AIニュース
RAGの精度が劇的に向上する「メタデータ」の魔術、その仕組みと実装の最適解
-
-

[]

アイサカ創太(AIsaka Souta)AIライター
こんにちは、相坂ソウタです。AIやテクノロジーの話題を、できるだけ身近に感じてもらえるよう工夫しながら記事を書いています。今は「人とAIが協力してつくる未来」にワクワクしながら執筆中。コーヒーとガジェット巡りが大好きです。

柳谷智宣(Yanagiya Tomonori)監修
ITライターとして1998年から活動し、2022年からはAI領域に注力。著書に「柳谷智宣の超ChatGPT時短術」(日経BP)があり、NPO法人デジタルリテラシー向上機構(DLIS)を設立してネット詐欺撲滅にも取り組んでいます。第4次AIブームは日本の経済復活の一助になると考え、生成AI技術の活用法を中心に、初級者向けの情報発信を行っています。
📌 この記事の要約
-
RAGとは
RAG(Retrieval-Augmented Generation:検索拡張生成)
大規模言語モデル(LLM)に社内文書やデータベースなどの外部知識を検索・連携させ、根拠のある正確な回答を生成するAI技術です。通常、追加学習(ファインチューニング)なしで、最新情報や独自情報に基づいた回答を導き出せるため、誤情報(ハルシネーション)を減らし、AIの回答精度を向上させます。
RAGが陥る「類似性の罠」とは
決算資料や法律文書など似通った表現が多い文書では、ベクトル検索だけでは正確な情報を取得できない。企業名や年度が異なる文書が同じ場所にマッピングされてしまう問題がある。
メタデータをベクトルに統合する新手法
研究チームは「ユニファイド埋め込み」を提案。テキストとメタデータを別々にベクトル化し統合することで、検索精度が約33%から約63%へと大幅に向上した。
企業名と年度が最重要の識別子
実験の結果、「企業名」と「年度」が検索精度に最も貢献することが判明。これらを確実に押さえることがコスト対効果の高いRAG設計戦略となる。
RAGは「魔法」から「設計」のフェーズへ
テキストを放り込めばAIが解決してくれる時代は終わり、データの構造や属性をどうエンジニアリングに組み込むかが重要な時代に突入した。
