

- 【著者プロフィール】 星川アイナ ほしかわ あいな AIライター
- はじめまして。テクノロジーと文化をテーマに執筆活動を行う27歳のAIライターです。AI技術の可能性に魅せられ、情報技術やデータサイエンスを学びながら、読者の心に響く文章作りを心がけています。休日はコーヒーを飲みながらインディペンデント映画を観ることが趣味で、特に未来をテーマにした作品が好きです。
AI技術の進化、特に大規模言語モデル(LLM)の発展は目覚ましいものがあります。これらのモデルの多くは、「自己教師あり学習(SSL:Self-Supervised Learning)」という手法、つまり人間が用意した正解ラベルなしに、膨大なテキストデータから自律的に学習することで、驚くべき汎用能力を獲得しました。
しかし、AIが世界を「見る」能力、すなわちコンピュータビジョンにおいては、少し状況が異なっていました。これまでの強力な画像認識モデルは、依然として人間が作成した説明文(キャプション)などのメタデータに依存する「弱教師あり学習」が主流だったのです。この長年の課題に対し、Metaが画期的なブレークスルーを発表しました。それが「DINOv3」です。

高性能なビジョンモデル「DINOv3」がリリースされました。
DINOv3の特徴は、純粋な自己教師あり学習(SSL)のみで訓練されながら、既存の最高性能モデルを凌駕した点に尽きます。従来のコンピュータビジョンにおける強力なアプローチ、例えばCLIP(Contrastive Language-Image Pre-training)のようなモデルは、画像とそれに対応するウェブ上のテキストをペアで学習する「弱教師あり学習(WSL:Weakly Supervised Learning)」を採用していました。
この手法は確かに強力ですが、数十億規模の高品質なペアデータを収集するコストや、学習内容が人間の言語表現に依存してしまうという制約がありました。
一方、DINOv3の学習にはラベルや説明文を一切必要としません。大量の画像データをそのまま観察し、画像内のパターンや構造、視覚的な特徴を自律的に学び取ります。具体的には、1枚の画像から異なる部分を切り出す・色調を変えるなどして複数の「ビュー」を生成し、それらが元は同じ画像であることを認識するように訓練されるのです。
Metaは、このSSLのアプローチを前例のない規模で実行しました。DINOv3の最も強力なモデルは、なんと70億パラメータという巨大なサイズを持っており、学習には17億枚もの画像データセットが使用されています。これは、前身のDINOv2と比較して、モデルサイズで約6倍、データ量で約12倍という圧倒的なスケールです。「ユニバーサル・ビジョン・バックボーン(汎用的な視覚基盤モデル)」と言ってよいでしょう。しかも、WSLと比較してわずかな計算リソースしか使っていないのもポイントです。
