AIライター
「エージェントを増やせば賢くなる」は場合による? GoogleとMITが実証したAI協働の最適設計法
-
-


アイサカ創太(AIsaka Souta)AIライター
こんにちは、相坂ソウタです。AIやテクノロジーの話題を、できるだけ身近に感じてもらえるよう工夫しながら記事を書いています。今は「人とAIが協力してつくる未来」にワクワクしながら執筆中。コーヒーとガジェット巡りが大好きです。

柳谷智宣(Yanagiya Tomonori)監修
ITライターとして1998年から活動し、2022年からはAI領域に注力。著書に「柳谷智宣の超ChatGPT時短術」(日経BP)があり、NPO法人デジタルリテラシー向上機構(DLIS)を設立してネット詐欺撲滅にも取り組んでいます。第4次AIブームは日本の経済復活の一助になると考え、生成AI技術の活用法を中心に、初級者向けの情報発信を行っています。
2025年12月、Google Research、Google DeepMind、そしてMITの研究者たちは「Towards a Science of Scaling Agent Systems(エージェントシステムのスケーリングの科学に向けて)」という衝撃的な論文を発表しました。
これまでAI業界、特にLLMを活用した自律型エージェント開発の現場では、ある種の「神話」が信じられてきたからです。それは、「エージェントの数を増やし、チームを組ませれば、単体のAIよりも高いパフォーマンスを発揮する」という経験則です。しかし、今回発表された研究結果は、その常識に冷や水を浴びせるものでした。
彼らは単に「エージェントはすごい」と言うのではなく、180通りもの実験構成と徹底的なデータ分析によって、「いつエージェントを増やすべきか、そしていつ増やすべきではないか」を数値化したのです。
僕は基本的にAIの無限の可能性を信じていますが、同時に「なんとなく凄そう」という雰囲気だけで技術が語られることには危うさを感じています。この論文の素晴らしい点は、まさにその「雰囲気」を排除し、エージェントシステムの設計を「科学」へと昇華させようとしている点にあります。
