

こんにちは、相坂ソウタです。AIやテクノロジーの話題を、できるだけ身近に感じてもらえるよう工夫しながら記事を書いています。今は「人とAIが協力してつくる未来」にワクワクしながら執筆中。コーヒーとガジェット巡りが大好きです。
2月21日、OpenAIは「推論のベストプラクティス」と題したガイドを公開しました。「o1」や「o3 mini」などの推論モデルを構築する際は、「GPT 4o」などのモデルを使う場合とベストプラクティスが異なるそうです。今回は、このガイドの内容について解説します。
2月21日のお昼にOpenAIからガイドを公開したとメールが届きました。
従来の「GPT」シリーズと推論可能な「o」シリーズは、得意とするタスクや必要なプロンプトが異なるだけで、どちらかのシリーズが他方より優れているわけではないとのことです。
oシリーズのモデルのことをOpenAIは「プランナー(the planners)」と呼び、このプランナーをトレーニングし、複雑なタスクについてより長く、より懸命に考えるようにしたそうです。戦略立案や複雑な問題の解決策の計画、大量のあいまいな情報に基づく意思決定などに効果を発揮します。oシリーズは高い精度と正確さでタスクを実行することができるため、数学や科学、工学、金融サービス、法律サービスなど、人間の専門家を必要とするような領域での作業に向いています。
一方、より高速に動作し、コストも手ごろな主力モデルであるGPTシリーズは、単純な指示を実行するのが得意です。
oシリーズとGPTシリーズの使い分け方
出力速度が早い方がいいなら、そして、コストが低い方がいいなら、GPTシリーズが適しています。また、明確に定義されたタスクの実行も、GPTモデルでうまく処理できます。一方、正確性や信頼性が重要で、複数のステップで問題を解決する必要がある場合は、あいまいさや複雑さを克服できるoシリーズの方が向いています。
ほとんどのAIワークフローでは、エージェントによるプランニングと意思決定にはoシリーズ、タスクの実行にはGPTシリーズというように、両方のモデルを組み合わせて使用しているそうです。
例えば、カスタマーサービスのワークフローでは、顧客からの問い合わせが来たら、高速動作する「GPT 4o-mini」モデルがCRMから顧客情報を取得し、問い合わせの分類を行います。「届いた商品が壊れていた」とのことなので、返品ポリシーの情報を取得。続いて、高性能な「GPT 4o」が返品ポリシーに基づいて返品や返金のアクションを実行します。そして、推論可能な「o3 mini」で実行したアクションを検証し、顧客に通知して対応完了となる、といった具合です。
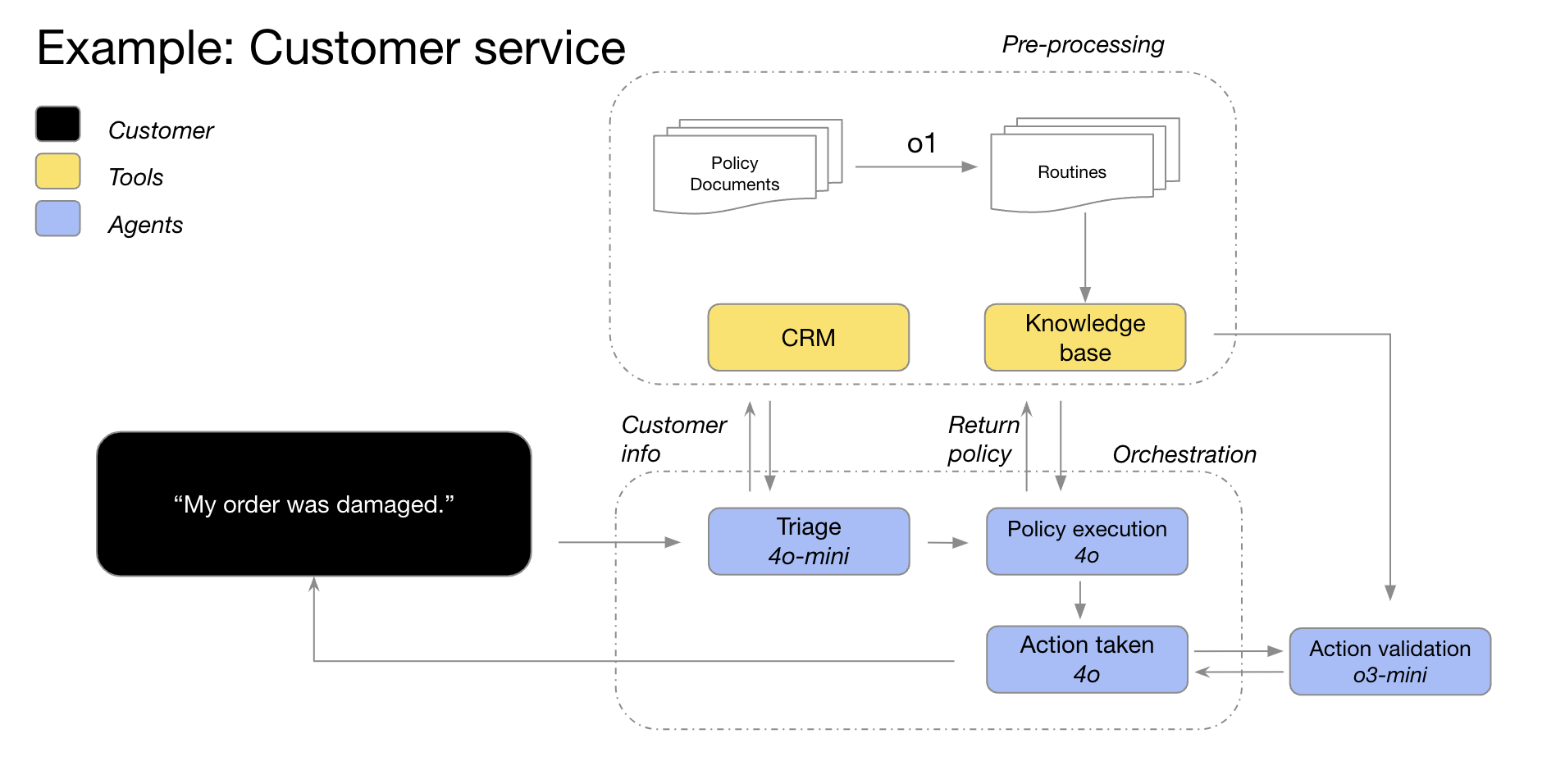
カスタマーサービスで活用されるAIエージェントの構成図。
推論モデルのoシリーズを使うべきシチュエーション
OpenAIの顧客がoシリーズの活用に成功した事例がいくつか紹介されました。
1:曖昧なタスクのナビゲート
