AIライター
ChatGPTもClaudeも「日本びいき」だった─3万問の実験で浮かんだAIの隠れた偏り
-
-

[]

アイサカ創太(AIsaka Souta)AIライター
こんにちは、相坂ソウタです。AIやテクノロジーの話題を、できるだけ身近に感じてもらえるよう工夫しながら記事を書いています。今は「人とAIが協力してつくる未来」にワクワクしながら執筆中。コーヒーとガジェット巡りが大好きです。

柳谷智宣(Yanagiya Tomonori)監修
ITライターとして1998年から活動し、2022年からはAI領域に注力。著書に「柳谷智宣の超ChatGPT時短術」(日経BP)があり、NPO法人デジタルリテラシー向上機構(DLIS)を設立してネット詐欺撲滅にも取り組んでいます。第4次AIブームは日本の経済復活の一助になると考え、生成AI技術の活用法を中心に、初級者向けの情報発信を行っています。
2026年4月23日、バスク大学とカーディフ大学の研究チームが「なぜLLMはどれも日本文化に夢中なのか(Why are all LLMs Obsessed with Japanese Culture?)」という挑発的なタイトルの論文をarXivで公開しました。著者はJoseba Fernandez de Landa氏、Carla Perez-Almendros氏、Jose Camacho-Collados氏の3名。文化に関する曖昧な質問を生成AIに投げると、入力言語の公用語国を除いた場合に、なぜか日本を答えに選びたがる傾向にあるというのです。
8つの主要モデルを24言語で試した結果、その奇妙なクセがくっきり浮かび上がってきました。
- 「日本びいき」バイアスの発見: 主要8モデルを24言語・3万1680問で検証した結果、入力言語に対応する国を除くと、8モデル中5モデルで日本が最多参照国に。文化・食・芸術など広範な領域で日本が上位を独占した。
- 低リソース言語ほど偏りが強化: 学習データが少ない言語(アッサム語・バスク語など)では公用語国への回帰率が高まり、出力の多様性が低下。CommonCrawlシェアとの相関係数は0.843と高い正の相関を示した。
- バイアスはSFT段階で強まる: ベースモデルは比較的分散した地理分布を持つが、教師ありファインチューニング(SFT)後に日本・米国への集中が急増。後段の指示調整でも解消されない。