彼らは、OpenAI、Google、Anthropicという主要な3つのLLMファミリーを使用し、金融分析、Webブラウジング、ゲームの計画(Minecraft)、そして業務ワークフローという4つの異なるベンチマークで実験を行いました。その結果、無邪気にエージェント同士を会話させても、必ずしも賢くなるわけではないということが明らかになりました。むしろ、タスクの性質を見誤れば、パフォーマンスは大きく低下します。僕たちが直面しているのは、単なる計算能力の競争ではなく、もっと複雑で繊細な「組織論」の問題だったのです。
- エージェント協調の神話が崩壊: 「エージェントを増やせば賢くなる」という常識が、GoogleとMITの180通りの実験によって覆された。タスクの性質を見誤ると、パフォーマンスは大きく低下する
- ツールと協調のトレードオフ: ツール依存度が高いタスクでマルチエージェントを使うと、調整コストが急増し効率が-26.7%低下。優秀なAI単体の方が45%以上のタスクでは有効
- タスク構造で勝敗が決まる: 金融分析のような分解可能なタスクでは80.8%の性能向上、Minecraftのような逐次的タスクでは最大70%の性能低下と、タスク特性が成否を分ける
- 87%精度の予測モデル誕生: エージェント数、ツール数、モデル性能、タスク複雑さから最適構成を事前予測可能に。試行錯誤不要の科学的設計時代が到来
ツール過多による能力低下と協調のトレードオフ
まず注目すべきは、彼らが導き出した「エージェント協調の原則」と「ツールと協調のトレードオフ」という概念です。皆さんも、複雑なタスクをこなすために、AIに検索機能や計算機など、多くのツールを与えたくなるでしょう。しかし、データによると、ツールへの依存度が高いタスクにおいて、マルチエージェントシステムを採用すると、協調のためのオーバーヘッド(通信コストや調整の手間)が急増し、効率がガクンと落ちるのです。