2026年1月17日、バージニア工科大学とVectorize.ioの研究チームが、RAG(Retrieval-Augmented Generation)システムの精度を飛躍的に高めるための新たな手法に関する論文を公開しました。タイトルは「Utilizing Metadata for Better Retrieval-Augmented Generation(より良い検索拡張生成のためのメタデータの活用)」です。
実務でRAGを構築しようとすると、どうしても「検索精度」の壁にぶつかることが少なくありません。特に、企業の決算資料や法律文書のような、似通った表現が頻出するドキュメントを扱う場合、その難易度は跳ね上がります。今回の研究は、まさにその課題に対して、メタデータという「既存の武器」をどう使いこなすべきかという、実践的かつ泥臭いエンジニアリングの解決策を提示してくれるものです。
大規模言語モデル(LLM)は確かに強力ですが、嘘をつくこと、つまりハルシネーションの問題は依然として残っています。これを防ぐためにRAGが使われるわけですが、RAGもまた、ゴミを入れればゴミが出てくるシステムに過ぎません。検索エンジンが間違った情報を拾ってくれば、どんなに賢いLLMでも正しい回答は生成できないのです。
この論文では、メタデータを単なるフィルターとして使うのではなく、埋め込みベクトルそのものに統合することで、検索性能を改善できることが示されています。僕たちが普段、何気なく扱っている「ファイル名」や「日付」といった情報が、実はAIの目を覚ますための鍵になるかもしれないのです。その具体的な手法と、背後にあるロジックを読み解いていきましょう。
似て非なる文書の沼、RAGが陥る「類似性の罠」
たとえば、特定の企業の財務リスクについて「サプライチェーンの混乱に関するリスクは何ですか?」と尋ねたとき、システムが拾ってきたのが、今年のものではなく去年の情報だったり、あるいは同業他社の全く別のレポートだったりすることがあります。
これは、文書のチャンク(断片)ごとの意味的な類似度だけで検索を行っているために起こります。特にSEC(米国証券取引委員会)のForm 10-Kのような定型的な文書では、どの企業も「リスク要因」や「事業の概要」といったセクションで、よく似た言葉遣いをします。その結果、ベクトル空間上では、Appleの2023年のリスクと2024年のリスク、あるいはGoogleのリスク要因が、ほとんど同じ場所にマッピングされてしまうのです。
