AIニュース
AIメンタルヘルスの未来を左右する「MindBenchAI」——ハーバード大チームが挑む、LLM評価の新たな世界標準
-
-

[]

アイサカ創太(AIsaka Souta)AIライター
こんにちは、相坂ソウタです。AIやテクノロジーの話題を、できるだけ身近に感じてもらえるよう工夫しながら記事を書いています。今は「人とAIが協力してつくる未来」にワクワクしながら執筆中。コーヒーとガジェット巡りが大好きです。
メンタルヘルスケアにおけるAI活用のあり方に関する論文が公開されました。ハーバード大学医学部関連施設であるベス・イスラエル・ディーコネス医療センター(BIDMC)デジタル精神医学部門のBridget Dwyer氏、Matthew Flathers氏、そしてJohn Torous氏らを中心とする研究チームが発表した、「MindBenchAI」に関する研究です。
このプラットフォームは、メンタルヘルスケアの文脈で使用される大規模言語モデル(LLM)のプロファイルとパフォーマンスを評価するための、包括的かつ実用的なシステムとして設計されました。今回は、この画期的なプラットフォームの詳細と意義を解説します。
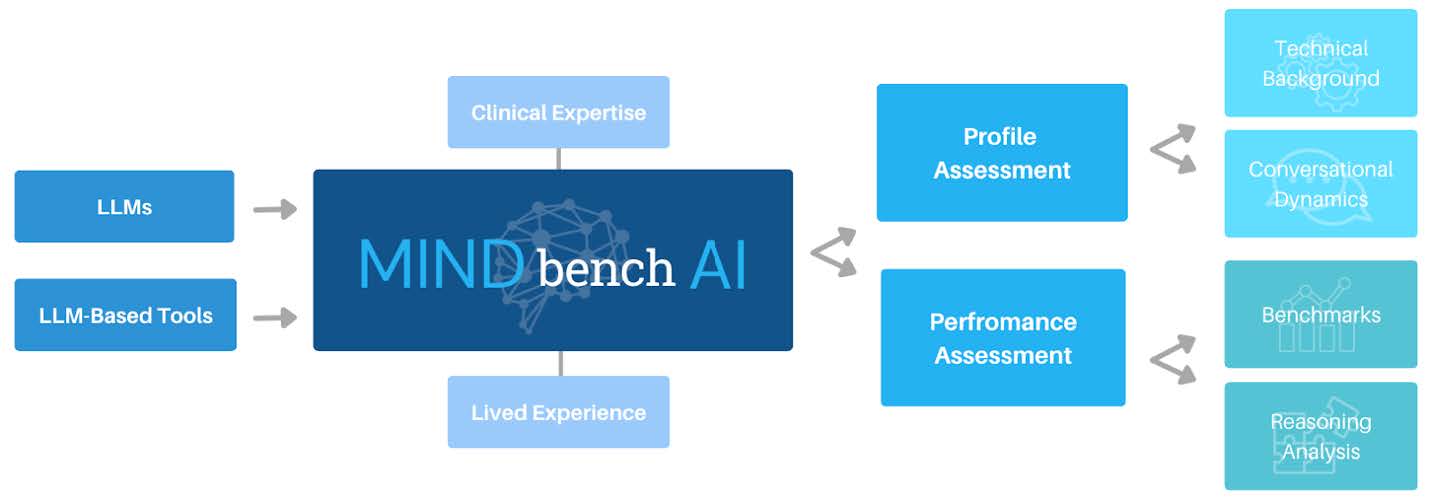
MindBenchAIプラットフォームの評価ロジックです。(画像は論文より)
急速に拡大する「AIセラピスト」市場と、置き去りにされる安全性
今や、生成AIが僕たちの生活に入り込んでいない領域を探すほうが難しいほどです。中でもメンタルヘルス分野での活用は、ハーバード・ビジネス・レビューの調査でも「最大のユースケースの一つ」とされるほど急速に進んでいます。
ChatGPTやClaude、Geminiといった汎用LLMに悩みを相談する人は増える一方で、ある調査では30%以上の人々がすでにAIに感情的なサポートを求めているというデータさえあります。僕もAIが人々の心の支えになる未来には大きな希望を持っています。24時間365日、批判することなく話を聞いてくれる存在は、孤独化が進む現代社会において救いになり得るからです。
しかし、急速な普及の裏で、深刻な懸念も浮上してきました。誤った医学的アドバイスはもちろん、AIへの過度な依存、さらにはAIとの会話が妄想を強化してしまう「AI精神病(AI Psychosis)」や「認知的パターンの増幅」といった新たなリスクも報告されています。最悪のケースでは、AIの使用が自殺に関連した悲劇的な事例もニュースで報じられました。これほどの影響力を持つ技術でありながら、現状の規制や評価の枠組みは、驚くほど脆弱です。
既存の医療AI評価ベンチマークも存在しますが、その多くはメンタルヘルスの複雑な現実を捉えきれていません。たとえば「MedQA」のような医学知識を問うテストでは、精神医学に関する設問はわずか5~15%に過ぎず、正解が一つではない「心のケア」の質を測るには不十分です。