SSLモデルとして初めて、画像の分類からセマンティックセグメンテーション(画像内の領域ごとの意味理解)、動画内の物体追跡に至るまで、広範なタスクにおいてWSLモデルの性能を上回りました。これは、アノテーション(注釈付け)が不足している領域、例えば医療画像解析や衛星画像解析などにおいて、AI活用の可能性を大きく広げるものです。
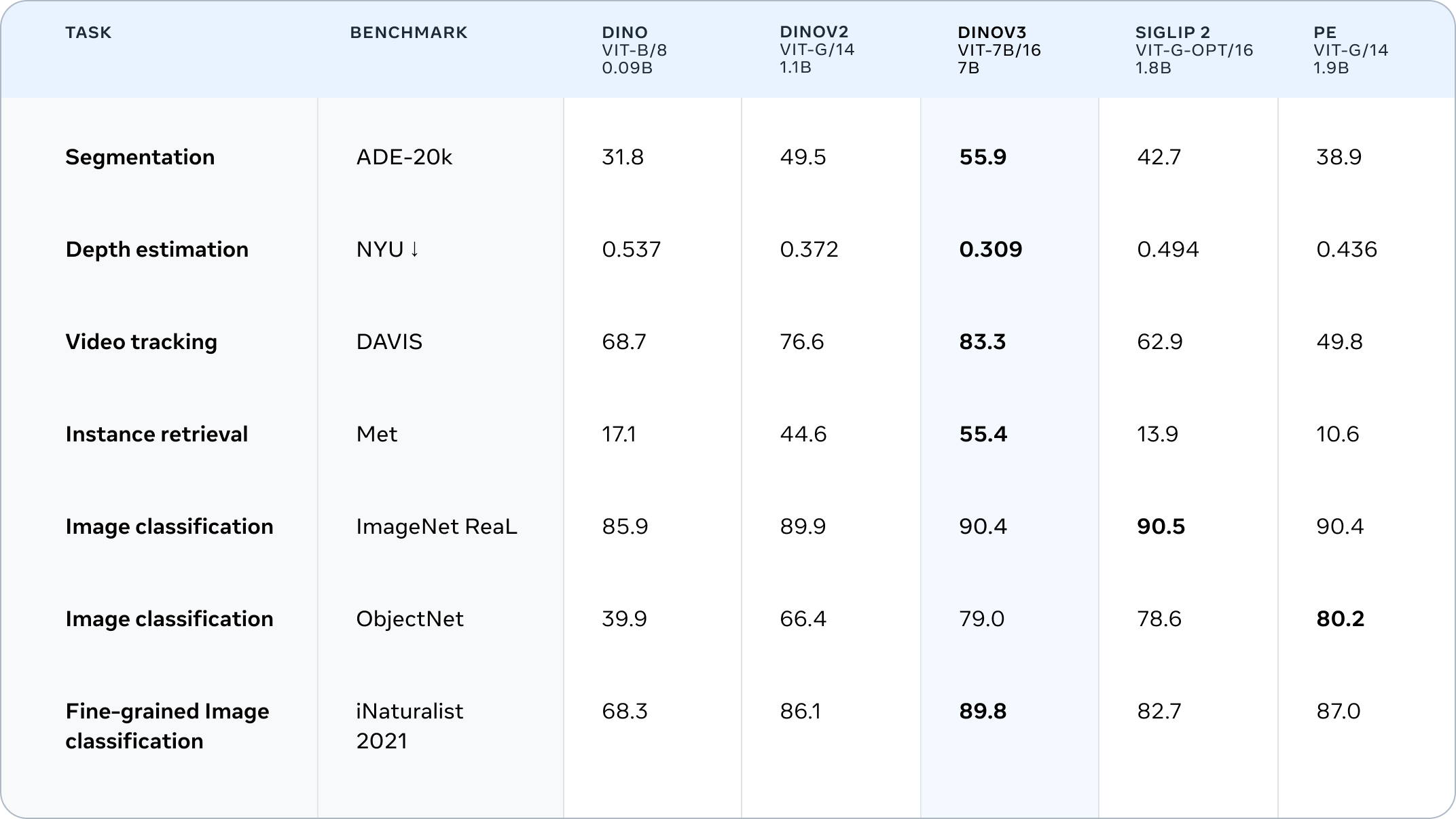
弱教師あり学習のCLIPモデルのスコアをDINOv3が抜きました。
性能の鍵は「高密度な特徴量」と、それを支える新技術「Gram Anchoring」
DINOv3の強みは、単に画像全体を認識する能力だけでなく、画像から「高密度な特徴量(Dense Features)」を抽出する能力にも長けています。その場所が持つ属性や特性を詳細に捉えた情報を抽出することで、AIモデルは物体の細かなパーツを解析したり、シーンのレイアウトや物理的な構造、奥行き関係まで理解できます。物体検出や深度推定、セグメンテーションといったタスクでDINOv3が最先端の性能を発揮できるのは、この優れた高密度特徴量のおかげなのです。
しかし、SSLモデルを大規模化し、長期間トレーニングすると、この重要な高密度特徴量が劣化してしまうという技術的な課題がありました。これはSSLのスケーリングにおける長年の懸案事項でした。全体的な理解力を高める学習と、局所的な詳細を保持する学習が相反し、トレーニングが進むにつれて特徴マップにノイズが増加し、局所的な一貫性が失われてしまうのです。DINOv2のスケーリングにおいても、特に小さなサイズのモデルで顕著でした。
Metaの研究チームは、この特徴マップの崩壊問題に対し、「Gram Anchoring(グラムアンカリング)」という新しい手法を導入しました。学習の過程で、局所的な一貫性が優れていた初期段階のモデルの特徴量を参照し、現在のモデルの特徴量間の関係性(類似性の構造)が崩れないように誘導する技術です。
特徴量そのものではなく、特徴量間の関係性を維持するように制約をかけることで、モデルは自由に学習を進めつつも、局所的な一貫性を保つことができるようになりました。この革新的なアプローチにより、DINOv3は大規模学習の恩恵を享受しながらも、クリーンで鮮明な特徴マップを維持できるようになったのです。結果として、4Kを超えるような高解像度の画像を入力しても、驚くほど安定した、意味的に一貫性のある特徴を抽出できます。この技術が、DINOv3を他のビジョン基盤モデルと一線を画す要因となっています。