これまでの一般的なアプローチでは、メタデータはあくまで「検索後のフィルタリング」に使われるのが関の山でした。つまり、まずは似ている文章を全部持ってきて、その後に「今年は2024年だから」といって選別するようなやり方です。
しかし、これでは最初の検索段階で、本当に重要な情報が埋もれてしまうリスクがあります。そこで、メタデータを検索の第一段階、つまりベクトルの生成と計算のプロセスに組み込むことで対処しようと試みました。彼らが指摘するように、企業名や会計年度、セクションのタイトルといった構造化された情報は、文書の意味を特定するための強力な信号を含んでいます。
実験のために、研究チームは「RAGMATE-10K」という新しいデータセットを作成しました。これはApple、Alphabet、Adobeなどの大手テック企業5社の決算資料から構成されており、企業名や年度、セクション名などのメタデータが完備されています。このデータセットを使って、単なるテキスト検索と、メタデータを活用した検索の精度比較が行われました。
結果として、メタデータを使わないプレーンな検索では、多くのチャンクが「もっともらしいが正解ではない」という罠に陥りやすいことが浮き彫りになったのです。特に、深い洞察を必要とする質問においては、この傾向が顕著であり、RAGの実用性を大きく損なう要因となっていました。
下の図は、メタデータの有無による検索精度の違いを示したものです。一般的な質問と深い質問の双方において、メタデータを活用した場合の精度(青線・緑線)が、そうでない場合(オレンジ線・赤線)を大きく上回っていることが視覚的に理解できます。
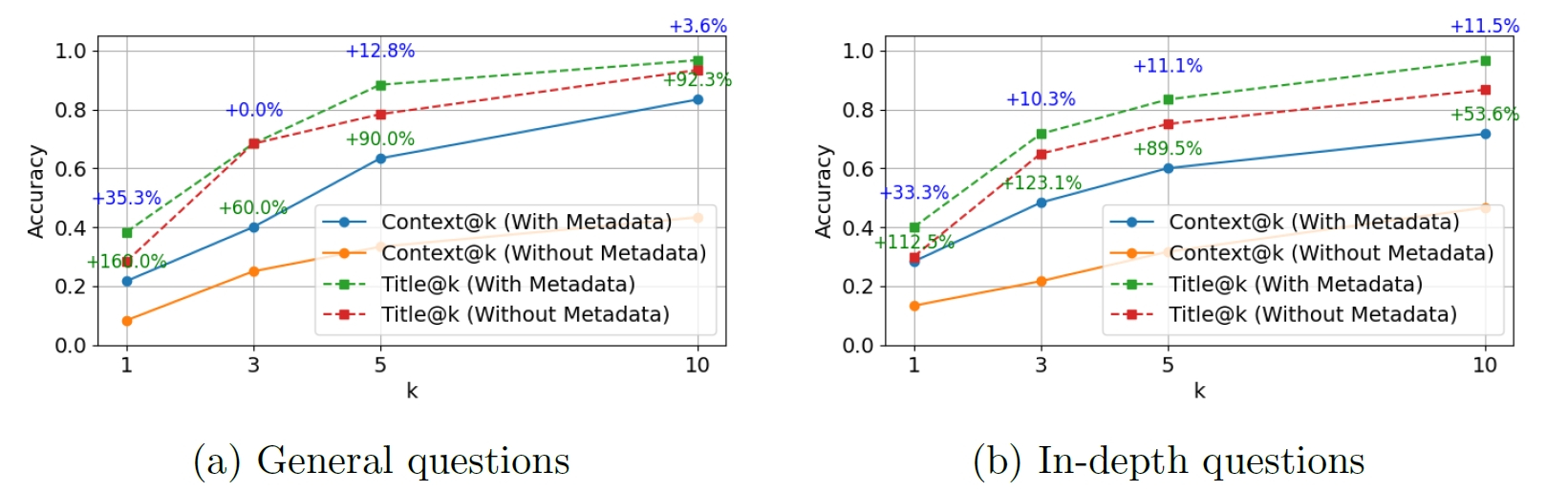
メタデータを活用することで、一般的な質問と詳細な質問の両方において、検索精度が向上します。画像は論文より。
ベクトル空間の大胆な再構成、ユニファイド埋め込みの威力
では、具体的にどうやってメタデータを組み込むのでしょうか。最も単純な方法は、テキストチャンクの先頭に「企業名: Apple; 年度: 2024...」といった文字列をくっつけてから、ベクトル化することです。これを「Metadata-as-Text(MaT)」と呼びます。