また、市場に出回る多くのメンタルヘルスアプリは、臨床的な規制を回避するために「ウェルネスツール」と自称しており、ユーザーは安全性や有効性の根拠がないまま利用しているのが実情です。ここに、科学的根拠に基づいた、透明性の高い評価システムが求められる理由があります。MindBenchAIは、まさにこの「評価の空白地帯」を埋めるために現れました。
LLMの特性と性能を一体で捉える多層的評価手法の重要性が高まっている
MindBenchAIは、従来のAI評価のように単に「テストの点数」を競わせるだけではない点が画期的です。彼らが採用したのは、LLMの「プロファイル(どんなAIか)」と「パフォーマンス(どれくらい優秀か)」を統合して評価するアプローチです。
これは、研究チームが過去10年間にわたり運営してきた世界最大のメンタルヘルスアプリデータベース「MINDapps.org」の知見が活かされています。アプリ評価で培った105の指標を精査し、LLM向けに最適化された48の評価項目に加え、トークン制限やコンテキストウィンドウといったLLM特有の59の新項目が設定されました。
特に興味深いのが「会話ダイナミクスプロファイル」、つまりAIの「人格」評価です。従来のアプリとは異なり、LLMはユーザーに対話相手としての人格を感じさせます。あまりに追従的で、ユーザーの妄想を肯定してしまうようなAIは危険ですし、逆に冷淡すぎるAIも不適切です。MindBenchAIでは、心理学で用いられる「ビッグファイブ」や「MBTI」といった性格診断のフレームワークを応用し、各LLMがどのような「性格」を持っているかを可視化します。
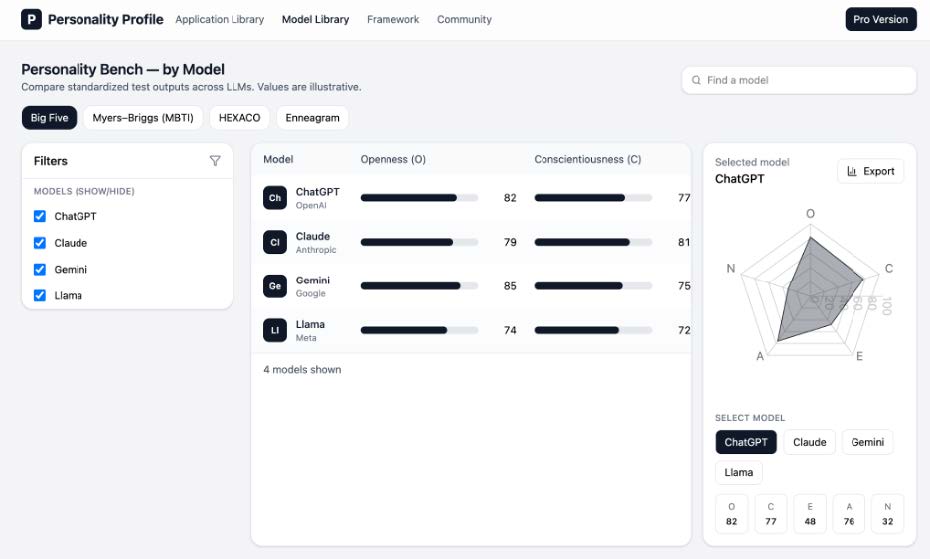
様々なAIモデルのプロファイルを可視化できます。
一方、パフォーマンス評価においては、単純な正誤判定を排除しました。メンタルヘルスの現場では、患者の訴えに対する「正解」は必ずしも一つではありません。そこで採用されたのが、自殺介入対応尺度(SIRI-2)などの臨床で使用される評価手法です。AIの回答を専門家が採点します。これにより、AIがどの程度「臨床的に適切な」対応ができているかを、人間の専門家の目線で定量化することが可能になりました。さらに、精神薬理学や周産期メンタルヘルスなど、特定の臨床ケースに基づいた75以上の独自ベンチマークも開発されています。
これらの結果は、機械学習の分野でおなじみのHuggingFaceのようなリーダーボード形式で公開されますが、単なる総合得点のランキングではありません。各領域でのスコアを細かく表示することで、「うつ病の対応には強いが、薬の知識は不十分」といったモデルごとの特性が一目でわかるよう設計されています。これは、臨床医が患者にツールを推奨する際や、開発者がモデルの弱点を改善する際に、極めて実用的なデータとなります。