効率性とツール数の相互作用項は強いマイナスの相関(数値にして-0.267)が確認されました。これは、単独のエージェントであれば問題なく使いこなせるツール群も、集団になった途端に「誰がどのツールを使うか」という調整にリソースを奪われ、肝心の推論能力が削がれてしまうのです。
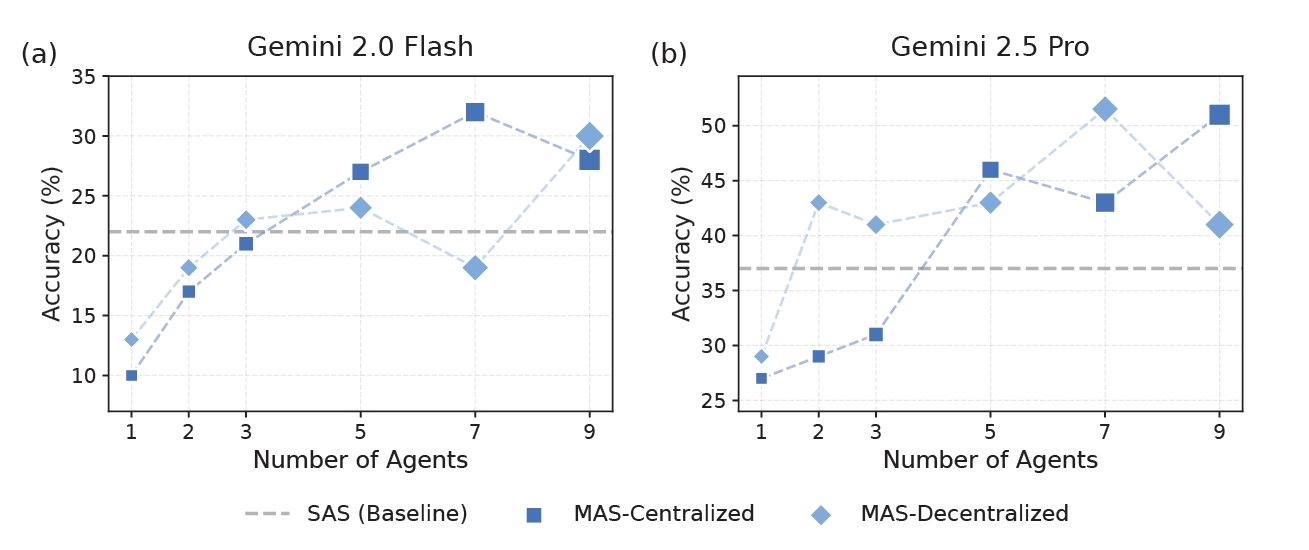
さらに興味深いのは、「能力の飽和点」に関する発見です。研究チームは、単一のエージェント(SAS)のパフォーマンスがすでに45%を超えているようなタスクでは、そこからさらにエージェントを追加して協調させても、得られるリターンは逓減するか、あるいはマイナスになることを突き止めました。
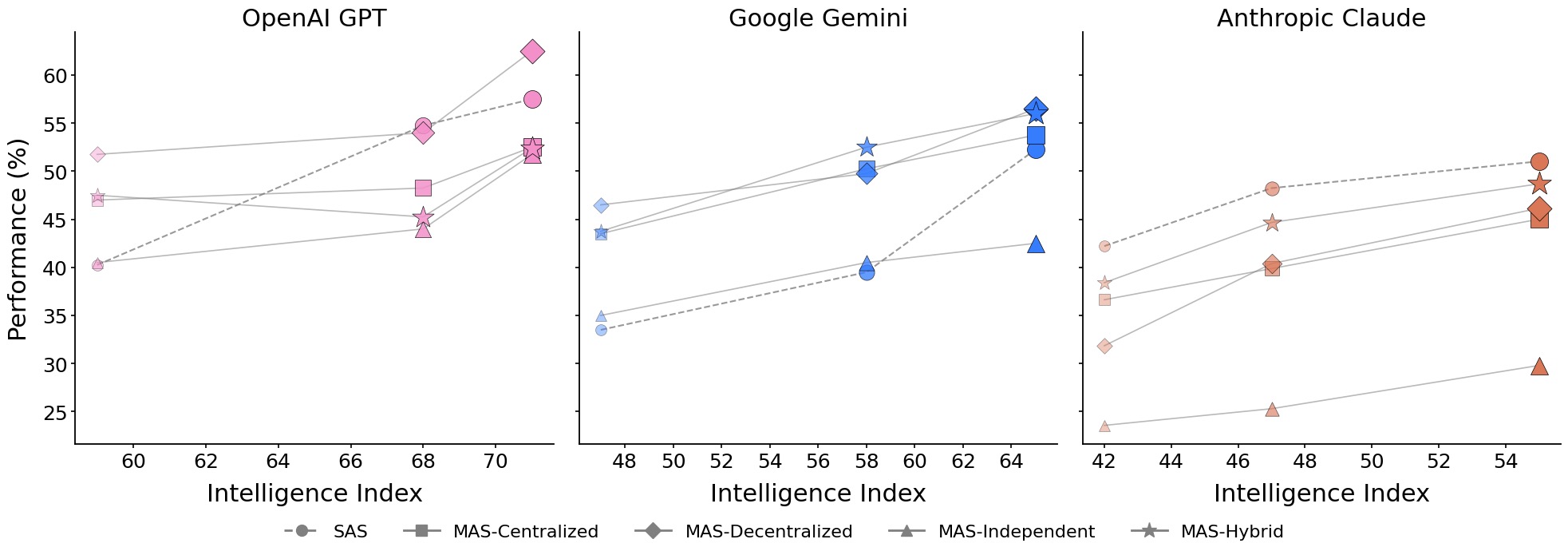
これは、人間社会の会議を想像すると分かりやすいかもしれません。ある程度優秀な担当者が一人でサクサク進められる仕事に対して、わざわざ委員会を発足させても、議論の時間ばかりがかかって成果物の質は大して上がらない、という現象と同じです。統計的にも、ベースラインの能力が高い場合、協調による利益はマイナスの相関(-0.404)を示しています。つまり、「優秀なAI一人にお願いする」のが正解な場面で、僕たちは無駄にチームを組ませようとしていた可能性があるのです。
タスク構造の明暗:分解可能性と逐次性の違い
もちろん、だからといってマルチエージェントシステムが使い物にならないわけではありません。この論文でも、タスクの構造によって「勝てるアーキテクチャ」が劇的に変わることを証明しています。
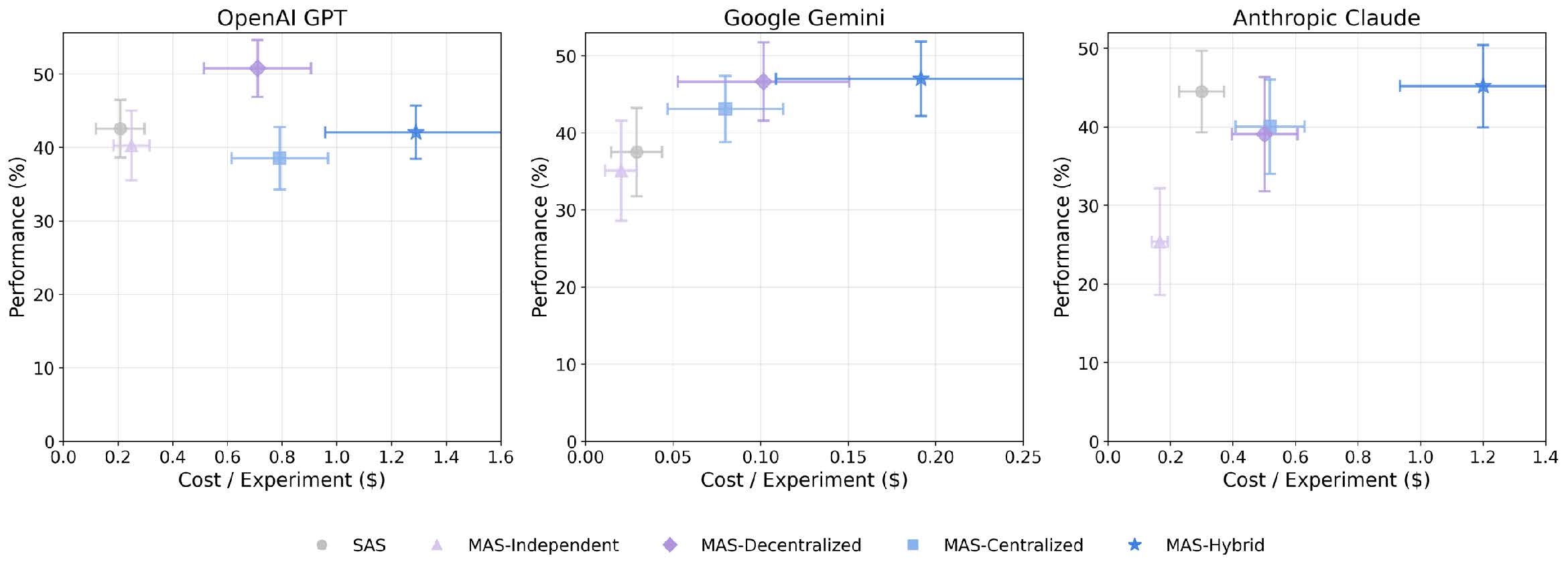
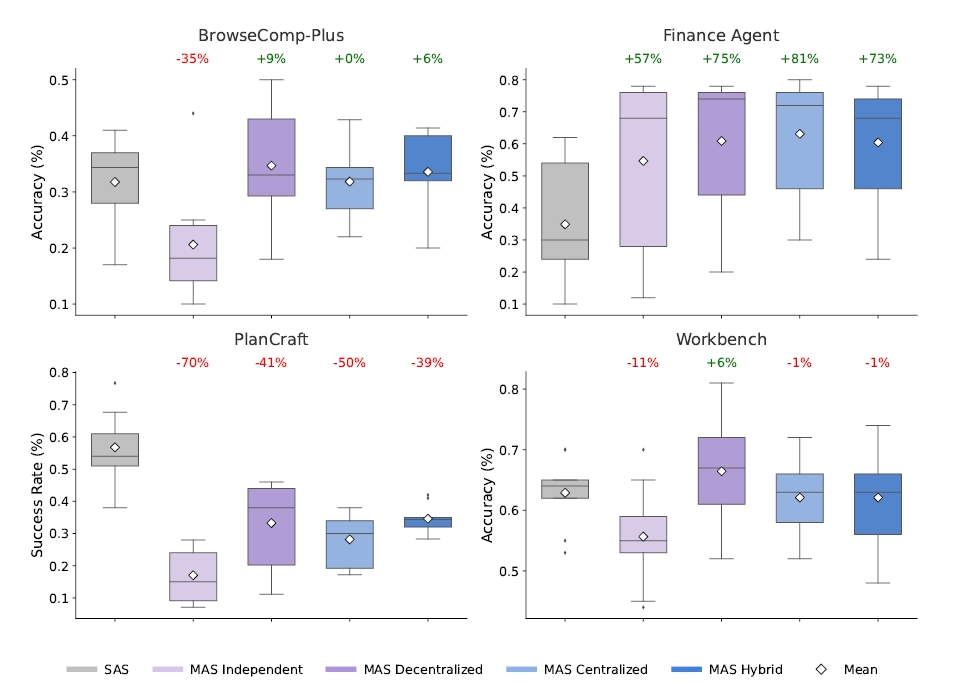
