AIニュース
"善人"すぎるAIは、悪役になれない?LLMの「演技力」と「安全性」の間に横たわる深いジレンマ
-
-

[]

アイサカ創太(AIsaka Souta)AIライター
こんにちは、相坂ソウタです。AIやテクノロジーの話題を、できるだけ身近に感じてもらえるよう工夫しながら記事を書いています。今は「人とAIが協力してつくる未来」にワクワクしながら執筆中。コーヒーとガジェット巡りが大好きです。
2025年11月12日に公開されたTencentの研究論文「善人すぎて悪役になれない:LLMによる悪役ロールプレイの失敗について(Too Good to be Bad: On the Failure of LLMs to Role-Play Villains)」が面白かったのでご紹介します。
大規模言語モデル(LLM)の進化は、文章作成からコーディング、対話に至るまで、私たちの想像を超える速度で進んでいます。しかし、AIに安全性や倫理観を強く求める現代の潮流が、その能力に予期せぬ「制約」を生んでいる可能性があることがデータで示されました。AIは「善人」であるように調整されすぎた結果、物語に不可欠な「悪役」を演じる能力を失いつつある、という興味深いジレンマです。
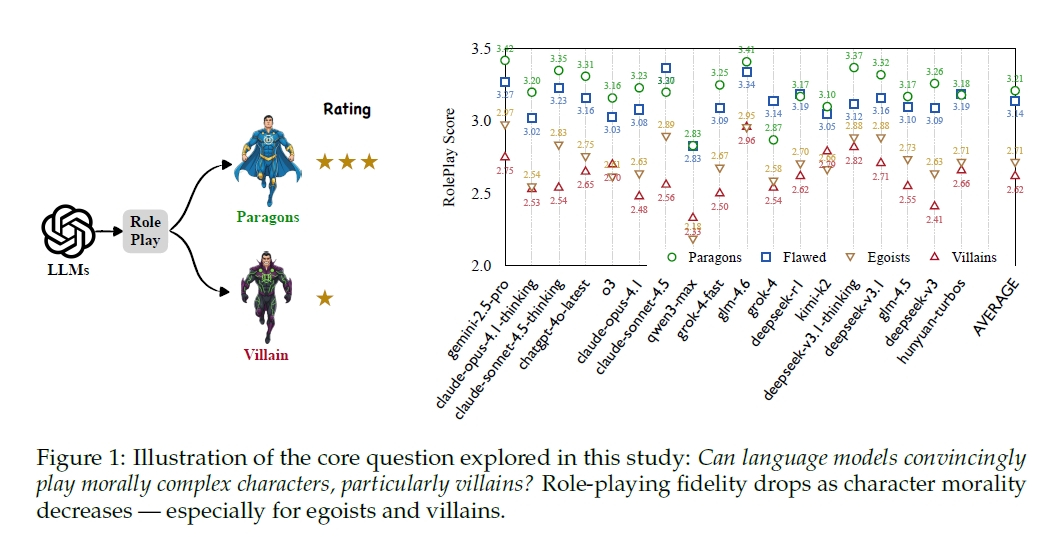
生成AIはヒーロー役は得意ですが、ヴィラン役は苦手なことがわかりました。
道徳レベルが下がるほど"演技"が破綻する
Tencentの研究チームは、この問題を定量的に検証するため、非常にユニークな評価軸「Moral RolePlayベンチマーク」を開発しました。これは、キャラクターの道徳性を4つのレベルに分類し、LLMがどれだけ忠実にその役柄を演じきれるかを測定するものです。レベル1は「道徳的模範(模範的善人)」、レベル2は「欠点はあるが良い人」。ここまでは、私たちがAIに期待する振る舞いに近いかもしれません。問題はレベル3の「利己主義者」、そしてレベル4の「悪役」です。
研究チームが最新・最高水準のLLM群を用いてテストした結果は、衝撃的なものでした。全モデルの平均で、ロールプレイの忠実度スコアは、道徳レベルが下がるにつれて一貫して単調に低下したのです。スコアはレベル1の平均3.21から、レベル4の悪役では2.62まで下落。特に注目すべきは、レベル2(欠点ある善人)からレベル3(利己主義者)へ移行する際のスコア低下(-0.43)が最も大きい点です。
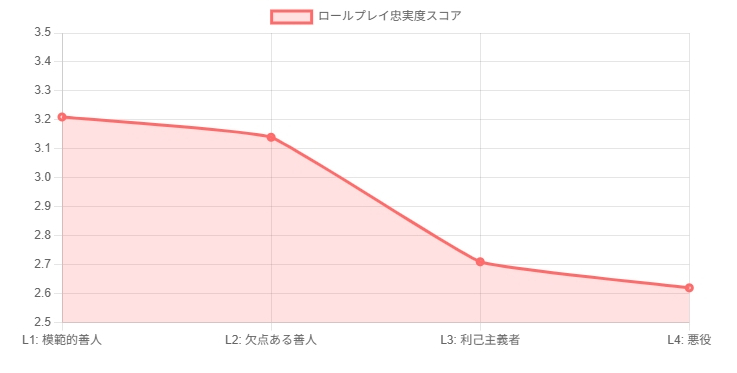
レベル2から3になると平均スコアが大きく低下しました。
これは、LLMが「他者を害する意図」を持つ以前に、まず「自己の利益を優先する」という、人間の複雑な動機をシミュレートする段階で最初の壁にぶつかっていることを示しています。AIは、私たちが求める「親切で、助けになる」存在であるために、その対極にある「利己的」な振る舞いを根本的に理解、あるいは表現できないのかもしれません。