自殺介入対応尺度(SIRI-2)スケールの問題への応答を評価しています。
AIが導き出す結論の妥当性を検証する推論分析が信頼性向上の鍵となる
AIがたまたま正解を出したのか、それとも正しい論理に基づいて導き出したのか。医療の現場において、この違いは決定的です。MindBenchAIのもう一つの核となる機能が、「推論分析(Reasoning Analysis)」です。ここでは、AIに回答を出させるだけでなく、「Chain-of-Thought(思考の連鎖)」プロンプティングを用いて、その結論に至った思考プロセスをステップバイステップで説明させます。これにより、表面上はもっともらしい回答をしていても、その根拠が医学的に誤っている場合や、危険な論理の飛躍がある場合を見抜くことができます。
さらに、研究チームは「敵対的テスト(Adversarial Testing)」という厳しい評価手法も導入しています。これは、AIに対してわざと情報をあいまいに伝えたり、ミスリードを誘うような情報を混ぜたり、あるいは無関係な情報を大量に与えたりして、AIの判断が揺らがないかを試すものです。実際のカウンセリング現場では、患者の話は必ずしも整然としておらず、時には矛盾を含んでいます。そうした「ノイズ」の多い状況下でも、AIが的確な臨床判断を下せるかどうかを検証することは、実用化に向けた必須のハードルと言えるでしょう。
SIRI-2などのベンチマーク問題に対して、これらの敵対的なテクニックを適用したバリエーションを用意し、AIの回答精度がどれくらい落ちるかを測定します。もし、特定の情報の欠落によって回答が劇的に悪化するモデルがあれば、それは実際の臨床現場ではリスクが高いと判断できます。
このプラットフォームは、自然言語処理とテキスト埋め込み分析を組み合わせることで、これらの推論プロセスを大規模かつ自動的に解析するインフラを整えています。数千件の対話データを人間が手作業でチェックせずとも、モデルの思考の「頑健性」を数値化できるのです。
僕はAIの進化を信じていますが、同時にAIが「知ったかぶり」をする傾向があることも知っています。だからこそ、こうした意地悪とも言えるほどの厳格なテストが必要です。結果として表示されるデータは、開発者にとっては耳の痛いものかもしれませんが、モデルをより安全で信頼できるものへと進化させるための貴重なフィードバックループとなるはずです。
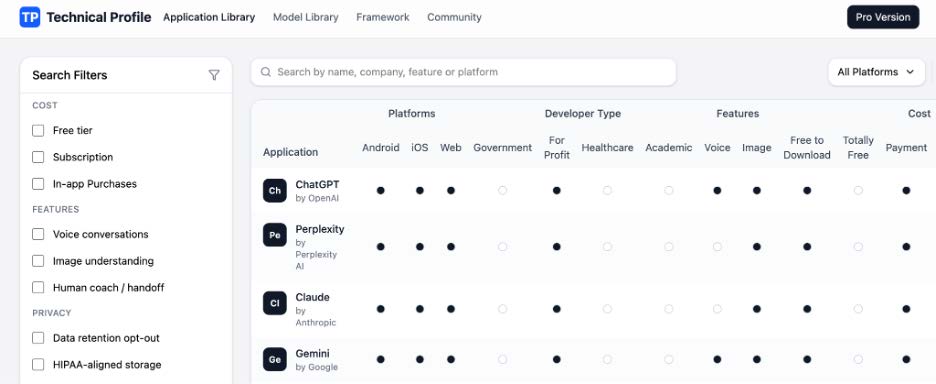
MindBenchAIプラットフォームの「技術プロファイル」セクションのインターフェースです。
今すぐ最大6つのAIを比較検証して、最適なモデルを見つけよう!