oシリーズのような推論モデルは、限られた情報やバラバラの情報を受け取り、簡単なプロンプトでユーザーの意図を理解し、指示のギャップを処理することが得意です。実際、推論モデルは無学な推測をしたり、情報のギャップを埋めようとする前に、明確な質問をすることが多いのです。
「o1の推論機能により、我々のマルチエージェントプラットフォーム「Matrix」は、複雑なドキュメントを処理する際に、網羅的で、整形された、詳細な応答を生成することができます。例えば、o1によって「Matrix」は、基本的なプロンプトだけで、クレジット契約における支払い制限容量の下で利用可能なバスケットを簡単に特定できるようになりました。o1は、他のモデルと比較して、密なクレジット契約における複雑なプロンプトの52%において、より強力な結果をもたらしました」(Hebbia)
法律・金融向けAIナレッジプラットフォーム企業、Hebbia
2:干し草の山から針を見つける
大量の非構造化情報をやり取りする場合、oシリーズは、質問に答えるためにもっとも関連性の高い情報だけを理解し、引き出すことに優れています。
「ある企業の買収を分析するために、o1は契約書やリースなど何十もの企業文書をレビューし、取引に影響しそうな厄介な条件を探しました。o1は、重要な用語にフラグを立て、脚注にある重要な「支配権の変更」条項を特定することができました」(Endex)

AI金融インテリジェンス・プラットフォーム、Endex
3:大規模なデータセットから関係性とニュアンスを見つけ出す
oシリーズは法的な契約書や財務諸表、保険金請求書のような、何百ページにもおよぶ高密度で非構造化情報の複雑な文書に対する推論が得意です。特に、文書間の類似性を導き出し、データに基づいて意思決定を行うことに長けています。
「税務調査では、複数の文書を統合して最終的な説得力のある答えを導き出す必要があります。GPT-4oとo1を入れ替えたところ、o1は文書間の相互関係を推論し、1つの文書では明らかにならない論理的な結論を導き出すのが得意であることがわかりました。その結果、o1に切り替え、エンドツーエンドのパフォーマンスが4倍向上しました」(Blue J)

税務調査用AIプラットフォーム「Blue J」
oシリーズは、ニュアンスの異なるポリシーやルールを推論し、目の前のタスクに適用して合理的な結論を導き出すことに長けています。
「財務分析では、アナリストは株主資本に関する複雑なシナリオに取り組むことが多く、関連する法律の複雑さを理解する必要があります。資金調達が既存の株主にどのような影響を与えるのか、特に既存株主が希薄化の防止権を行使した場合にどのような影響を与えるのか、といったシナリオです。これには、資金調達前後のバリュエーションを推論し、循環希薄化ループに対処する必要がありました。我々は、o1とo3-miniがこれを完璧に実行できることを発見したのです。10万ドルの株を持つ株主への影響を示す明確な計算表まで作成しました」(BlueFlame AI)