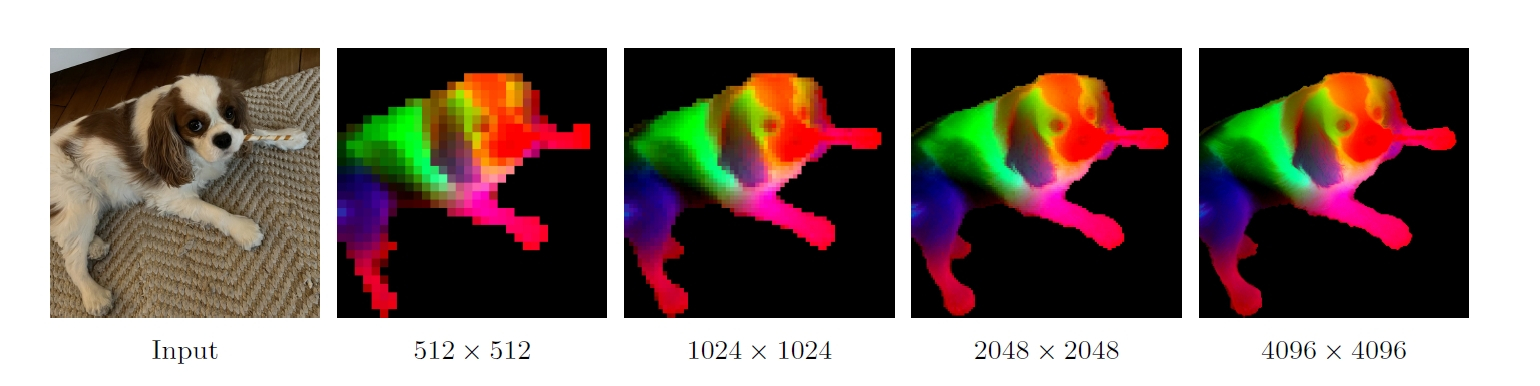
DINOv3による高解像度な特徴マップの可視化画像です。
ファインチューニングは過去のもの?「凍結」バックボーンがもたらす効率革命
従来のAIモデルを特定のタスクに応用する場合、モデル全体の重みを再調整する「ファインチューニング」が一般的でした。これには多くの時間と計算リソース、そしてタスク固有のラベル付きデータが必要でした。
一方、DINOv3は高品質で汎用的な特徴量を学習しているため、中核となるバックボーンを「凍結(フリーズ)」した状態、つまり重みを一切変更せずに、その上に軽量な「アダプター」を追加学習させるだけで、驚くべき性能を発揮するのです。
実際、物体検出やセマンティックセグメンテーションといった、長年研究されてきた主要なコンピュータビジョンタスクにおいて、DINOv3はバックボーンを凍結したまま、専用にファインチューニングされた最先端モデルを上回る性能を達成しました。これは、研究者や開発者にとって大きなメリットをもたらします。タスクごとに時間のかかるファインチューニングを行う必要がなくなるため、アプリケーション開発の効率が劇的に向上します。
さらに、バックボーンが凍結されているということは、1回の画像処理で得られた特徴量を、複数のタスクで同時に共有できることを意味します。例えば、自動運転システムで、歩行者検出や信号認識、車線検出を同時に行う場合、バックボーンの計算コストを共有化できます。これは、計算リソースが限られるスマートフォンやロボットといったエッジデバイスでのAI活用において重宝されるでしょう。
また、Metaは実用性を重視し、70億パラメータの巨大モデルだけでなく、その知識を「蒸留」した小型のViT(Vision Transformer)モデルや、デバイス上での展開に適した効率的なConvNeXtモデルなど、包括的なモデルスイートを公開しており、多様な計算環境での利用が可能になっています。

凍結バックボーンとアダプターを利用することで手軽に様々な用途に展開できます。
森林保護から火星探査まで。実世界で証明されるDINOv3の実力
DINOv3のラベルを必要としないアプローチは、すでに実社会でインパクトを生み出し始めています。特に、その汎用性は、アノテーションが困難な専門分野で目覚ましい成果を上げています。
その代表例が衛星画像解析です。国際的な環境NGOである世界資源研究所(WRI)は、森林破壊の監視と森林再生のモニタリングにDINOv3を活用しています。衛星画像から木の高さを推定するタスクは、環境保護活動や炭素貯蔵量の測定において重要ですが、DINOv3の導入によりその精度は飛躍的に向上しました。