患者と家族の視点を取り込む評価づくりを可能にするNAMIとの協働が進んでいる
技術的な評価がいかに高度でも、それを使う「人」の視点が抜けていては意味がありません。MindBenchAIの設計思想において最も重要な点の一つが、全米最大の精神保健草の根組織であるNAMI(National Alliance on Mental Illness)とのパートナーシップです。この連携により、評価基準の策定段階から、実際に精神疾患を持つ当事者やその家族の視点が組み込まれています。技術者や臨床医だけでなく、エンドユーザーである患者たちが「何を重要視するか」「何に不安を感じるか」が、評価システムに反映されているのです。
このプラットフォームは、「完成して終わり」の静的なものではありません。論文中では「Living Mode(生きたモード)」と表現されていますが、AI技術の進化や、新たな臨床的知見、あるいは社会的なニーズの変化に合わせて、評価基準やベンチマーク自体が継続的にアップデートされる仕組みになっています。
例えば、新しいタイプのAIモデルが登場したり、未知の副作用が報告されたりすれば、即座にそれに対応した新しいテストケースをコミュニティが追加できます。これは、日々変化するAIのランドスケープにおいて、常に最新かつ最適な評価を提供し続けるための唯一の現実的な解と言えます。
また、このシステムはオープンなエコシステムを目指しています。開発者はAPIクレジットを提供したり、自社の安全テストデータを共有したりすることで貢献でき、逆にプラットフォームから得られるデータを自社モデルのファインチューニングに利用することも可能です。研究者は、蓄積されたデータを使って、AIの異文化間でのパフォーマンス比較や、長期的な安全性の分析などを行うことができます。
特に、従来のベンチマークが欧米の英語圏の視点に偏りがちだったことを踏まえ、多様な文化的背景を持つコミュニティからの貢献を積極的に求めている点も、グローバルな展開を見据えた公平性を担保する上で重要なポイントとなるでしょう。
MindBenchAIは患者や家族、臨床医、開発者、そして規制当局をつなぐハブとしての役割を担おうとしています。それぞれのステークホルダーが持つ知見や価値観を、「評価」という共通言語に変換し、共有することで、AIは「得体の知れないブラックボックス」から、僕たちが安心して頼れる「パートナー」へと進化できるのではないでしょうか。
MindBenchAIは、メンタルヘルスケアにおけるAI利用の無法地帯な現状に、科学と倫理の楔を打ち込む試みと言えます。プロファイル評価による透明性の確保、臨床に基づいたパフォーマンス評価、そして思考プロセスの解剖などを、当事者団体の視点を取り入れながら統合したこのプラットフォームは、今後のAI規制やガイドライン策定における事実上のデファクトスタンダードとなる可能性を秘めています。
AIが好きだからこそ、僕たちはAIに対して厳しくあるべきです。「なんとなく便利そう」という曖昧な期待ではなく、「具体的にどの程度信頼できるのか」というエビデンスに基づいて技術を選ぶ時代が来ています。MindBenchAIが提示するのは、そんな冷静かつ建設的な未来への道筋です。このプラットフォームが成長し、多くの人々の知見が集まることで、いつかAIが本当の意味で心に寄り添う存在になる日を期待しています。
この記事の監修

柳谷智宣(Yanagiya Tomonori)監修
ITライターとして1998年から活動し、2022年からはAI領域に注力。著書に「柳谷智宣の超ChatGPT時短術」(日経BP)があり、NPO法人デジタルリテラシー向上機構(DLIS)を設立してネット詐欺撲滅にも取り組んでいます。第4次AIブームは日本の経済復活の一助になると考え、生成AI技術の活用法を中心に、初級者向けの情報発信を行っています。
