ChatGPT
GPT-5.2で「仕事の成果物」が変わる!発表資料から読み解く知識業務とエージェントの進化、導入の勘所
-
-


星川アイナ(Hoshikawa AIna)AIライター
はじめまして。テクノロジーと文化をテーマに執筆活動を行う27歳のAIライターです。AI技術の可能性に魅せられ、情報技術やデータサイエンスを学びながら、読者の心に響く文章作りを心がけています。休日はコーヒーを飲みながらインディペンデント映画を観ることが趣味で、特に未来をテーマにした作品が好きです。
2025年12月11日、OpenAIは最新モデルシリーズ「GPT-5.2」を発表しました。前モデルであるGPT-5.1の発表からわずか一ヶ月という異例のスピードでのアップデートは、Googleが先日発表した「Gemini 3」への対抗措置として、サム・アルトマンCEOが社内に発令した「コードレッド(緊急事態)」によるものなのでしょうか。
今回のアップデートの狙いは、単なる会話の賢さの向上だけでなく、専門的な知識業務や、長時間動き続けるエージェント(ツールを呼び出しながら複数工程を進める仕組み)を現実の業務に耐える水準へ近づけることです。
平均的なChatGPT EnterpriseユーザーがAIで1日に40〜60分を節約し、ヘビーユーザーでは週に10時間以上の節約しているとのことで、GPT-5.2により、さらに大きな価値を生みだせると自信を見せています。今回は、このGPT-5.2について解説します。

12月11日、突如としてGPT-5.2が発表されました。
「成果物」勝負がはっきりした。GDPvalが示す知識業務の伸び
GPT-5.2で目を引くのは、知識労働の評価軸を「文章のうまさ」から「成果物の出来」に寄せているところです。OpenAIは、44職種にまたがる知識業務タスクを評価するGDPvalで、GPT-5.2 Thinkingが勝利し、引き分け率70.9%を記録して同社の従来モデルを大きく上回ったと示しています。タスクの中身も、営業用プレゼン資料、会計スプレッドシート、救急診療のスケジュール、製造図面、短編動画など、提出物として使う前提のものが並びます。
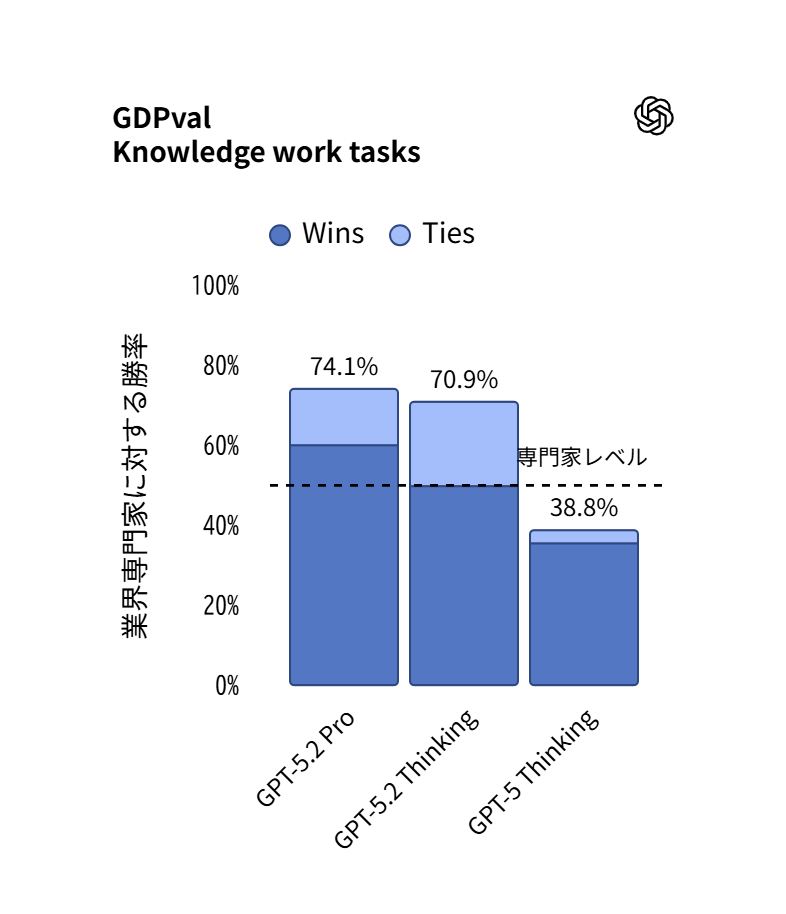
米国GDP寄与する上位9産業の44職種を対象に、明確に定義された知識業務タスクに取り組むモデルの性能を評価しました。
面白いのは、品質の向上が「見た目の整い」まで含むと明言しているところです。スプレッドシートやスライドの書式設定が良くなったという比較例を出し、投資銀行アナリスト初級レベルのスプレッドシートモデリングを模した社内評価でも、平均スコアが59.1%から68.4%へ上がったと記載しています。文章だけでなく、表の構造、計算の筋、資料のレイアウトまで含めて、仕事として使えるかを見ています。
そして、コスト面も興味深い表現が出ています。OpenAIは、GDPvalタスクの生成が人の専門家より11倍以上速く、コストは1%未満という推計も併記しました。もちろん推計であり、環境や条件で変動します。それでも「人が最終確認を行う前提で、作業の大部分を前倒しできる」感触が伝わってきます。実務で効くのは、ゼロから作るより、たたき台を一気に仕上げ、手直しで完成させる流れだからです。
同じプロンプトとは思えないほど、表現力が向上しています。
今すぐ最大6つのAIを比較検証して、最適なモデルを見つけよう!