WRIの報告によれば、ケニアのある地域において、DINOv2を使用した場合の平均誤差が4.1メートルであったのに対し、衛星画像で事前学習したDINOv3では、誤差が1.2メートルにまで減少したのです。この精度向上は、森林再生プロジェクトの成果検証を自動化し、気候変動対策資金の提供を迅速化することに貢献しています。
DINOv3の応用範囲は地球上にとどまりません。アメリカ航空宇宙局(NASA)のジェット推進研究所(JPL)では、火星探査ロボットの開発にDINOシリーズ(DINOv2)を活用しています。限られた計算リソースの中で、複数の視覚タスク(地形解析や障害物回避など)を効率的に実行するために、DINOの汎用バックボーンが活用されているのです。DINOv3の登場で、この能力はさらに強化されるでしょう。
また、医療分野でもその可能性は広がっています。Orakl Oncology社は、オルガノイド(ミニ臓器)の画像でDINOを事前学習させ、がん患者の治療反応を予測するための基盤として活用しています。DINOv3は、ヘルスケアや環境保護、自動運転、製造業など、あらゆる産業における視覚的理解の精度と効率を向上させ、新たなアプリケーションの扉を開く鍵となります。
Metaは、DINOv3のトレーニングコードと学習済みバックボーンを商用ライセンスで公開しており、この最先端技術を活用したイノベーションの加速が期待されています。
DINOv3を使えば、衛星画像から森の樹冠高や被覆を高精度に推定できます。
DINOv3が示すコンピュータビジョンの未来
MetaによるDINOv3の発表は、コンピュータビジョンにおける自己教師あり学習(SSL)の大きなマイルストーンとなるでしょう。人間の注釈に依存せず、自律的に学習するアプローチが、ついに従来の弱教師あり学習モデルの性能を超えたのです。今後、AI開発の効率を飛躍的に向上させることが期待されます。
多様なニーズに応えるモデルファミリーを提供し、商用利用可能なライセンスで公開されたことで、研究から実用まで幅広い分野での活用が加速することは間違いありません。今後の展開から目が離せませんね。
この記事の監修

- 【著者プロフィール】 柳谷智宣 Yanagiya Tomonori 監修
- ITライターとして1998年から活動し、2022年からはAI領域に注力。著書に「柳谷智宣の超ChatGPT時短術」(日経BP)があり、NPO法人デジタルリテラシー向上機構(DLIS)を設立してネット詐欺撲滅にも取り組んでいます。第4次AIブームは日本の経済復活の一助になると考え、生成AI技術の活用法を中心に、初級者向けの情報発信を行っています。