です。

出典:Anthropic公式ブログ ベンチマーク比較表
料金の2段階構造──ここを見落とすと痛い目に遭う
通常利用(≤200Kトークン):前モデルと同額
| 項目 | 料金(100万トークンあたり) |
| 入力 | $5 |
| 出力 | $25 |
| キャッシュ入力 | $0.50(書き込み$0.625) |
ロングコンテキスト(>200Kトークン):数倍のコスト
200Kトークンを超える入力を使うと、ロングコンテキスト料金が適用されます。
「100万トークン使っても同じ値段」ではありません。
具体的にどれくらい変わるのか、ケースで示します:
ケース1:普通のチャット(入力5K+出力2K)
- コスト:入力$0.025 + 出力$0.05 = 約$0.08/回
- → 普段使いではほぼ気にならないレベル
ケース2:長い文書を読ませてQ&A(入力150K+出力5K)
- コスト:入力$0.75 + 出力$0.125 = 約$0.88/回
- → 標準料金の範囲内。まだ安心
ケース3:100万トークンをフル活用(入力800K+出力50K)
- コスト:ロングコンテキスト料金が適用され、標準の数倍
- → 1回の処理で$10〜20以上になる可能性。事前に公式料金ページで確認必須
(出典:Anthropic API料金ページ)

料金体系の概要
コストを抑えるテクニック(API利用者向け)
- プロンプトキャッシュ:頻繁に使うシステムプロンプトをキャッシュ → 入力コスト最大90%削減
- バッチ処理:リアルタイム応答が不要なら、バッチAPIで料金50%OFF
- モデル使い分け:日常タスクはSonnet 4.5(入力$3/出力$15)、重要タスクだけOpus
Claude.aiの有料プラン(固定料金):
- Pro(月額$20)─ Opus 4.6を含む全モデル利用可能。まず試すならここから
- Team(月額$30/人)─ 管理機能付き
移行で失敗しないための4つの注意点
失敗1:100万トークンを常に使おうとする
やりがち:「せっかくだから全部長文で」と何でも100万トークンモードにする
正解:レスポンス時間とコストを考えると、日常使いは20万トークンで十分。100万は「本当に必要なとき」だけ。私は週に2〜3回程度しか使いません
失敗2:assistant prefillingが突然動かなくなって焦る
やりがち: Opus 4.5のプロンプトをそのまま4.6に流用して「動かない!」
正解:アダプティブ思考が有効だとprefillingが使えません。APIヘッダーでthinking設定を確認。私はこれで半日ハマりました。テスト環境で事前検証を
失敗3:ロングコンテキスト料金を把握せずに大量データを投入
やりがち: 「100万トークンだ!全データぶち込め!」→ 月末の請求額に青ざめる
正解:200K超は料金が跳ね上がる。まずは小さいデータで料金感を掴んでからスケールアップ。ケース3の試算を参考に
失敗4:ベンチマークの数字だけで移行を判断する
やりがち: 「Terminal-Bench 65.4%だから即移行!」
正解:自社の実際のユースケースでテストしてから判断。私の場合、Q&Aは体感差なし、コーディングは明確に向上。用途によって判断が分かれます
まとめ:Opus 4.6は「コーディングと長文処理」で真価を発揮する
- 100万トークンのコンテキストはベータ版。Tier 4以上/Pro/Teamプランが必要
- コーディング性能は確実に向上。Terminal-Bench 2.0で全モデル最高スコア(Anthropic発表時点)
- 出力量が倍増し、Compactionで長時間セッションも安定
- 20万トークン以下の料金は据え置き。ただしロングコンテキストは数倍のコスト
- アダプティブ思考はassistant prefillingと相性が悪い。テスト環境で検証を
明日から試すなら、まずはこれ:
Claude.aiでモデル選択を「Opus 4.6」に切り替えて、普段のコードレビューか長めの文書のQ&Aを試してみてください。10分で「あ、確かに違う」と感じるはずです。
出典・参考リンク
- Anthropic公式ブログ「Introducing Claude Opus 4.6」: https://www.anthropic.com/news/claude-opus-4-6
- Claude API料金ページ: https://www.anthropic.com/pricing
- Claude Codeドキュメント: https://docs.anthropic.com/en/docs/claude-code