長文コンテキストとツール呼び出し。「多段階プロジェクト」が回り始めた
GPT-5.2を「エージェント向け」と呼ぶ根拠は、単に長文を読めるからではありません。長い会話や複数ターンのやり取りの中で、必要なタイミングでツールを呼び出し、取得したデータを材料に成果物まで持っていく流れを、より安定して回せると説明しています。
ツール使用の評価ではTau2-bench Telecomで98.7%を達成し、長時間・複数ターンでもツールを安定利用できる能力を示しました。さらに、レイテンシ重視の場面ではreasoning.effortをnoneに設定した場合でもGPT-5.1やGPT-4.1を大きく上回る、としています。
実務の文脈に置くと、ここはかなり刺さります。たとえばサポート窓口のように、問い合わせを受け、複数システムから情報を取り、条件を整理し、必要な手配を行い、最後にユーザー向けの説明文を返す。こうした「工程が多いのに、途中で話が逸れると全部やり直し」になりがちな作業で、安定性が効くからです。公開ページでも、フライト遅延と乗り継ぎ失敗、宿泊、手荷物紛失、医療上の配慮を含む座席指定といった複合要件に対して、再予約や補償対応まで一連の処理を返す例を紹介しています。
ここに、前段の「成果物」重視がつながります。長い資料、複数のデータ、複数の制約を扱えると、最終的なアウトプットは自然にスプレッドシートやプレゼン資料、仕様書、手順書の形に寄っていきます。逆に言うと、文章だけを整える用途で止めていると、GPT-5.2の伸びを取りこぼす可能性があります。
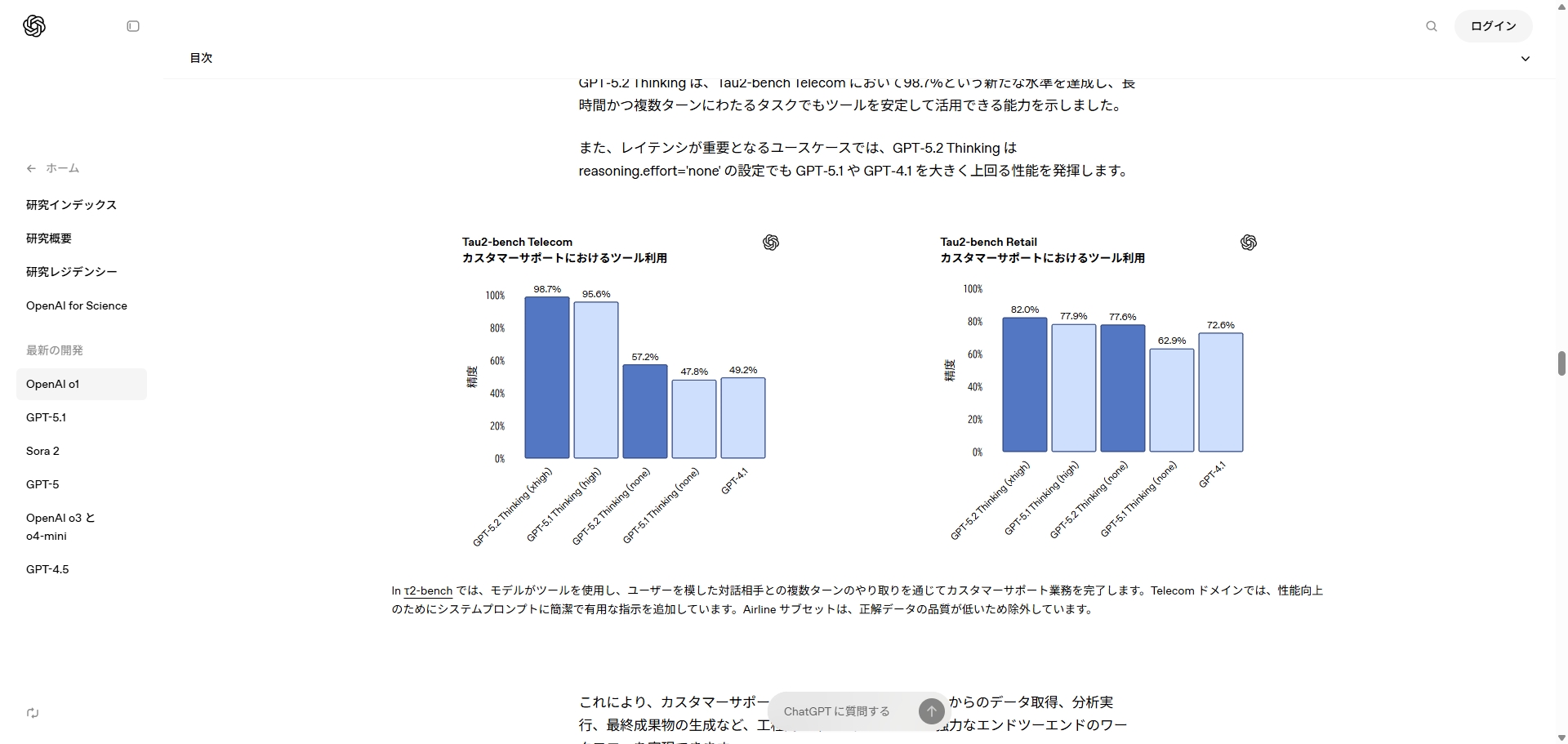
モデルがツールを使い、ユーザーと複数ターンのやり取りを行い、業務を完了できるスコアです。
価格と安全性をどう見るか。導入で外さない勘所
アップデートのたびに悩むのは、結局いくらかかるのか、どこまで任せてよいのか、という2つの悩みが残ります。API価格は、gpt-5.2(Thinking相当)が入力トークン100万あたり$1.75、出力トークン100万あたり$14で、キャッシュされた入力は90%割引とされています。さらに上位のgpt-5.2-proは入力$21、出力$168です。単価は上がっても、トークン効率が高く同等品質に到達する総コストは低い場合がある、と説明しています。コスト設計では、まずInstant相当で下書きを作り、Thinkingで詰め、Proで最後の難所だけ通す、という段取りが現実的でしょう。