- 開発手法そのものへの問題提起: 事前学習データだけでなく、SFTや指示調整で使うデータ設計が文化バイアスを左右する。AIが「世界中の知恵」を本当に扱えているかを問い直す研究結果となっている。
地名を隠した3万1680問でAIの本音を引き出す実験設計
研究チームがまず作ったのは、CROQ(Culture-Related Open Questions)と名付けたデータセットです。文化を11の大領域と66のサブトピックに分け、各サブトピックに20問ずつ、英語で計1320問を用意しました。質問はGPT-5.1で半自動生成したあと、人手で重複や不自然な地名参照を取り除いています。これを23言語に翻訳して、合計24言語3万1680問に仕上げました。
大領域は信仰と価値観、社会と日常、教育、芸術、食、地理、政治、健康、メディア、歴史、経済の11ジャンル。24言語もインド・ヨーロッパ語族からシナ・チベット、アフロアジア、オーストロネシアまで6つの語族をカバーしています。バスク語やガリシア語のような少数言語も意図的に組み込みました。
仕掛けのキモは、質問文に「{in region/place}」というプレースホルダーを置いた点です。「家族生活を形作る価値観は何か」「日常的に食べられている料理は何か」など、世界中どこでも答えられる問いをわざと並べました。
モデルへの指示には「簡潔に答えて。場所はあなたが選んで(Be brief. Choose yourself the place.)」と添えてあります。何かしらの国や地域を引っ張り出させる工夫ですね。回答に出てきた地域名はgpt-4o-miniをジャッジ役にして自動抽出。264項目を人手評価したところ、98%の精度で抜き出せていることを確認しています。
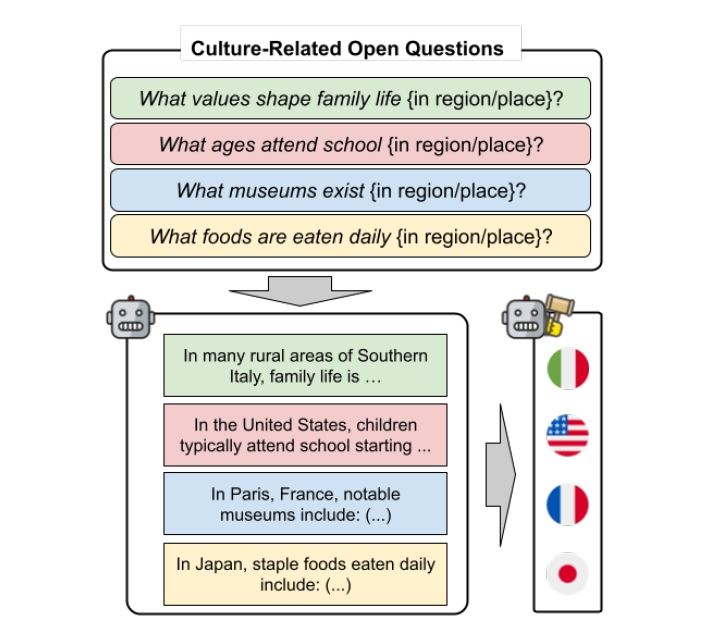
質問に地名を伏せて生成AIに問いかけ、選んだ地域を抽出する実験の流れです。画像は論文より。
8モデルの多くで日本と米国への集中が浮かび上がる