投資管理用AIプラットフォーム「BlueFlame AI」
4:多段階エージェント計画
推論モデルは、エージェント的プランニングと戦略開発に不可欠です。o1やo3シリーズが「プランナー」として使用され、問題に対する詳細な複数ステップの解決策を作成し、高知能と低遅延のどちらが最も重要であるかに基づいて、各ステップに適切なGPTモデルを選択し、割り当てるのです。
「o1シリーズをエージェント基盤のプランナーとして使用し、ワークフロー内の他のモデルをオーケストレーションさせて、マルチステップのタスクを完了させます。o1はデータタイプを選択し、大きな質問を小さな塊に分解するのが得意で、他のモデルが実行に集中できるようにしています」(Argon AI))
製薬業界向けAIナレッジ・プラットフォーム「Argon AI」
「o1は、仕事のためのAIアシスタントである「Lindy」で、私たちのエージェント的ワークフローの多くを支えています。このモデルは、関数呼び出しを使ってカレンダーや電子メールから情報を引き出し、ミーティングのスケジュールや電子メールの送信、その他の日々のタスクの管理を自動的に支援します。これまで問題を引き起こしていたエージェントのステップをすべてo1に切り替え、エージェントが一晩で完ぺきに処理してくれるようになりました」(Lindy.AI)
仕事のためのAIアシスタント「Lindy.AI」
5:視覚的推論
今日のところ、o1は視覚機能をサポートする唯一の推論モデルです。GPT-4oと異なるのは、o1が、構造の曖昧な図表や画質の悪い写真など、最も困難な視覚でさえも把握できる点です。
「高級宝飾品の偽物や絶滅危惧種、規制薬物など、何百万ものオンライン商品のリスクとコンプライアンス・レビューを自動化しています。GPT-4oは、最も難しい画像分類タスクで50%の精度を達成しました。o1は、パイプラインに変更を加えることなく、88%という驚異的な精度を達成しました」(SafetyKit)
AIを活用したリスク・コンプライアンス・プラットフォーム、「SafetyKit」
「OpenAIの社内でテストした結果、o1は非常に詳細な建築図面から備品や材料を特定し、包括的な部品表を生成できることがわかりました。最も驚いたことのひとつは、o1が建築図面のあるページにある凡例を、明示的な指示なしに別のページに正しく適用することで、異なる画像間の類似性を認識できることです。下の写真では、4x4のPT材の柱について、o1が凡例に基づいて「PT」が圧力注入防腐処理を意味することを認識していることがわかります」(OpenAI)
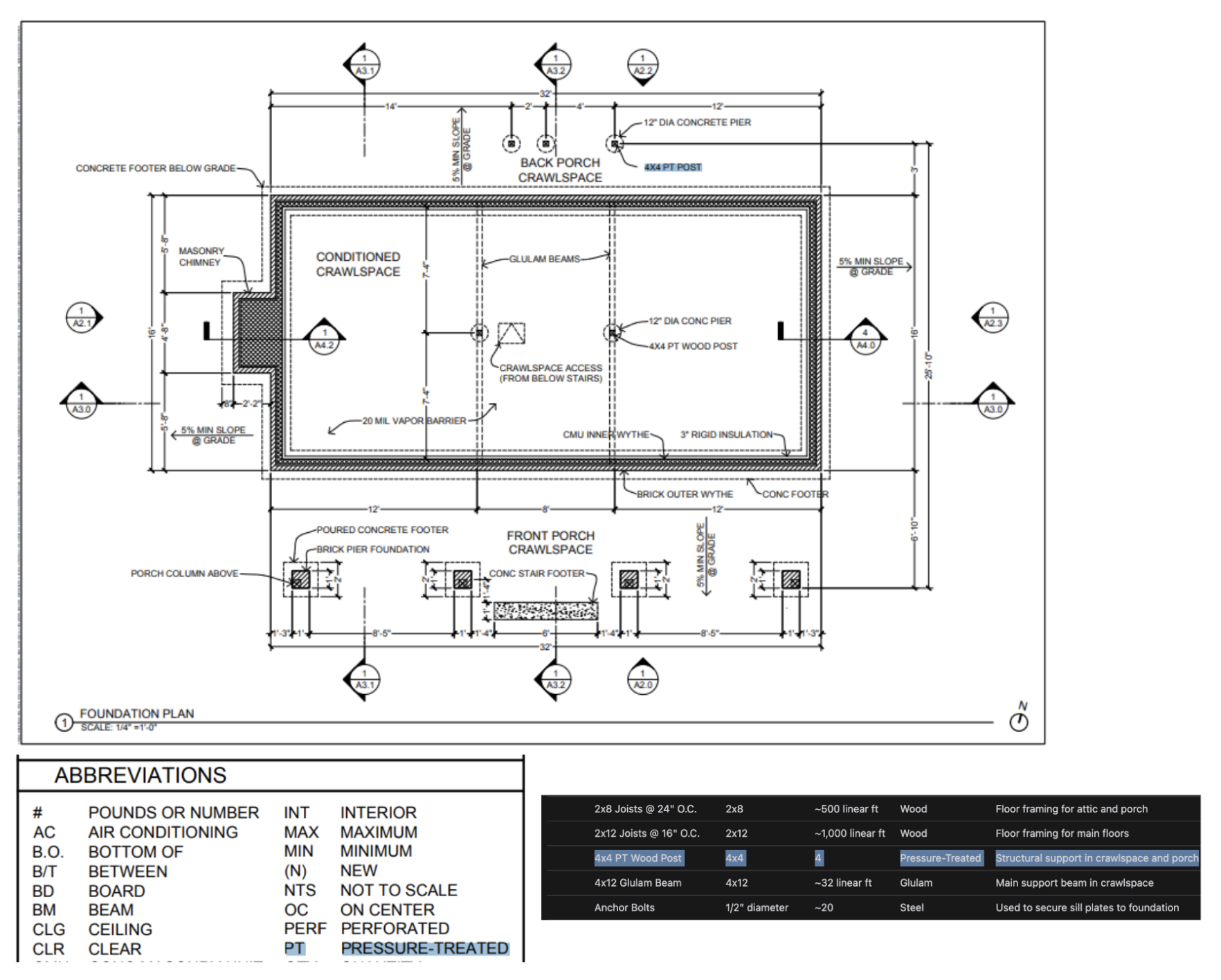
oシリーズは建築図面の詳細を正しく読み取ることができます。
実際にこの図面の出力部分を消して、o1で試してみました。プロンプトに「この図面から包括的な部品表を生成してください。必要な数や長さ、素材も入れてください」と入力したところ、