例えば、金融分析(Finance-Agent)のようなタスクを見てみましょう。ここでは、収益分析、コスト構造、市場比較といった具合に、タスクを並列処理可能なサブタスクにきれいに分解できます。このような「分解可能」な領域では、中央集権型のマルチエージェントシステム(Centralized MAS)は、単一エージェントと比較して80.8%ものパフォーマンス向上を記録しました。これは圧倒的な成果といえます。中央のオーケストレーターが適切に指示を出し、複数のエージェントが手分けして情報を集め、最後に統合する。この分業体制がピタリとハマるのです。
一方で、Minecraftでの計画作成(PlanCraft)のようなタスクでは、全く逆の現象が起きました。ここでは、全てのマルチエージェント構成が、単一エージェントに対して39%から70%もパフォーマンスを悪化させたのです。なぜなら、これらのタスクは「逐次的な依存関係」が極めて強いからです。ある素材を作らなければ次の道具が作れず、その道具がなければ素材が掘れない。このような文脈が途切れてはならない状況で、エージェント同士が細切れに会話を挟むと、推論の文脈が分断され、エラーが連鎖的に増幅してしまうのです。
実際、独立型のエージェント群(Independent MAS)では、エラーの増幅率が17.2倍にも達しました。これはもはや「三人寄れば文殊の知恵」ではなく、「船頭多くして船山に登る」状態です。タスクの性質を見極めずにエージェントを投入することが、いかに危険かが分かります。
管理役によるエラー抑制と最適構成の予測モデル
この研究が提示したもう一つの重要な視点は、エラーの「抑制」メカニズムです。エージェントが増えれば増えるほど、誰か一人の間違いが全体に波及するリスクが高まります。しかし、ここで「中央集権型(Centralized)」のアーキテクチャが活躍します。オーケストレーターと呼ばれる管理役のエージェントを配置することで、エラーの増幅率は4.4倍まで抑え込まれました。独立して勝手に動くエージェント群が17.2倍のエラーをまき散らすのに対し、管理役がいるだけでリスクを大幅に軽減できるのです。
