AIライター
DeepSeek-V3.2とは?オープンソースAIがGPT-5・Gemini 3.0に匹敵する性能を実現
-
-

[]

アイサカ創太(AIsaka Souta)AIライター
こんにちは、相坂ソウタです。AIやテクノロジーの話題を、できるだけ身近に感じてもらえるよう工夫しながら記事を書いています。今は「人とAIが協力してつくる未来」にワクワクしながら執筆中。コーヒーとガジェット巡りが大好きです。

柳谷智宣(Yanagiya Tomonori)監修
ITライターとして1998年から活動し、2022年からはAI領域に注力。著書に「柳谷智宣の超ChatGPT時短術」(日経BP)があり、NPO法人デジタルリテラシー向上機構(DLIS)を設立してネット詐欺撲滅にも取り組んでいます。第4次AIブームは日本の経済復活の一助になると考え、生成AI技術の活用法を中心に、初級者向けの情報発信を行っています。
2025年12月、中国のDeepSeek-AIがまたしても衝撃的なレポートを公開しました。タイトルは「DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models(DeepSeek-V3.2:オープン大規模言語モデルの最前線を押し広げる)」。
これまで、OpenAIのGPT-5やGoogleのGemini 3.0といったクローズドな商用モデルが独走し、オープンソースモデルとの性能差は開く一方だと思われていました。しかし、今回発表された「DeepSeek-V3.2」とその強化版である「DeepSeek-V3.2-Speciale」は、その常識を覆そうとしています。特に注目したいのは、計算コストを抑えながら推論能力を高めるという、彼ららしいアプローチがさらに洗練された点です。
論文によると、DeepSeek-V3.2は、長いコンテキストを効率的に処理する新しいアテンションメカニズム「DeepSeek Sparse Attention(DSA)」を導入し、さらに強化学習(RL)の計算規模を拡大することで、推論能力とエージェント性能を飛躍させたとあります。オープンソースがクローズドモデルに肉薄する状況を、具体的なデータとともに見ていきましょう。
- オープンソースが商用AIに追いついた: DeepSeek-V3.2-Specialeは数学ベンチマークAIME 2025で96.0%を記録し、GPT-5-High(94.6%)やGemini-3.0-Pro(95.0%)を上回る性能を達成しました。
