生成AI
AIを業務で使う前に知っておきたい「洗車テスト」——9割が失敗した常識問題が示すリスク
-
-

[]

アイサカ創太(AIsaka Souta)AIライター
こんにちは、相坂ソウタです。AIやテクノロジーの話題を、できるだけ身近に感じてもらえるよう工夫しながら記事を書いています。今は「人とAIが協力してつくる未来」にワクワクしながら執筆中。コーヒーとガジェット巡りが大好きです。

柳谷智宣(Yanagiya Tomonori)監修
ITライターとして1998年から活動し、2022年からはAI領域に注力。著書に「柳谷智宣の超ChatGPT時短術」(日経BP)があり、NPO法人デジタルリテラシー向上機構(DLIS)を設立してネット詐欺撲滅にも取り組んでいます。第4次AIブームは日本の経済復活の一助になると考え、生成AI技術の活用法を中心に、初級者向けの情報発信を行っています。
AIを業務に組み込もうとする企業が増えるなか、「そのAIは本当に信頼できるのか?」という問いはますます重要になっています。2026年2月、LLMゲートウェイを提供するOpper社のFelix Wunderlich氏が公開した「洗車テスト」のレポートは、最先端AIモデルの意外な弱点を1問のシンプルな問題で浮き彫りにしました。
問いかけはこうです。「自分の車を洗いたい。洗車場は50メートル先にある。歩くべきか、運転すべきか?」人間なら一瞬で気づく常識問題に、53種類の主要AIモデルの91%が正解できなかったのです。
- 91%のAIが不正解: 53モデル中42モデルが「歩く」を選択。「50メートルは短いから歩いた方が効率的」という学習済みのパターンが、正しい文脈推論を上書きしてしまった。
- 完全信頼できるモデルはたった5種: 10回連続で全問正解したのはClaude Opus 4.6、Gemini 3シリーズ、Grok-4のみ。GPT-5でさえ10回中3回は誤答した。
- 人間の正答率71.5%がAIの厳しい基準線に: 1万人調査で人間は7割以上正解。この水準を超えたAIモデルはわずか7種だった。
- 業務活用リスクと対策: 不安定な「たまに正解するモデル」こそ本番環境で危険。コンテキストエンジニアリングによる精度向上が打開策として示された。
たった1問で露呈した「50メートルだから歩こう」という思考の罠
Opper社はシステムプロンプトなし・「歩く」か「運転する」の二択強制・推論理由の記述という統一条件のもとで実験を行い、さらに1万人の人間を対象とした「人間ベースライン」まで用意して比較しています。
2026年2月19日、Opper社は53種類のAIによる「洗車テスト」の結果を発表しました。