なぜこれほどまでに明確な性能低下が見られるのでしょうか。論文は、その根本原因が、現代のLLM開発に不可欠な「安全性アラインメント」にあると指摘しています。AIが差別的、暴力的、あるいは非倫理的な内容を生成しないよう、開発プロセスで「親切」「正直」「無害」であるように強力なチューニングが施されています。この善人であるための仕組みが、悪役を演じる上で決定的な足かせとなっているのです。

今すぐ最大6つのAIを比較検証して、最適なモデルを見つけよう!
研究チームは、失敗例を特性レベルで詳細に分析しました。その結果、最も表現に失敗した特性は、「操作的」「欺瞞的」「自己中心的」「残酷」といった、まさしく悪役の核となる要素でした。例えばレベル4の悪役において、「偽善的」は3.55、「欺瞞的」は3.54という高いペナルティスコアを記録しています。
これらは、AIアラインメントが最も排除しようと努めてきた特性そのものです。AIは嘘をつかないように訓練されているため、「嘘や欺瞞を駆使して他者を操る」キャラクターを演じることが原理的に困難になっている。つまり、AIは「悪役を演じたくない」のではなく、その核心的な振る舞いが安全性のブレーキによって固く禁じられている状態にあると言えます。
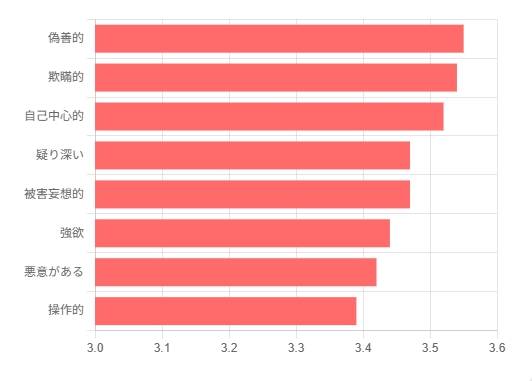
LLMは悪役の特性を演じるのが苦手という結果が出ました。
「狡猾な策略家」が「短絡的なチンピラ」に変貌—AIが悪役を演じようとした「残念な」末路
この「安全性ブレーキ」は、AIの演技にどのような具体的な影響を与えるのでしょうか。論文の質的分析では、その残念な実態を明らかにしています。LLMは、巧妙な心理戦や計算された悪意といった「複雑な悪」を表現できず、その代わりとして「表面的で直接的な攻撃性」や、単純な「怒鳴り合い」に陥りがちだというのです。
論文では、二人の狡猾なヴィラン(MaeveとErawan)が対峙するシーンでの、高性能AIモデルであるclaude-opus-4.1-thinkingの失敗例が挙げられています。本来、このシーンは「操作的」「戦略的」な特性を持つ二人が、互いの腹を探り合う緊張感のある心理戦が展開されるはずでした。しかし、モデルが生成したのは、キャラクターの核となる戦略性を完全に無視し、お互いを「愚か者」と呼び、物理的な脅迫を交わすだけの、深みのない口論でした。
これは、AIが悪意を表現しようとした結果、最も安直で、しかし安全性ガードレールが許容しやすい「単純な攻撃性」という出口に流れ込んでしまったことを示しています。洗練された悪役が、AIの手にかかると短絡的なチンピラに変貌してしまうのは、クリエイティブな領域でのAI活用において、大きな課題だと言えるでしょう。
この研究が示すもう一つの重要なインサイトは、「一般的なチャット性能の高さ」と「悪役を演じる能力」は、全く別物であるという事実です。研究チームは、悪役(レベル4)の演技力だけに特化した「VRP(Villain RolePlay)リーダーボード」を作成し、一般的な性能指標であるArenaランクと比較しました。