- 運用コストの劇的な削減: 新技術「DeepSeek Sparse Attention(DSA)」により、長文処理時の推論コストが従来モデルと比較して大幅に低減。性能を維持しながら効率化を実現しています。
- AIエージェントとしての進化: ツール使用時のコンテキスト管理機能により、思考プロセスを途切れさせずに複雑なタスクを遂行可能に。コーディングエージェント課題で73.1%の解決率を記録しました。
- 合成データによる自律学習: 1827の仮想環境と8万5000以上のプロンプトをAI自身が生成し、人間の介入なしに強化学習を実施。汎用的な問題解決能力を獲得しています。
「Speciale」が叩き出した驚異のスコア、数学とコーディングで世界トップへ
今回発表されたモデルには通常版に加え、「DeepSeek-V3.2-Speciale」という、推論能力に特化した高負荷モデルが存在します。このSpecialeモデルのスコアが凄まじいのです。数学の難問を解くベンチマーク「AIME 2025」において、DeepSeek-V3.2-Specialeは96.0%という正答率を記録しました。比較対象となっているGPT-5-Highは94.6%、GoogleのGemini-3.0-Proでも95.0%です。オープンソースモデルが、巨大資本の最先端プロプライエタリモデルを純粋な推論能力で超えたのは衝撃的ですね。
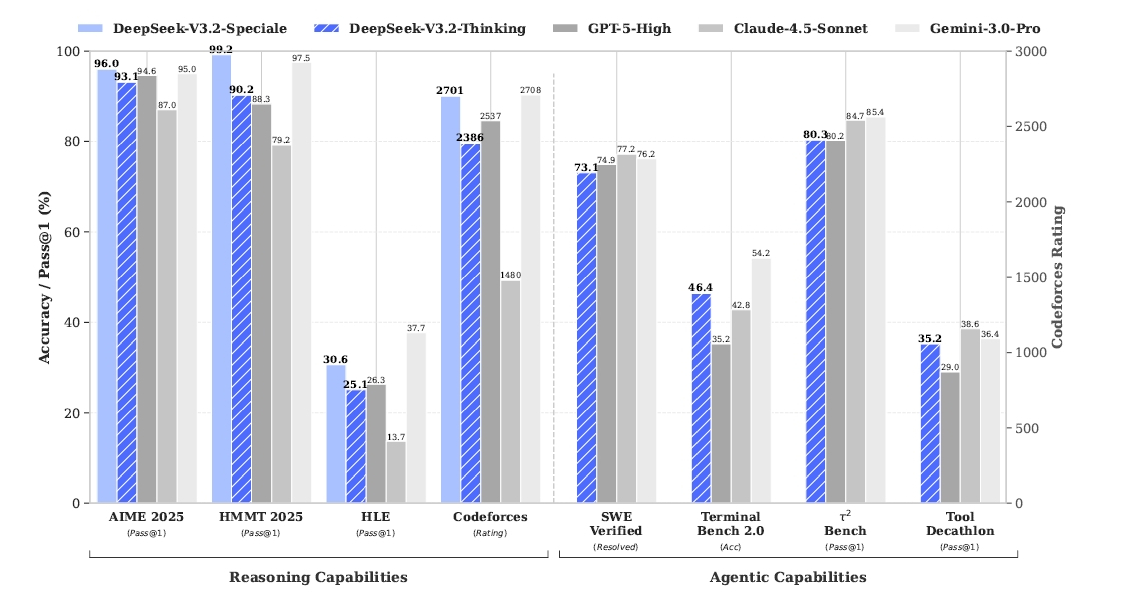
AIME 2025などでGemini 3.0 Proに肉薄・凌駕するベンチマーク比較(論文より)
この性能は、実際の競技プログラミングや数学オリンピックの結果にも反映されています。論文によると、DeepSeek-V3.2-Specialeは、2025年の国際数学オリンピック(IMO)と国際情報オリンピック(IOI)の両方で金メダル相当のパフォーマンスを発揮しました。IOI 2025では600点満点中492点を獲得し、全体の10位にランクインしています。また、競技プログラミングのCodeforcesにおけるレーティングも2701に達し、これもGemini-3.0-Proの2708に肉薄する数値です。