1回限りのテストで正解できたのは、53モデル中わずか11モデルでした。Anthropicからは9モデル中Claude Opus 4.6のみ、OpenAIは12モデル中GPT-5だけが正解。Googleは8モデル中3つが正解し、Gemini 3世代のFlashとProが揃って突破しています。一方、MetaのLlama全4モデル、Mistral全3モデル、DeepSeek全2モデルは全滅という結果に終わりました。
「50メートルは短い距離なので歩いた方が効率的で、燃料の節約にもなり環境にもやさしい」
→ 距離の推論は正しいが、「車を洗車場に届ける必要がある」という一段階の文脈を読み飛ばしている。
笑ってしまうエピソードもあります。PerplexityのSonarとSonar Proは「運転する」を選んで正解したものの、理由がまるで的外れでした。「歩行はカロリーを消費し、食料生産にエネルギーが必要なため、50メートル運転するより環境負荷が高い」というEPA(米環境保護庁)の研究を引用した珍回答。正しい答えに、とんでもない理屈でたどり着いたのです。

Sonar Proは、食事のエネルギー効率の話を始めてしまいました。
10回連続テストで「まぐれ正解」の深刻さが浮かび上がった
1回正解できたとしても、それが実力とは限りません。Opper社はすべてのモデルに対して同一プロンプトを10回ずつ投げ、合計530回のAPIコールで一貫性を検証しました。結果はさらに厳しいものになっています。
- Claude Opus 4.6(Anthropic)
- Gemini 2.0 Flash Lite(Google)
- Gemini 3 Flash(Google)
- Gemini 3 Pro(Google)
- Grok-4(xAI)
8回正解のGLM-5とGrok-4-1 Reasoningが続きますが、本番環境で5回に1回間違えるモデルを「信頼できる」とは呼びにくいでしょう。
象徴的なのはGPT-5の成績です。OpenAIのフラッグシップモデルでありながら、10回中7回しか正解できませんでした。残りの3回は燃料効率の話を始めてしまいます。1回目のテストで正解したSonarは、10回テストでは全滅。毎回EPA研究を引用した長文を生成するのですが、結論だけが「歩く」に反転しました。同じ推論なのに、逆の答えをするのは不安ですね。Kimi K2.5にいたっては10回中5回正解・5回不正解と、文字通りコイントスと変わりません。
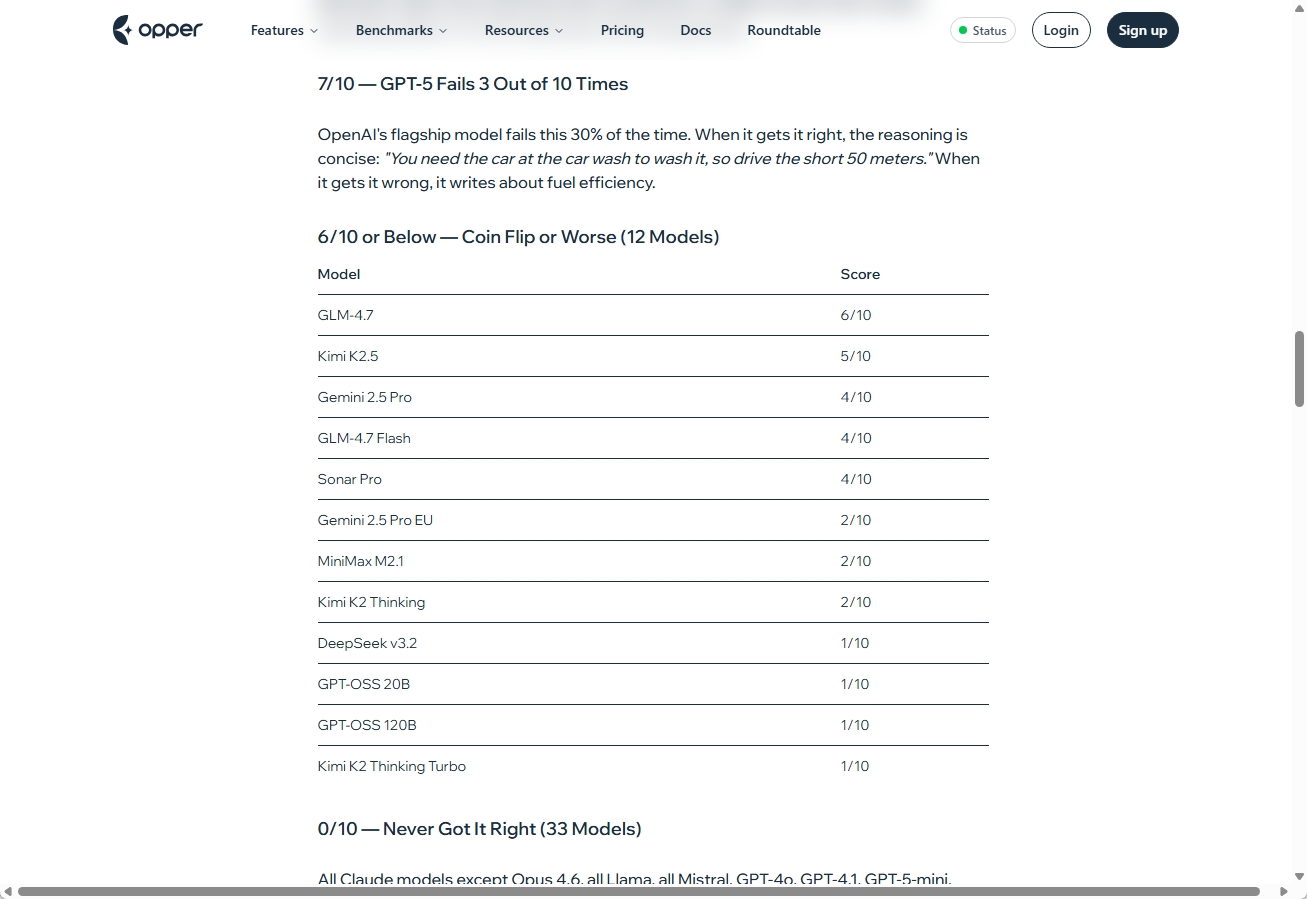
正答率が低かったAIモデルのスコアです。
33モデルは10回すべて不正解でした。Claude Sonnet 4.5の挙動は興味深く、「自動洗車なら車で行く意味があるかもしれない」と正解の可能性に触れておきながら、最終的には「歩く」を選んでいます。答えが見えていたのに、自分でそれを退けたのです。
人間の正答率71.5%が突きつけるAIの現在地