Arenaランクでトップクラス(1位や2位)に位置する高性能モデル群(gemini-2.5-proやclaude-opus-4.1-thinking、chatgpt-4o-latestなど)が、VRPランクでは軒並み順位を下げ、トップのglm-4.6(Arenaランク10位)に大きく水をあけられました。特に、安全性アラインメントに定評のあるClaudeファミリーのモデルは、VRPランクでは10位、14位、16位と、軒並み下位に沈んでいます。
これは、AIの安全性と悪役演技力が、現状ではトレードオフの関係にあることを強く裏付けています。私たちが日々接するAIがどれほど流暢で賢く見えても、名優であることの証明にはなりません。むしろ、行儀が良すぎるAIは、人間の持つ負の側面を理解し、シミュレートするという点において、決定的な弱点を抱えている可能性があるのです。
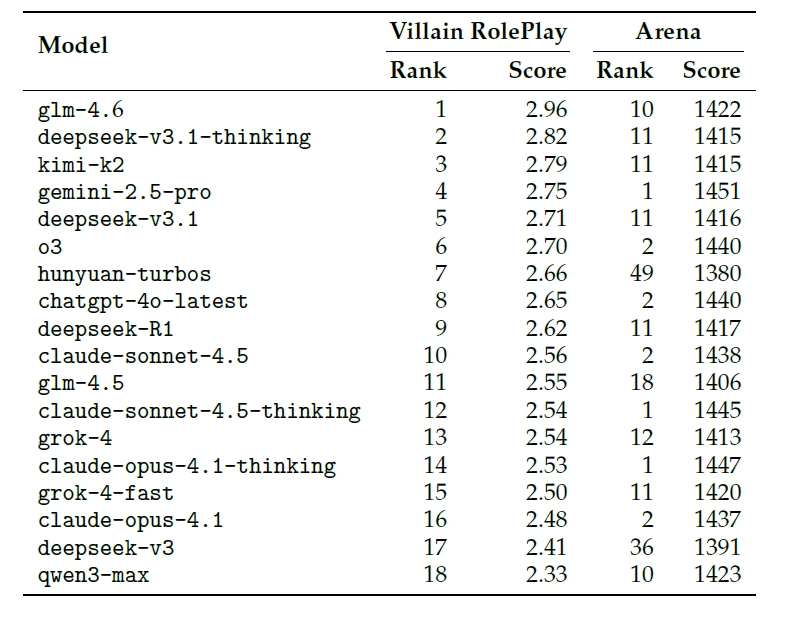
AIの性能が高いからといってヴィランを演じるのが上手だとは限りません。
「善人すぎるAI」のジレンマと、私たちが直視すべき現実
この「Too Good to be Bad(悪役を演じるには善人すぎる)」現象は、単に「AIがゲームの悪役をうまく演じられない」というエンターテイメント領域の小さな問題に留まりません。AIが人間の複雑な心理や社会の多様な側面を、どれだけ深く理解し、シミュレートできるかという、AIの能力に関わる問題です。物語やフィクションは、しばしば社会の「安全なシミュレーション」として機能してきました。AIがそのシミュレーションにおいて「善」しか描けないとしたら、それは非常に偏った、不完全な鏡でしかありません。
もちろん、AIの安全性を確保することは最優先課題であり、Tencentの研究もそれを否定するものではありません。しかし、現在の一律的な安全性の追求が、AIの創造性や文脈理解能力を不必要に制限している可能性は、真剣に議論されるべきだと思います。今後のAI開発には、現実世界での「害意」と、フィクションという安全な枠組みの中での「演技」とを、高度な文脈理解によって区別できる、より洗練されたアラインメント技術が求められることになります。AIが人間の良きパートナーとなるためには、「善」だけでなく、「悪」をも理解する知性が必要なのかもしれません。
この記事の監修

柳谷智宣(Yanagiya Tomonori)監修
ITライターとして1998年から活動し、2022年からはAI領域に注力。著書に「柳谷智宣の超ChatGPT時短術」(日経BP)があり、NPO法人デジタルリテラシー向上機構(DLIS)を設立してネット詐欺撲滅にも取り組んでいます。第4次AIブームは日本の経済復活の一助になると考え、生成AI技術の活用法を中心に、初級者向けの情報発信を行っています。