ただし、このSpecialeモデルには弱点もあります。それは「トークン効率の悪さ」です。Gemini-3.0-Proと同等の正答率を出すために、DeepSeek-V3.2-Specialeはより多くの思考トークンを消費します。つまり、答えにたどり着くまでの「考え中」の時間が長いわけです。それでも、誰でもアクセス可能なオープンモデルが、世界最高峰の知能に到達したのは、エンジニアや研究者にとって福音です。彼らはこの成果を「事後学習(Post-Training)の計算量を事前学習の10%以上にまで拡大した結果」だと分析しており、計算リソースを推論能力へ転化するレシピを確立したと言えるでしょう。
効率化の鍵「DeepSeek Sparse Attention」と圧倒的なコストパフォーマンス
高い性能を出せても、動かすのに莫大なコストがかかっては意味がありません。DeepSeekの真骨頂は、その圧倒的なコストパフォーマンスにあります。今回のV3.2で導入された技術的なブレイクスルーが「DeepSeek Sparse Attention(DSA)」です。従来のLLMが抱えていた、文脈が長くなるほど計算量が二乗で増えていくという問題を、このDSAは劇的に改善しました。クエリトークンと関連性の高いトークンだけを効率的に選び出す「Lightning Indexer」という仕組みを導入し、計算の複雑さを大幅に削減したのです。
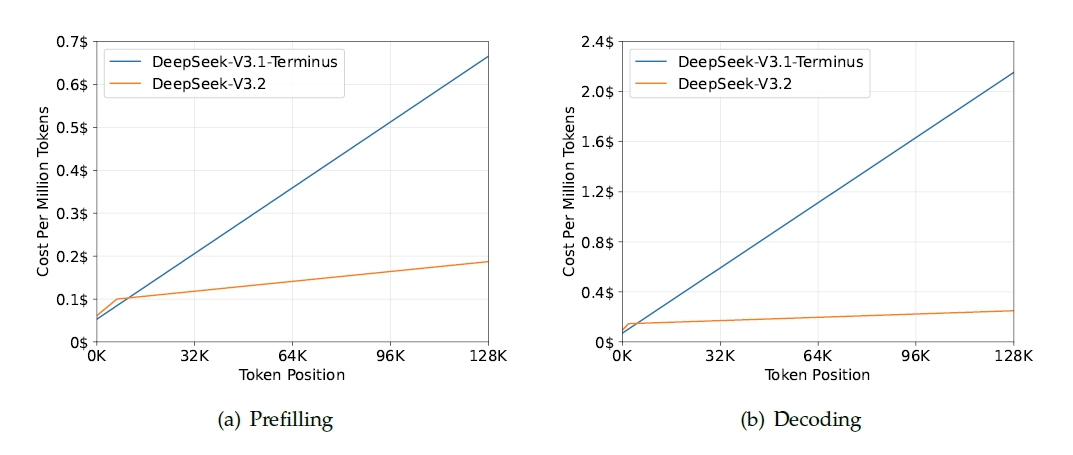
長文でもコストは一定で、V3.1と比較すると圧倒的な推論コストの低さがわかる
この技術により、長いコンテキストを扱う際の推論コストがどう変わったか、論文中のデータが如実に物語っています。H800 GPUクラスター上での実測値によると、コンテキスト長が128Kに達した時点でのデコーディングコストは、前バージョンのV3.1-Terminusと比較して大幅に低く抑えられています。
グラフを見ると、V3.1のコストが右肩上がりで急増していくのに対し、V3.2は驚くほどフラットな推移を見せています。これは、長文のドキュメント解析や、長い履歴を持つチャットボットを運用する企業にとって、直接的な利益につながる進化です。
僕が特に面白いと感じたのは、彼らがこの「疎(Sparse)」なアテンション機構を導入しても、基礎的なモデル性能が劣化していないことを証明している点です。通常、計算を省略すれば精度は落ちるものですが、DeepSeekは「Human Preference(人間の好み)」を模したChatbot Arena形式の評価でも、前モデルと同等のEloスコアを維持しています。
つまり、ユーザーから見れば「賢さはそのままで、維持費だけが安くなった」という理想的な状態を実現したわけです。この技術的な巧みさが、DeepSeekが限られた計算資源で巨大テック企業と渡り合えている理由なのでしょう。