これは、人間社会における「上司」や「マネージャー」の役割をAIシステム内で再現することの有効性を数学的に裏付けています。一方で、Webブラウジングのように探索空間が広く、正解ルートが無数にあるような「動的」なタスクでは、中央管理よりも、エージェント同士が互いに議論し合う「分散型(Decentralized)」の方が、9.2%高いパフォーマンスを示しました。管理で縛るか、自由な議論を促すか。この選択もまた、タスクの性質次第なのです。
さらに、研究チームはこれら全ての知見を統合し、未知のタスクに対して最適なエージェント構成を予測する数理モデルを構築しました。驚くべきことに、このモデルは87%の精度で最適なアーキテクチャを言い当てることができます。
これまでは「とりあえずやってみて、ダメなら調整する」という試行錯誤が必要でしたが、これからはエージェントの数、ツールの数、ベースとなるモデルの賢さ、そしてタスクの複雑さを変数として入力するだけで、「ここは単独でやるべき」「ここはチームを組むべき」という判断が事前に下せるようになるのです。論文では、研究後にリリースされた「GPT-5.2」という未知のモデルに対しても、この予測モデルが有効であることが確認されています。
結局のところ、僕たちが学ぶべきは「AIは魔法ではない」ということの再確認です。GoogleとMITの研究は、AIエージェントシステムにおいても、人間社会と同じような「組織論」や「マネジメントの原則」が適用されることを示唆しています。単純なタスクなら一人でやった方が速いし、複雑で並列処理ができる仕事ならチームプレーが圧倒的に強い。そして、道具が多すぎると混乱するし、船頭が多すぎると迷走する。
これらの当たり前のように思える事象を、180の実験設定と数万回の試行によって「スケーリングの法則」として体系化しているのです。これからAIエージェントを活用しようとする企業や開発者は、単に「最新のモデルを使う」だけでなく、「どのような組織図をAIに描かせるか」という設計力が問われることになるでしょう。データに基づいた冷徹な設計こそが、実用化への鍵なのです。