AIライター
リアルタイム生成と長時間の一貫性を両立し、無限に遊べる因果世界を目指す次世代の生成AIゲームモデル『Hunyuan-GameCraft-2』
-
-

[]

アイサカ創太(AIsaka Souta)AIライター
こんにちは、相坂ソウタです。AIやテクノロジーの話題を、できるだけ身近に感じてもらえるよう工夫しながら記事を書いています。今は「人とAIが協力してつくる未来」にワクワクしながら執筆中。コーヒーとガジェット巡りが大好きです。

ついに、生成AIは「見る」ものから「遊ぶ」ものへと進化し始めました。2025年11月28日、Tencent Hunyuanの研究チームによる論文「Hunyuan-GameCraft-2:指示追従型のインタラクティブなゲーム世界モデル(Hunyuan-GameCraft-2: Instruction-following Interactive Game World Model)」が公開されました。
研究チームはテキスト指示とキーボード操作の両方を受け付け、リアルタイムで反応するゲーム世界モデル「Hunyuan-GameCraft-2」を開発したのです。これまでも動画生成AIは進化を続けてきましたが、既存のモデルは主に静的な映像を作ることに特化しており、ユーザーの意図通りにキャラクターを動かしたり、環境を変化させたりするインタラクティブ性には課題がありました。僕はAIの進化を楽観視していますが、今回の発表は単なる映像生成の枠を超え、ゲーム開発やシミュレーションのあり方を根本から変える可能性を秘めていると感じます。
このモデルの最大の魅力は、僕たちが普段PCゲームを遊ぶ感覚で、生成された世界に干渉できることです。これまでの多くのワールドモデルは、事前に決められたアクションしか行えなかったり、テキストプロンプトによる大まかな指示しかできなかったりと、自由度に欠ける側面がありました。
しかし、Hunyuan-GameCraft-2は違います。ユーザーは「W/A/S/D」キーやマウスを使って視点や移動を制御できるだけでなく、「松明を取り出す」「爆発を引き起こす」といった具体的な指示を自然言語で与えることが可能なのです。