「考えながら道具を使う」エージェント機能の進化とコンテキスト管理
AIエージェントとしての「道具を使う能力」も向上しています。これまで、推論能力の高いモデル(Thinkingモデル)に外部ツールを使わせると、ツールを使うたびに思考の文脈がリセットされてしまい、何度も最初から考え直すという非効率が発生していました。DeepSeek-V3.2では、この問題に対処するために「ツール使用時のためのコンテキスト管理」を導入しています。
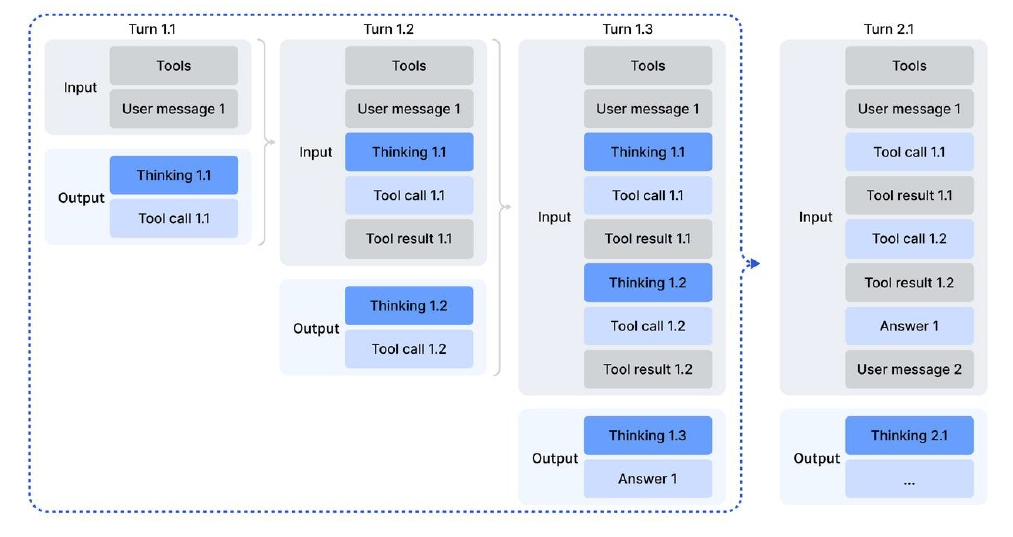
ツール呼び出し中も思考を維持し、途切れず考え続けることができる
ユーザーからの新しいメッセージが来るまでは、過去の「思考(Thinking)」の内容をコンテキスト内に保持し続けるという仕組みです。モデルは「思考する→ツールを呼ぶ→結果を見る→(前の思考を踏まえて)さらに思考する」という、人間らしい試行錯誤のプロセスを途切れさせずに実行できるようになりました。図解されているフローを見ると、ツールの実行結果だけが履歴に残るのではなく、なぜそのツールを使ったのかという思考プロセスもしっかりと引き継がれていることがわかります。
この改良の結果、DeepSeek-V3.2は「SWE-bench Verified」のようなコーディングエージェント課題において、オープンソースモデルとして最高レベルの73.1%(Resolved)を記録しました。これはClaude 3.5 Sonnet(77.2%)やGPT-5(74.9%)には及びませんが、オープンモデルとしては驚異的な数値です。また、検索エージェントとしての能力を測る「BrowseComp」でも、コンテキスト管理を適用することでスコアを大幅に伸ばしています。思考能力とツール使用能力が有機的に結合したことで、AIは単なる「チャットボット」から、仕事を任せられる「同僚」へと一歩近づいたと言えるでしょう。
1800以上の仮想環境が生み出す「合成データ」という新たな武器
DeepSeekがどのようにしてこれほどのエージェント能力を獲得したのでしょうか。彼らは、モデルを訓練するために、人間が作ったデータだけでなく、AI自身が生成した大規模な合成データを積極的に活用しています。特にエージェントタスクにおいては、1827もの異なる環境と8万5000以上の複雑なプロンプトを自動生成しました。