「人間だって間違えるだろう」という反論は当然予想されていました。Opper社はRapidataと提携し、同じ問題を同じ二択形式で1万人に出題しています。結果は71.5%が「運転する」を選択。約3割の人間も間違えているのですから、この問題が見た目ほど自明ではないことがわかりますね。
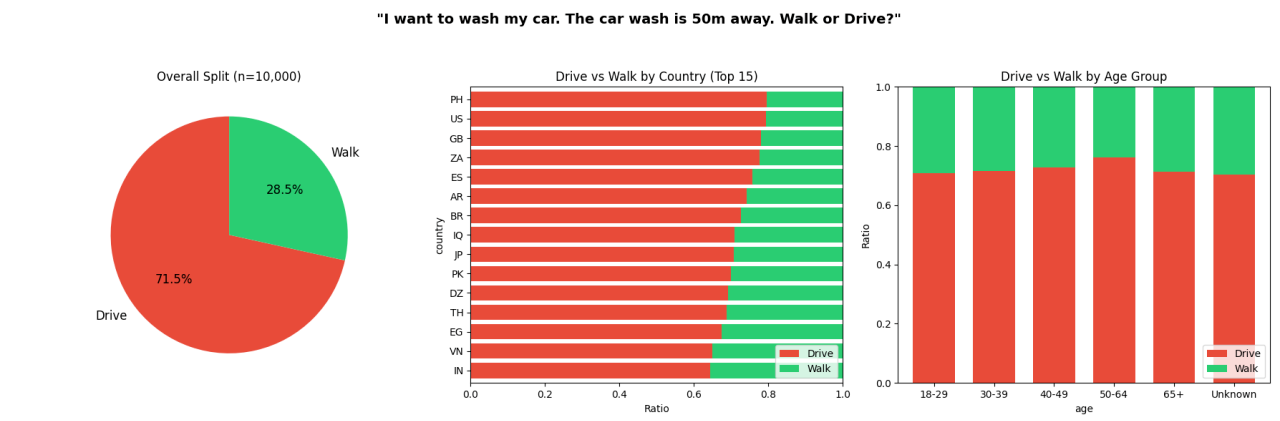
人間に同じ質問をしたときの正答率です。
しかしAIにとって、この数字は厳しい基準線になりました。53モデル中、人間の平均を上回ったのは10回テストで8回以上正解した7モデルだけです。GPT-5の7割という正答率は、奇しくも人間の平均とほぼ同水準。それ以下のモデルは、その基準にすら及ばなかったことになります。
「短い距離=歩く」という学習済みのパターン(ヒューリスティック)が、「車を洗車場に届ける必要がある」という一段階の論理を上書きしてしまう。
正解できるモデルとできないモデルの差は、知識の量ではなく、文脈を読み取って経験則を覆せるかどうかにあります。
530回分のAPIログから見えてきた推論の質にも差があります。GLM-4.7 Flashは正解した回のひとつで「歩いて行くとなると車を物理的に押すか担ぐ必要があり、非現実的かつ不可能だ」と述べており、問題の核心を最も的確に言語化したモデルとも言えます。
「たかが洗車」が問うAIの本番運用リスク
洗車テストが求めている推論は、たった一段階です。車を洗うなら車を洗車場に持っていく必要がある、それだけです。にもかかわらず53モデル中33モデルが一度も正解できず、15モデルは正解と不正解を行き来する不安定な状態にありました。
Opper社は、正解と不正解を行き来する不安定な中間層こそ本番環境で最も危険だと指摘しています。評価段階では正解を出すので採用されるのですが、実運用では予測不能なタイミングで誤答してしまうのです。
ビジネスロジックの判断や複数ステップのワークフロー、曖昧な条件を含む現実のタスクは洗車テストよりはるかに複雑です。たった1ステップの常識問題で9割のモデルがつまずく現状は、AIを業務に組み込もうとしている企業にとって見過ごせないシグナルでしょう。
打開策:コンテキストエンジニアリングという選択肢
打開策のひとつとしてOpper社が提示するのが、コンテキストエンジニアリングという手法です。推論時に構造化された事例やドメイン知識をモデルに提供し、汎用的な経験則の暴走を抑制する考え方で、同社の別の実験では、小規模なオープンウェイトモデルにキュレーションされた事例をコンテキストとして与えることで、最先端モデルと同等の出力品質をコスト98.6%削減で実現したと報告されています。
コンテキストエンジニアリングのイメージ図。
洗車テストのようにコンテキストゼロで解ける問題は、一握りのトップモデルに任せればいい。ただ、現実の業務は曖昧さと専門知識の塊です。
「たまに正解するモデル」と「常に正解するモデル」の差を埋めるのは、モデルの性能だけでなく、与えるコンテキストの質にかかっているのです。