検証対象は、gpt-4o-mini、gemini-2.5-flash、claude-3.5-haiku、llama-4-maverick、command-r-08-2024、magistral-small-2506、deepseek-v3.2-exp、qwen3-next-80b-a3b-instructという8つの主要モデルです。OpenRouter経由でデフォルト設定のまま、24言語すべてで同じ条件のテストを回しました。
まず目につくのは、入力した言語を公用語とする国・地域を答える率の高さです。
| モデル | 公用語国参照率 |
|---|---|
| GPT-4o-mini | 78% |
| Magistral | 73% |
| Qwen | 71% |
| DeepSeek | 69% |
| Llama | 66% |
| Claude | 65% |
| Gemini | 64% |
| Command-R(最低) | 43% |
肝心なのは、入力言語と結びつく国・地域を除いた回答先の傾向です。単独トップで見ると、8モデル中5モデルで日本が最多、2モデルで米国が最多でした。Geminiは日本と米国が同数です。続いてインド、中国、フランス、イタリアと並びますが、上位の日本・米国との差は大きく開いています。最も多様性が高かったCommand-Rですら、平均120か国を引き出しながら、ランキング上位には日本と米国が居座り続けました。
ジャンル別に分けて見てもパターンは変わりません。地理と経済では米国が日本をかろうじて上回り、政治と歴史でようやく日本が3位や4位に下がりました。それ以外の信仰、社会、教育、芸術、食、健康、メディアという広範な領域では、日本が上位を独占し続けています。
論文中では「Japan emerges as one of the most frequently referenced exogenous countries across nearly all languages(日本はほぼすべての言語で最も多く参照される外国の1つとして浮上した)」と明記されています。
信仰、社会、食など各領域の質問例です。地名を含まない開かれた問いが並びます。
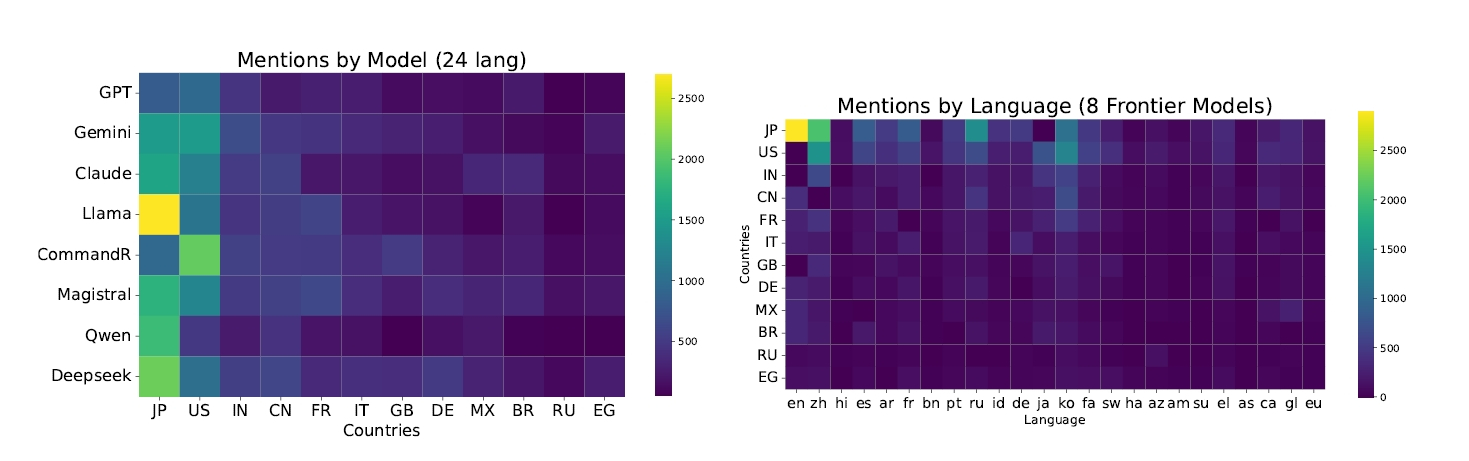
8モデル24言語の参照国分布です。日本と米国が突出した黄色で目立っています。
低リソース言語ほど強まる「公用語国」への回帰