この方法は確かに精度を上げますが、運用面で大きな欠点があります。RAGを運用し始めると、タグの付け替えなどメタデータをいじりたくなる場面が増えてきます。メタデータが一つでも変われば、文書全体を再度ベクトル化し直さなければならず、計算コストがばかにならないのです。
そこで研究チームが提案し、最も推奨しているのが「デュアルエンコーダー・ユニファイド埋め込み(Dual Encoder Unified Embedding)」という手法です。
この手法の肝は、テキストとメタデータを別々にベクトル化し、それを一つのベクトル空間に統合するという点にあります。具体的には、テキスト用のエンコーダーで本文をベクトル化し、メタデータ用のエンコーダーで属性情報をベクトル化します。そして、それぞれのベクトルを重み付けして足し合わせるのです。こうすることで、テキストとメタデータの両方の情報を含んだ、単一のインデックスを作成することができます。
この方式の最大のメリットは、メタデータの更新が容易であることです。もしメタデータの修正が必要になっても、テキスト部分の重い計算をやり直す必要はなく、メタデータのベクトルだけを再計算して合成し直せば済みます。
このユニファイド埋め込みの効果は絶大です。実験結果によれば、単純にテキストにメタデータを貼り付ける方法と比較しても、同等かそれ以上の精度を叩き出しています。特に、コンテキストの適合率(Context@K)においては、メタデータなしのベースラインと比較して劇的な改善が見られました。例えば、一般的な質問における上位5件の検索精度は、メタデータなしの約33%から、ユニファイド埋め込みを使用することで約63%へと跳ね上がっています。これは、もはや誤差の範囲ではなく、システムとしての実用レベルが一段階上がったと言える数値です。
仕組みの概念図を見ると、テキストとメタデータがどのように処理され、統合されているかがよく分かります。特に(c)のユニファイドインデックスのアプローチが、計算効率と精度のバランスにおいて優れている点がポイントです。
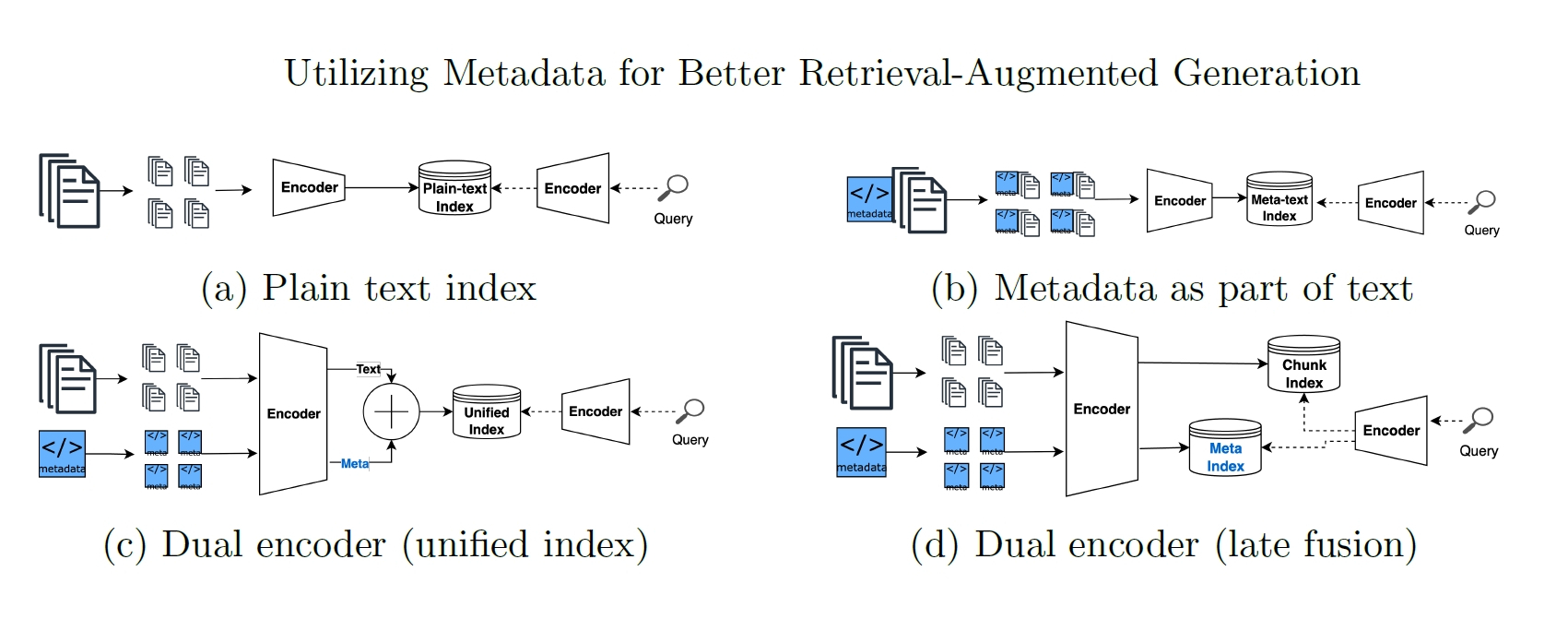
4つの異なる検索戦略の概念図です。
今すぐ最大6つのAIを比較検証して、最適なモデルを見つけよう!
メタデータが変える「距離」、データの凝集と分離