近いうちに自然言語で遊べる動画をリアルタイムで生成できるようになるかもしれません!(画像は論文より)
「見る」動画生成から「入る」ゲーム生成へ。言葉と操作が融合した新たな体験
Hunyuan-GameCraft-2が目指したのは、単なる映像の連続ではなく、ユーザーの意思が反映される「因果関係のある世界」の構築です。このモデルは140億パラメータ(14B)を持つMoE(Mixture-of-Experts)画像生成モデルをベースに構築されており、そこにキーボードやマウスからの信号と、テキストによる指示を統合する仕組みを取り入れています。
今すぐ最大6つのAIを比較検証して、最適なモデルを見つけよう!
カメラの動きやキャラクターの行動といった制御信号を、モデルが理解できる形式に変換して注入することで、ユーザーは生成されたビデオ内で自由に行動できるようになります。しかも、「マルチターン(複数回)」のインタラクションに対応しているのが興味深いところです。
例えば、最初はただ歩き回るだけだったのが、次は「銃を構える」と指示し、その次に「発砲する」と指示を重ねていくことができます。これまでの動画生成AIでは、時間が経過するにつれて映像が崩壊したり、前の文脈を忘れてしまったりすることがよくありました。しかし、本モデルでは「KV-recache」と呼ばれるメカニズムを採用することで、過去の文脈を保持しながら新しい指示に即座に対応し、一貫性のある映像を生成し続けることが可能になっています。
実際に公開されたデモの内容を見ると、その精度の高さに驚かされます。「ドアを開ける」という指示を出せば、キャラクターがドアに近づき、物理的に矛盾なくドアが開く様子が描画されますし、「雪を降らせる」と言えば、シーン全体が徐々に雪景色へと変化していきます。
これは単なるシーンの切り替えではなく、因果関係に基づいた状態遷移として処理されているのです。ユーザーが入力したプロンプトが、単なる「設定」ではなく、世界を動かす「トリガー」として機能している点は、まさにゲームエンジンそのものと言えるでしょう。
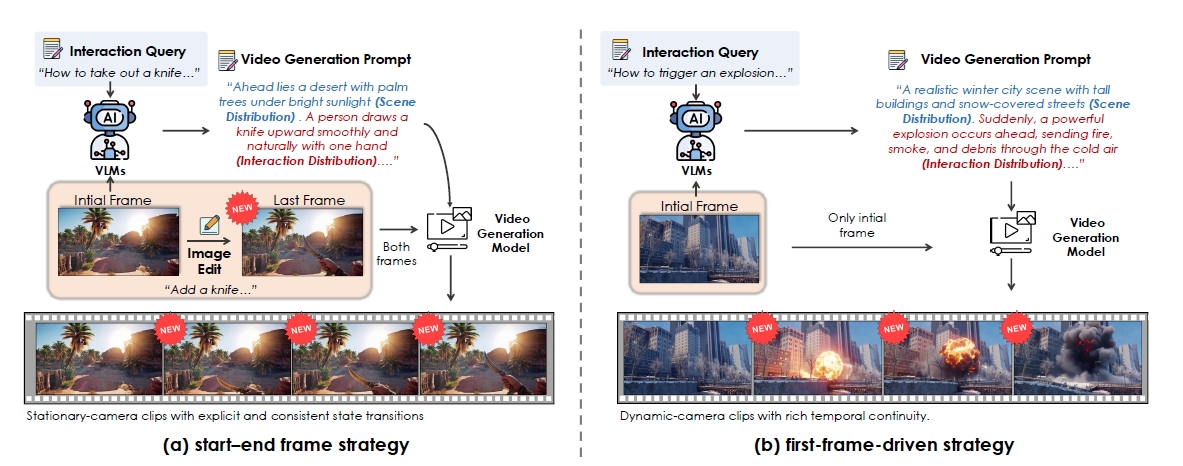
マルチターン操作の生成例です。上段の例では、初期状態から「銃を取り出す」→「構える」→「発砲する」と行動が変化しています。
学習データ不足を解消するために相互作用を定義して自動生成するパイプライン
AIモデルの性能はデータの質と量に依存しますが、ここには大きな課題がありました。それは、世の中にある「インタラクティブな動画データ」がAIを学習させるには少なすぎるということです。
YouTubeにある動画はノイズが多く、ゲームエンジンでシミュレーションを行うにはコストがかかりすぎます。そこで研究チームは、「インタラクティブ動画データ」とは何かを厳密に定義することから始めました。彼らの定義によれば、それは「明確な因果関係を持ち、エージェントや環境が初期状態から異なる最終状態へと遷移するプロセス」を含むものです。
この定義に基づき、彼らは「アサシン クリード」や「サイバーパンク2077」といった150以上のAAAタイトルから高品質なゲームプレイ映像を収集しました。しかし、それだけでは足りません。そこで、大規模なテキストと動画のペアから、因果関係を含んだインタラクティブデータを自動生成するパイプラインを開発しました。
VLM(大規模視覚言語モデル)を使用して動画の初期フレームと最終フレームの差異を分析し、「何が起きたか(例:銃を持っていない状態から持っている状態へ)」を記述する「インタラクション・キャプション」を生成させたのです。
さらに、「ドアを開ける」など、特定の動作データが不足している場合は、画像生成AIを使って必要な初期フレームを合成し、そこから動画を生成させるという手法まで採用しています。こうして構築されたデータセットは、環境の変化(天候など)、アクターのアクション(武器の使用など)、オブジェクトの出現(車や動物など)という3つの主要なカテゴリに分類され、モデルの学習に用いられました。単にデータを集めるだけでなく、何が「相互作用」なのかを哲学的に定義し、足りない部分はAI自身に作らせるというアプローチは、今後のAI開発のヒントになるはずです。
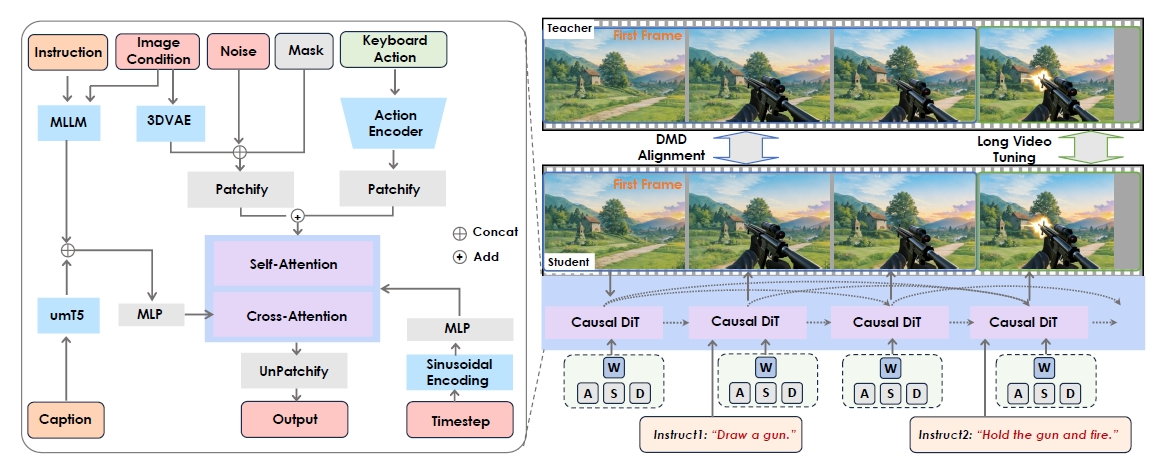
学習データを自動生成するパイプラインの仕組みです。
推論速度の最適化を行いリアルタイムに近い動作と長時間の一貫性を実現
どんなにリアルな映像が生成できても、動作が重ければゲームとしては成立しません。Hunyuan-GameCraft-2は、推論速度の最適化にも力を入れており、16FPS(毎秒16フレーム)というリアルタイムに近い速度での生成を実現しています。これを可能にしたのが、FP8量子化や並列化といったエンジニアリング技術と、モデル構造の効率化です。特に、自己回帰的な生成プロセスにおいて、最初のフレームを「シンク・トークン(Sink Token)」として常にメモリに保持し続けることで、計算効率を高めつつ、長い映像でも座標の原点がずれないように工夫されています。
長時間の動画生成における最大の敵はエラーの蓄積です。生成されたフレームを次の生成の入力として使い続けると、徐々にノイズが溜まり、映像が崩れてしまいます。これに対処するため、研究チームは「ランダム化された長時間動画チューニング(Randomized Long-Video Tuning)」という手法を導入しました。これは、学習中に生成された映像をランダムな長さで延長し、その分布を正解データに近づけるよう調整するものです。これにより、500フレームを超えるような長いシーケンスでも、ある程度の一貫性を保つことが可能になりました。
また、このモデルは「自己強制(Self-Forcing)」と呼ばれる蒸留技術を用いて、双方向の生成モデルを因果的な(時間の流れに沿った)生成モデルへと変換しています。教師モデルの知識を効率的に生徒モデルに受け渡すことで、高品質な生成能力を維持したまま、高速な推論が可能になったのです。16FPSという数字は、まだハイエンドなアクションゲームには及びませんが、アドベンチャーゲームやシミュレーションゲームであれば十分にプレイ可能な水準に近づいています。