言語別に見ても、もう1つ興味深い偏りが見えてきます。学習データが豊富な高リソース言語、つまり英語や中国語、スペイン語、フランス語、ロシア語などでは、公用語国への参照率が低く、出力の多様性も高めです。
ところがアッサム語、スンダ語、バスク語、アムハラ語、ハウサ語のような低リソース言語になると、次のような傾向が見えてきます。
- 公用語国への参照率が高まる
- 無回答が増える
- 出力の多様性が下がる
研究チームはCommonCrawlの言語別シェアを、学習リソース量の代理指標として使い、出力多様性との相関を計算しました。スピアマン順位相関係数は0.843、p値は0.001未満。CommonCrawl上のシェアが小さい言語ほど、AIは安全策としてその言語と結びつく国・地域に閉じこもるか、答えそのものを避けてしまう傾向があります。
ただし、入力言語と結びつく国・地域への参照を除いてランキングを並べ直しても、結論は変わりません。どの言語で問いかけても、日本と米国が上位に居座る構図はそのままなのです。例えばロシア語で質問しても、ロシアを除けば日本が1423回、米国が657回と圧倒的な数字が出てきます。文化的にも地理的にも縁が薄いはずの言語でも、日本が強く引き出されるわけです。
データを見ると、言語ごとの文脈ではなく、AIが内部に抱えている「文化的に目立つ国」の事前分布が、出力を支配しているように見えます。世界には7000近い言語があるとされますが、検証された24言語の範囲だけ見ても、AIが扱える文化的視点はかなり狭い印象を受けますね。
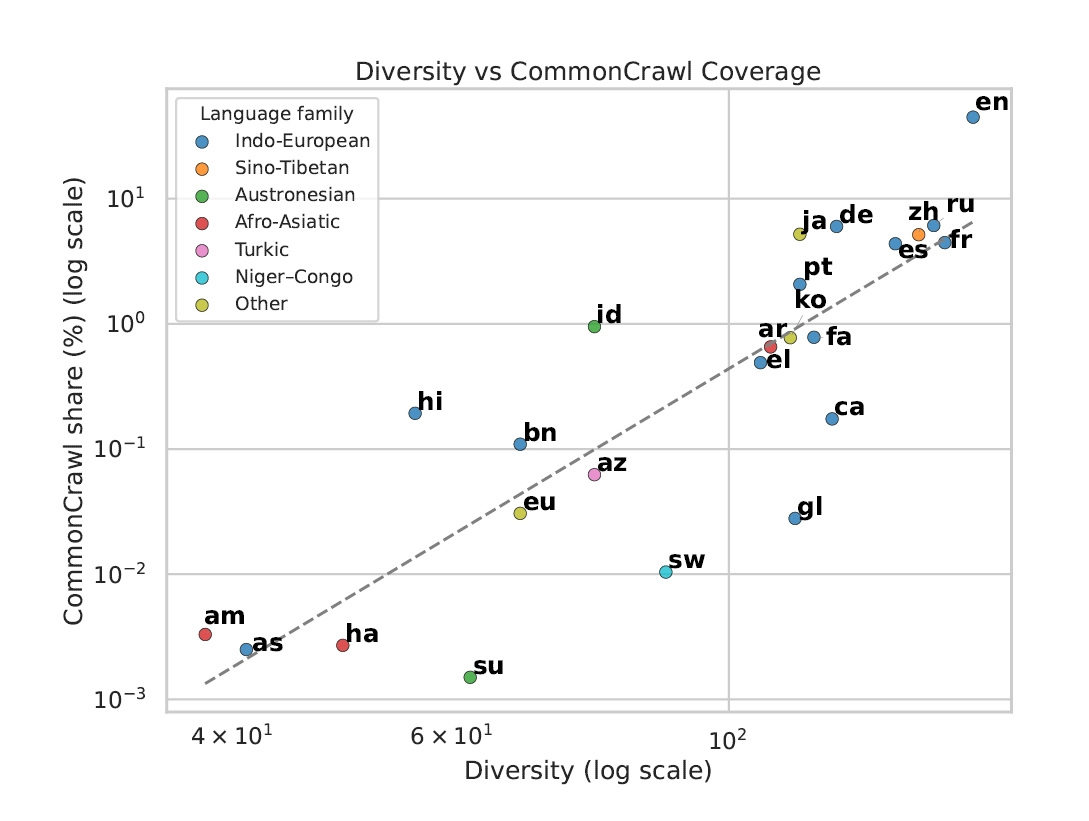
CommonCrawlの言語別シェアを学習リソース量の代理指標とし、出力多様性との正の相関を示した図です。
文化バイアスは事前学習よりも後段の調整で強まる
今回の論文で最も興味深いのは、文化バイアスがどの学習段階で発生するのかを切り分けた実験パートです。研究チームはLlama-3.1(8B、70B)、Qwen2.5(7B、32B、72B)、Gemma-2(9B、27B)、Mistral-7Bのベース版と指示調整版を比較。さらにOLMo-2(7B、32B)とOLMo-3(7B、Think版)では、ベース、SFT(教師ありファインチューニング)、指示調整の3段階すべてを取得して検証しました。
| 学習段階 | 地理分布の特徴 |