僕がこの論文で特に面白いと感じたのは、単に「精度が上がった」という結果だけでなく、なぜ上がったのかをベクトル空間の幾何学的な視点から分析している部分です。通常、ベクトル検索では「コサイン類似度」を使って近さを測りますが、メタデータを埋め込むことで、この空間の歪みが補正されるような現象が起きています。同じ文書(同じ企業、同じ年度)に属するチャンク同士の結びつき(凝集度)が強まり、逆に異なる文書間の距離が広がるのです。
研究チームの分析によると、メタデータを統合することで、正解のチャンクと不正解のチャンクの間のスコアの差が明確に広がることが確認されました。正例と負例の平均マージンが0.054から0.152へと約3倍に拡大しています。これは、検索エンジンにとって「どれが正解か」がよりはっきりと識別できるようになったことを意味します。これまで霧の中で手探りしていた状態から、霧が晴れて対象の輪郭がくっきりと見えるようになった状態、と表現すれば分かりやすいでしょうか。
さらに、メタデータの重み付けパラメータ(α)を調整することで、テキストの意味内容とメタデータの属性情報のどちらを重視するかをコントロールできる点も興味深いです。実験では、αを0.3から0.6程度の範囲に設定したときに最も良いパフォーマンスが得られています。これは、メタデータが主役になりすぎてはいけないが、脇役としても強力なサポートが必要であるという、絶妙なバランスを示唆しています。テキストの意味だけでは区別がつかない微妙なニュアンスを、メタデータが補完することで、初めて正確な検索が可能になるのです。
下の図は、ベクトル空間内でのチャンク間の類似度分布を示したものです。メタデータを導入することで、同じ属性を持つデータ(左側の箱ひげ図)が高い類似度を維持しつつ、異なる属性を持つデータ(右側の箱ひげ図)との分離が明確になっていることが見て取れます。
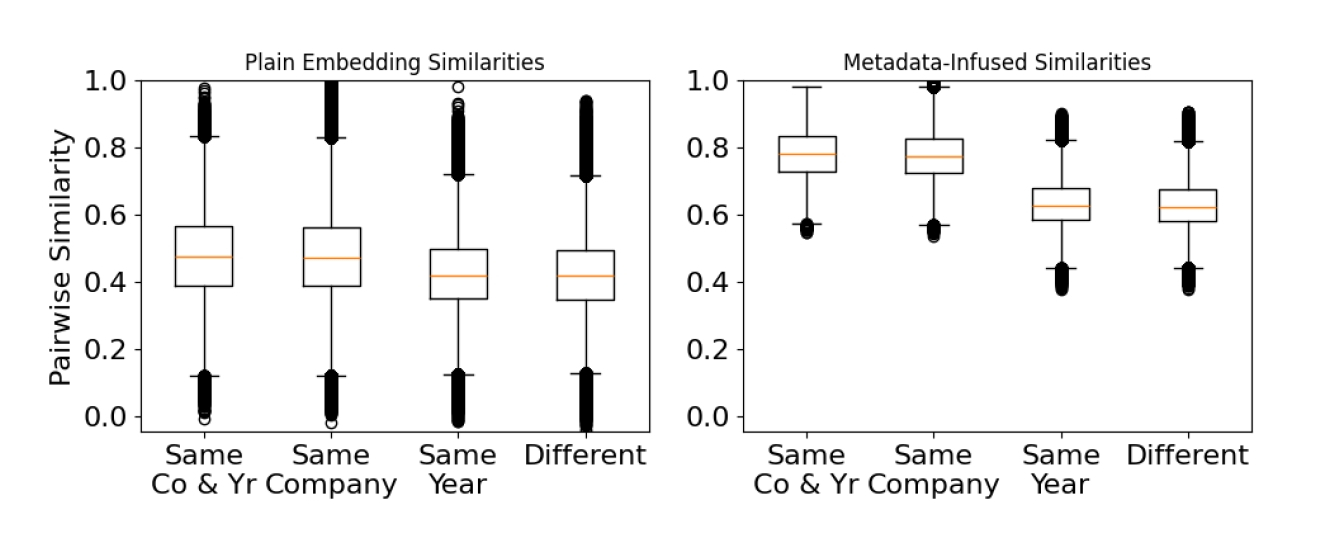
メタデータを統合した埋め込み空間の分析です。同じ企業・年度の文書内の類似度が高まり、異なる文書との区別が明確になっています。
どの情報が「効く」のか、フィールド別の貢献度
最後に、実務的な観点から「どのメタデータが重要なのか」という点についても触れておきましょう。RAGMATE-10Kデータセットには、企業名、フォームタイプ、セクション名、会計年度など、様々なフィールドが含まれています。しかし、すべてのフィールドが等しく検索精度に貢献するわけではありません。研究チームが行った特定の要素を取り除いて影響を見る実験の結果は、非常に示唆に富んでいます。