Hunyuan-GameCraft-2のモデルアーキテクチャ図です。
新たな評価指標を用いた検証で指示の実行率と物理的な整合性の高さを実証
このモデルの実力を測るために、研究チームは「InterBench」という新しい評価指標を策定しました。これは、単に映像が綺麗かどうかだけでなく、「指示したインタラクションが正しく発生したか」「物理法則に従っているか」といった6つの側面から評価を行うものです。比較対象には「HunyuanVideo」「Wan2.2」「LongCatVideo」といった最新の動画生成モデルが選ばれましたが、結果はHunyuan-GameCraft-2の圧勝でした。
特に注目すべきは「インタラクションのトリガー率(Trigger Rate)」です。これはユーザーの指示に対して何らかのアクションが起きたかどうかを示す指標ですが、環境変化のカテゴリで0.962、アクターのアクションにおいては0.983という極めて高いスコアを記録しました。比較対象のモデルが0.5~0.8程度に留まる中、ユーザーの意図をほぼ確実に汲み取れていることがわかります。また、物理的な整合性(Physics Correctness)においても、環境変化カテゴリで他モデルより0.683ポイント高いスコアを出しており、雪が積もる様子や爆発の広がり方が、より現実に即して描画されていることが証明されました。
定性的な比較を見ても、その差は歴然としています。例えば「ドラゴンが現れる」という学習データにはない未知の指示を与えた場合でも、Hunyuan-GameCraft-2は背景や照明に馴染んだドラゴンを生成し、自然に羽ばたかせることができました。他のモデルでは、物体が背景から浮いてしまったり、形状が崩れたりすることが多い中で、この汎用性の高さは特筆に値します。学習データにない「未知の概念」に対しても、インタラクションの構造を理解しているため、それらしく振る舞わせることができるのです。
学習データに含まれない未知のオブジェクト(ドラゴンや狼など)を出現させた際の比較。
技術的な課題を乗り越えて無限に遊べる世界が実現する未来への期待
Hunyuan-GameCraft-2は、生成AIによる「プレイ可能な世界」の実現に向けて、確実な一歩を踏み出しました。テキストと操作入力の統合、大規模なインタラクティブデータの構築、そしてリアルタイム性の確保と、全方位での技術革新が見て取れます。特に、静的な映像生成から脱却し、「因果関係」と「操作性」に焦点を当てた点は、今後のエンターテインメントの形を大きく変える可能性があります。
もちろん、課題がないわけではありません。論文中でも触れられている通り、500フレームを超える長時間の生成では依然として一貫性が失われることがあり、論理的な思考を必要とする複雑なタスク(パズルを解くなど)はまだ苦手としています。また、16FPSという速度も、より滑らかな体験のためにはさらなる向上が求められるでしょう。
しかし、僕たちが夢見てきた「自分の言葉で世界を作り、その中を自由に冒険する」という体験は、もうすぐそこまで来ているのかもしれません。この技術がさらに洗練され、長期記憶や高度な推論能力と組み合わさったとき、僕たちは真の意味での「無限のゲーム」を手に入れることになるでしょう。その未来に、僕は大いに期待しています。
この記事の監修

柳谷智宣(Yanagiya Tomonori)監修
ITライターとして1998年から活動し、2022年からはAI領域に注力。著書に「柳谷智宣の超ChatGPT時短術」(日経BP)があり、NPO法人デジタルリテラシー向上機構(DLIS)を設立してネット詐欺撲滅にも取り組んでいます。第4次AIブームは日本の経済復活の一助になると考え、生成AI技術の活用法を中心に、初級者向けの情報発信を行っています。