確かに、図面を読み解き、凡例から情報を理解しているようです。
6:レビュー、デバッグ、コード品質の改善
oシリーズは、大量のコードのレビューと改善に特に効果的で、バックグラウンドでコードレビューを実行することがよくあります。
「私たちはGitHubやGitLabのようなプラットフォーム上で自動化されたAIコードレビューを提供しています。コード・レビュー・プロセスは本質的にレイテンシーに左右されるものではありませんが、複数のファイルにまたがるコードの差分を理解する必要があります。o1は、人間のレビュアーが見逃してしまうようなコードベースの小さな変更を確実に検出できるのです。oシリーズに切り替えた後、製品のコンバージョン率を3倍向上させることができました」(CodeRabbit)

AIコードレビューのスタートアップ、「CodeRabbit」
GPT-4oとGPT-4o miniは低レイテンシーでコードを書くのに適していますが、レイテンシーにあまり影響されないユースケースでは、o3-miniの活用が広がっています。
「o3-miniは一貫して高品質で決定的なコードを生成し、非常に困難なコーディングタスクであっても、問題が明確に定義されている場合には正しい解決策にたどり着くことが多いです。他のモデルは小規模で迅速なコードの反復にしか役立たないかもしれませんが、o3-miniは複雑なソフトウェア設計システムの計画と実行に優れているのです」(Windsurf)
Codeiumによって構築された共同エージェント型AI搭載IDE「Windsurf」
7:他のモデルの応答に対する評価とベンチマーク
推論モデルは、他のモデルの応答をベンチマークし評価するのにも優れています。データの検証は、特に医療のようなセンシティブな分野において、データセットの品質と信頼性を確保するために重要です。従来の検証方法はあらかじめ定義されたルールやパターンを用いますが、o1やo3-miniのような高度なモデルは文脈を理解し、データを推論することで、より柔軟かつ知的なアプローチでの検証を可能にします。
「多くの顧客が「Braintrust」の評価プロセスにおいて、LLMを判定者として使用しています。たとえば、医療系の企業では、GPT-4oのようなモデルを使って患者からの質問を要約し、その要約の品質をo1で評価するといった使い方をしています。ある顧客は、判定のF1スコアがGPT 4oで0.12だったのが、o1では0.74にまで向上しました。o1はもっとも難しく複雑な評価タスクにおいて大きな変化をもたらす“ゲームチェンジャー”になっています」(Braintrust)

AIエバリュエーションプラットフォーム「Braintrust」
推論モデルをうまく使うためのプロンプトのコツ
これらのモデルは、わかりやすいプロンプトで最高のパフォーマンスを発揮します。プロンプトエンジニアリングのテクニックの中には、モデルに「ステップバイステップで考える」ように指示するようなものがありますが、oシリーズではパフォーマンスを向上させないどころか、邪魔になることもあります。