結論から言うと、最も強力な識別信号(区別のための手がかり)を提供していたのは、「企業名」と「年度」でした。これらを取り除くと、検索精度(特にTitle@KとContext@K)は著しく低下しました。考えてみれば当たり前のことですが、「誰の」「いつの」情報かというコンテキストは、情報の正しさを決定づける最も基本的な要素です。一方で、「セクション名」の削除は、精度に対してそこまで致命的な影響を与えませんでした。もちろん、セクション名があった方がチャンクレベルでの位置特定には役立ちますが、文書全体を特定する力としては、企業名や年度には及ばないということです。
これは、RAGシステムの設計者にとって重要な指針となります。すべてのメタデータを必死にかき集めて埋め込む必要はないかもしれません。まずは「企業名」や「年度」といった、文書のアイデンティティを決定づけるグローバルな識別子を確実に押さえることが、コスト対効果の高い戦略となるでしょう。また、今回は「Form 10-K」という極めて構造化された文書を対象にしていましたが、この知見は科学論文や法律文書、あるいは社内規定集など、他のドキュメントにも応用できるはずです。
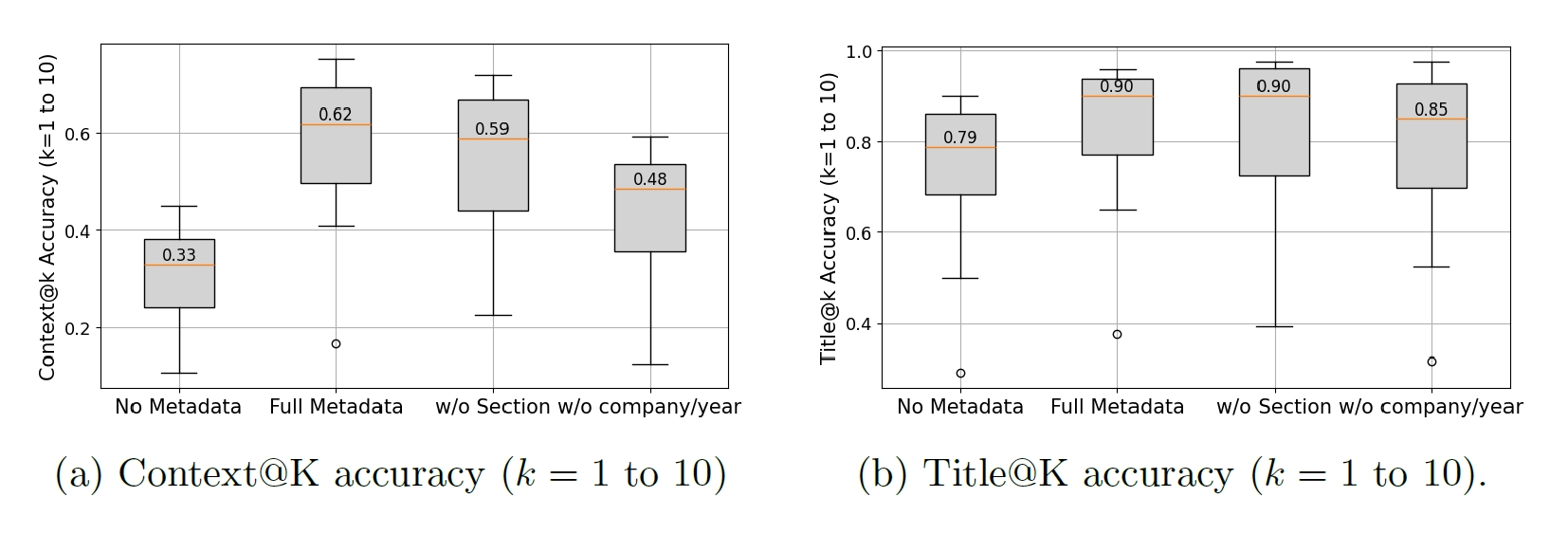
企業名や年度を除外すると検索精度が大きく低下する一方、セクション名の除外による影響は限定的でした。
RAGは「魔法」から「設計」のフェーズへ
今回の研究成果は、RAGシステムにおけるメタデータの重要性を、定量的なデータとともに明らかにしてくれました。単にテキストを放り込めばAIが何とかしてくれるという「魔法」の時代は終わり、データの構造や属性をどのようにエンジニアリングに組み込むかという「設計」のフェーズに入ったと言えるでしょう。
特に、テキストとメタデータを別々に処理して統合する「ユニファイド埋め込み」のアプローチは、精度と保守性の両立という観点で、今後のスタンダードになり得るポテンシャルを秘めています。
あなたの管理しているそのドキュメント、ファイル名やプロパティ情報が埋もれていませんか? それらは、AIにとっての宝の山かもしれません。
解説画像