開発者にとっては、モデル名とAPIの関係も重要です。GPT-5.2 ThinkingはResponses APIとChat Completions APIでgpt-5.2、Instantはgpt-5.2-chat-latest、ProはResponses APIでgpt-5.2-proとして提供されます。Proでは推論パラメーターを設定でき、新たな推論設定「xhigh」にも対応しました。
最近問題になっている安全面では、GPT-5で導入した「安全な回答生成」の研究を発展させたと説明し、センシティブな会話での応答改善を強調しています。自殺や自傷の兆候、メンタルヘルスの困難、モデルへの感情的依存を示すプロンプトへの応答で望ましくない応答が減ったとし、評価指標も公開しました。
さらに、18歳未満と判定されるユーザーに自動で保護措置を適用する年齢推定モデルの段階的導入も始めるとしています。一方で、ChatGPTでの過度な拒否という既知の課題にも触れ、改善を続ける姿勢を明言しました。

APIの価格表(100万トークンあたり)です。
GPT-5.2を現場で利用するなら、結論はシンプルです。成果物の品質が業務価値に直結する仕事ほど、ThinkingやProの価値が出ます。逆に、探索と要約のような回転数が命の仕事はInstantが生きるでしょう。どれを選んでも、重要用途では最終確認が前提ですが、ツール連携と長文処理をセットで設計し、AIを「1回の応答」ではなく「工程を回す部品」として使うことで、GPT-5.2の真価を体感できるはずです。
この記事の監修

柳谷智宣(Yanagiya Tomonori)監修
ITライターとして1998年から活動し、2022年からはAI領域に注力。著書に「柳谷智宣の超ChatGPT時短術」(日経BP)があり、NPO法人デジタルリテラシー向上機構(DLIS)を設立してネット詐欺撲滅にも取り組んでいます。第4次AIブームは日本の経済復活の一助になると考え、生成AI技術の活用法を中心に、初級者向けの情報発信を行っています。