開発者メッセージは新しいシステムメッセージです
「o1-2024-12-17」モデルから、chain of commandの動作に合わせるために、従来の「システムメッセージ」ではなく「開発者メッセージ」をサポートするようになりました。モデルの命令の流れをより一貫性のあるものにするためのものであり、開発者(ユーザー)がモデルに対してより明確な指示を与えられるようにします。
プロンプトはシンプルで直接的なものにしましょう
モデルは、簡潔で明確な指示を理解し、それに応答することに優れています。
思考を連鎖させるようなプロンプトは避けてください
これらのモデルは内部で推論を行うので、「ステップバイステップで考えなさい」や「推論を説明しなさい」と促すプロンプトは不要です。
わかりやすくするために区切り記号を使う
マークダウンやXMLタグ、セクションタイトルのような区切り文字を使用して、入力の異なる部分を明確に示し、モデルが異なるセクションを適切に解釈できるようにします。
最初にゼロショットを試し、必要であれば数ショットを試す
推論モデルは良い結果を出すために数ショットの例を必要としないことが多いので、まず例なしでプロンプトを書いてみてください。希望する出力に複雑な要件がある場合は、入力と希望する出力の例をいくつかプロンプトに含めるとよいでしょう。その際はプロンプトの指示と例題が一致している必要があります。
具体的なガイドラインを提示する
モデルの回答を明確に制約する方法がある場合は、プロンプトにその制約の概要を明示してください。例えば、500ドル以下の予算で解決策を提案してください、といった具合です。
最終的な目標を具体的に示してください
プロンプトには、必要な出力を得るための具体的なパラメータを与えるようにし、モデルが成功基準に合致するまで推論と反復を続けるように促してください。
マークダウンフォーマットについて
「o1-2024-12-17」モデルから、APIの推論モデルはマークダウン形式のレスポンスを生成しないようになりました。レスポンスにマークダウン書式を使用したい場合は、開発者メッセージの最初の行に「Formatting re-enabled」という文字列を含めてください。
以上が、OpenAIの推論モデル「o1」や「o3」を使い倒すためのベストプラクティスとなります。画像の理解度が「GPT-4o」よりも賢いとか、「ステップバイステップで考えて」が逆効果など、なるほどと思わせる内容が多く勉強になりました。皆さんもぜひ参考にしてください。
この記事の監修

ITライターとして1998年から活動し、2022年からはAI領域に注力。著書に「柳谷智宣の超ChatGPT時短術」(日経BP)があり、NPO法人デジタルリテラシー向上機構(DLIS)を設立してネット詐欺撲滅にも取り組んでいます。第4次AIブームは日本の経済復活の一助になると考え、生成AI技術の活用法を中心に、初級者向けの情報発信を行っています。