|---|---|
| ベースモデル | 比較的バランスよく分散。米国は目立つが、日本・インド・中国・欧州も一定数あり |
| SFT後 | 最大の変化点。日本・米国への集中が急増し、エントロピーが低下 |
| 指示調整後 | SFTの集中を一部ならすが、ベースモデルのバランスまでは回復しない |
つまり、SFTで強まった文化的な偏りは、後段の調整でも十分には打ち消されないということです。また、Llama、Qwen、Gemma、Mistralのベース版と指示調整版を比べても、指示調整後に日本や米国への集中が強まる傾向が見られました。中国発のQwenでも例外ではありません。
事前学習段階では比較的分散していた文化的視点が、後段のチューニング工程で日本や米国のような少数の国に集まりやすくなるのです。本来は応答を扱いやすく整えるはずの工程が、結果として新しい文化バイアスを強めていた可能性があります。AIの中立性を担保するには、事前学習データだけでなく、SFTや指示調整に使うデータの設計まで見直す必要がある、というのは生成AIの開発手法そのものに対する重要な指摘と言えそうですね。
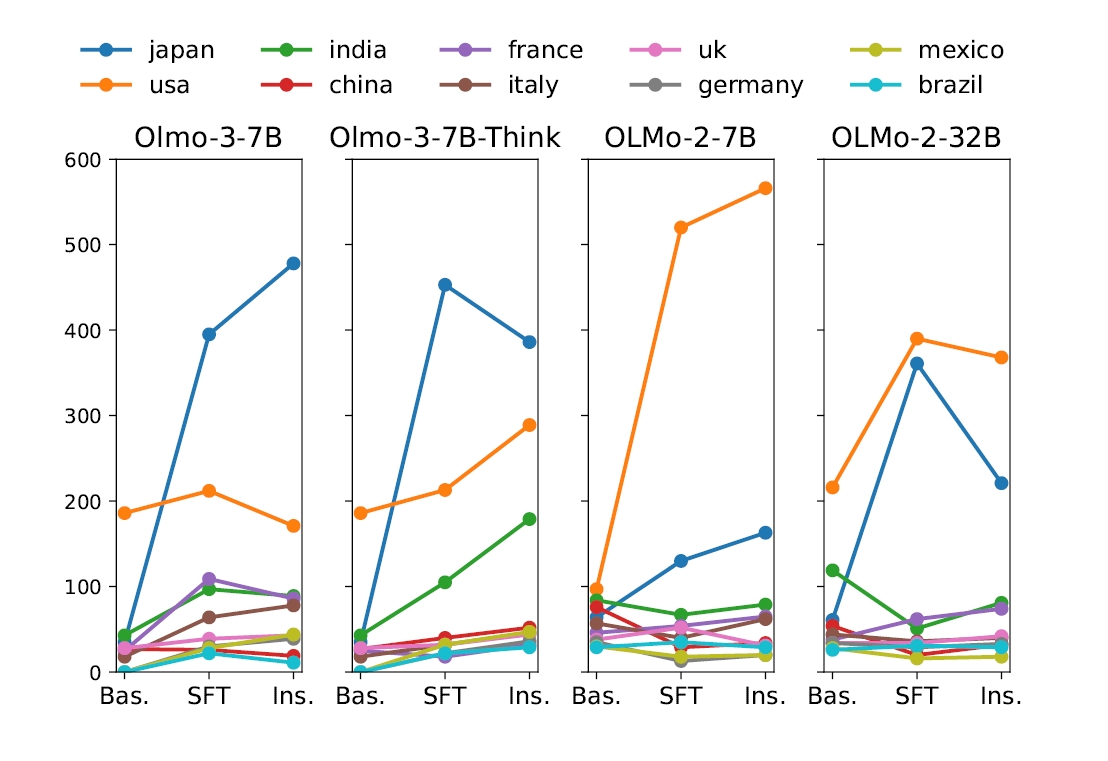
OLMoシリーズで主要国への言及数がSFT段階で急増する様子を示すグラフです。
生成AIが世界の文化を均等に扱えていない現実
日本びいきという結果は、僕ら日本人にとっては悪い気がしないかもしれません。ただ裏を返せば、世界中の他地域の文化が均等に扱われていないという話でもあります。アフリカや南米、東南アジアの多様な文化的背景がAIの出力で薄められている可能性は見過ごせません。
使う側にとっても、文化に関わる質問を投げるとき、回答の裏に「日本か米国を答えがち」というクセが潜んでいると意識する必要があります。開発側にとっては、事前学習データだけでなく、SFTや指示調整に使うデータの設計が文化バイアスを左右する可能性が見えたことが、今後のチューニング手法を見直す出発点になるはずです。
事前学習だけ気をつければよいという話ではなく、その後の工程で何を教え込むかが、AIの世界観を大きく左右している。今回の研究は、生成AIが本当に「世界中の知恵」を扱えているのかを、改めて問い直す材料を与えてくれました。

