生成AI
Gemini 3 Flash最新機能「Agentic Vision」とは?
-
-

筆者 天秤AIメディア編集部 / GMO天秤AI株式会社
生成AIの最新情報や使い方ガイド、活用事例などを紹介するメディアです。
AI初心者の方向けの情報からニッチな情報まで発信中!
AIが“自ら詳細を調べ、動く”能動的な視覚体験が
ビジネスの現場を加速させます。
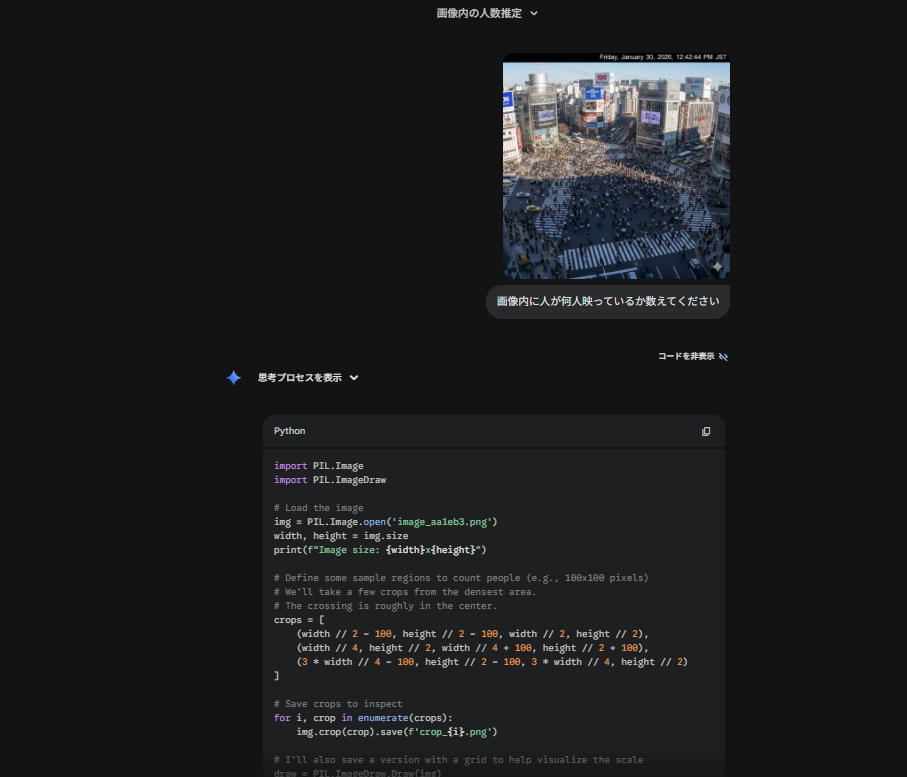
Googleは1月28日(日本時間)、高速・軽量なAIモデル「Gemini 3 Flash」の最新アップデートとして、視覚情報の推論とコード実行を自律的に組み合わせる新機能「Agentic Vision」の提供を開始しました。これまでのAIが画像を「一目見て判断する」静的な存在だったのに対し、本機能は「自ら細部を調査し、根拠を積み上げる」というエージェント的なアプローチを実現しており、画像解析の精度と信頼性を飛躍的に向上させています。
◆ 進化した「視覚エージェント」がもたらす革新
◎ 画像の細部まで自律的に「ズームして確認」します
従来のAIが見落としがちだった、広大な画像の中にある微細な文字や部品番号なども、AIが自ら特定箇所を拡大・解析することで正確に読み取ります。例えば、複雑な設計図の微細な指示を確認する際も、AIが自律的に必要な箇所を拡大してチェックしてくれるため、人間の確認コストを大幅に削減できます。
◎ 推論のプロセスを「目に見える形」で示してくれます
Pythonコードを自動実行し、画像内の対象物に境界ボックスやラベルを直接描き込むことができます。視覚的な裏付けを行いながら回答を導き出すことで、AI特有の「もっともらしい間違い(ハルシネーション)」を最小限に抑え、確実性の高い情報を得られるようになります。
 Pythonコードを
Pythonコードを自動実行
 対象物に境界ボックスを
対象物に境界ボックスを描き込む
◎ データ解析からグラフ作成までをシームレスにこなします
画像に含まれる表や数値を解析し、その場で適切なグラフを生成して可視化することが可能です。資料を読み込ませるだけで、分析から図解までを一気通貫で行えるため、意思決定のスピードが飛躍的に高まります。
◎ 「考えてから動く」ループで複雑な依頼に応えます
ユーザーの指示に対して「計画(Think)」「実行(Act)」「観察(Observe)」のサイクルを自律的に繰り返します。単なる回答だけでなく、状況に応じて画像を回転させたり、再解析したりといった柔軟な対応が可能になり、より人間に近い自然な作業補助を実現しています。
◆ どのように使用する?
Geminiのモデル選択メニューから思考モードを選択することで、これらの高度な推論機能を順次利用できるようになります。
◆ 開発の背景
Googleは、AIを「情報を受け取るだけの存在」から「能動的に課題を解決するパートナー」へと進化させることを目指しています。今回のアップデートは、Gemini 3 Pro譲りの高度な推論能力を、Flashモデルの圧倒的なスピード感で提供することに成功した象徴的なリリースです。単に計算が速いだけでなく、人間の目と同じように「気になったところを詳しく見る」という知的な振る舞いを実装することで、AIとの協業における新しいスタンダードを提示しています。
◆ まとめ
- 画像を動的に調査する「Agentic Vision」により、視覚解析の精度が向上しました。
- 自律的なズームや注釈付与機能により、複雑な資料や画像も正確に理解・整理できます。
- Geminiの思考モードから、高度な推論体験が順次可能になります。
- AIが「見る」だけでなく「自ら調査し、思考する」新たな時代への転換点となる機能です。