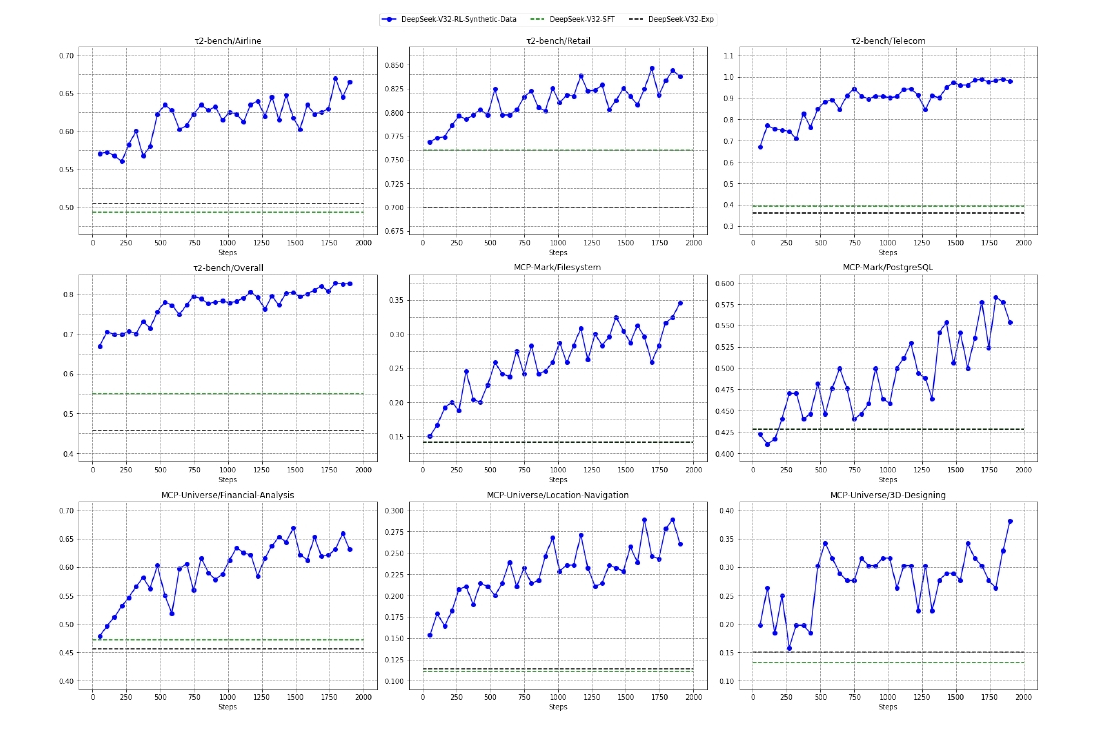
合成データによる強化学習で、多様なタスクへの適応力が向上する様子
例えば、旅行計画のようなタスクをAIに自動生成させ、その正解判定プログラムまでAIに書かせるのです。こうすることで、人間が手作業で採点しなくても、AIが試行錯誤(強化学習)を通じて勝手に賢くなっていくサイクルを作り出しました。
論文中には「3日間の杭州旅行で、ホテルやレストランを重複させず、かつ予算内で……」といった具体的な制約条件を含むタスク例が紹介されていますが、こうした複雑な条件を満たす解を自律的に探索させる訓練が、汎用的な問題解決能力を養っているのです。
実際に、合成データのみで強化学習を行ったモデル(DeepSeek-V3.2-SFT)の学習曲線を見ると、トレーニングのステップが進むにつれて、未知のタスクに対する性能が向上していることが確認できます。これは、AIが特定のパズルを解く方法を覚えたのではなく、「初めて見る問題をどう解決するか」というメタな能力を獲得している証拠です。オープンソース陣営が、データの質と量という課題を「AIによる生成」で乗り越えようとしている点は、今後のAI開発のトレンドを決定づける動きになるはずです。
オープンモデルが切り拓く「賢くて安い」AIの未来
DeepSeek-V3.2とそのSpecialeモデルは、オープンソースAIの可能性を大きく広げました。推論能力においてはGPT-5やGemini 3.0といったトップランナーと肩を並べ、一部では凌駕さえしています。同時に、DSAによる効率化で運用コストを劇的に下げ、合成データによるトレーニングでエージェント能力も強化しました。もちろん、世界知識の幅広さやトークン効率の面では、依然としてクローズドモデルに分があるのも事実です。
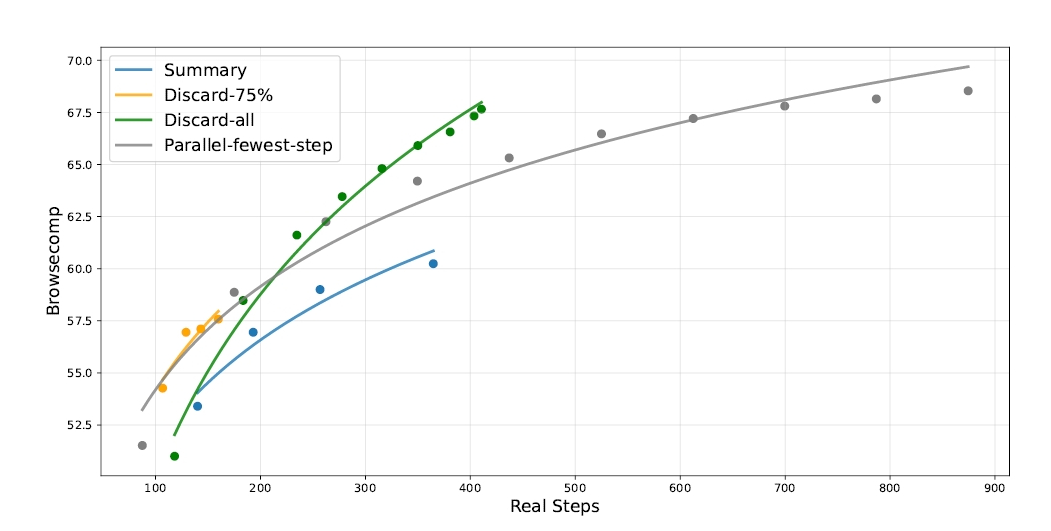
推論時の計算量を制御し、検索精度を向上させた
しかし、世界最高峰の知能が、誰でも検証可能で、かつ低コストで利用できる形で公開されたという意義は大きいと言えます。AIを使ったアプリケーション開発や研究のハードルを一気に下げることにもつながるでしょう。DeepSeekのアプローチは、計算資源という「力」だけでなく、アルゴリズムとデータの工夫という「知恵」で巨人に挑む、痛快な挑戦です。次は僕たちがこのモデルをどう使いこなすか、腕の見せ所ですね。
この記事のまとめ
DeepSeek-V3.2の主要技術と達成した性能指標の総合解説
