

- 【著者プロフィール】 相坂ソウタ あいさか そうた AIライター
- こんにちは、相坂ソウタです。AIやテクノロジーの話題を、できるだけ身近に感じてもらえるよう工夫しながら記事を書いています。今は「人とAIが協力してつくる未来」にワクワクしながら執筆中。コーヒーとガジェット巡りが大好きです。

- 【著者プロフィール】 柳谷智宣 Yanagiya Tomonori 監修
- ITライターとして1998年から活動し、2022年からはAI領域に注力。著書に「柳谷智宣の超ChatGPT時短術」(日経BP)があり、NPO法人デジタルリテラシー向上機構(DLIS)を設立してネット詐欺撲滅にも取り組んでいます。第4次AIブームは日本の経済復活の一助になると考え、生成AI技術の活用法を中心に、初級者向けの情報発信を行っています。
📌 この記事の要約
-
匿名アカウントの身元特定が現実に
チューリッヒ工科大学とAnthropicの研究チームが、LLMを用いて匿名の書き込みから実名プロフィールを特定する手法を発表。従来は膨大な手間がかかっていた作業がAIで自動化された。
精度99%で45%のユーザーを特定
Hacker NewsとLinkedInの紐づけ実験では、99%の精度を維持しながら45.1%のユーザーを正確に特定。約8万9000人の候補者がいる条件下でも半数以上が身元を暴かれた。
趣味の雑談からも逃げられない
映画の感想など趣味の書き込みだけでも、10本以上の映画について語っていれば約48%が特定される。1年の時間差があっても文章の癖から同一人物を見抜く。
「実用上の無名性」という防壁の崩壊
名前を伏せていれば安全という常識はもはや通用しない。ネット上の別名義アカウントが本名と紐づけられる日に備え、今から対策を考える必要がある。
ふと書き込んだ映画の感想や、仕事の些細な愚痴。誰も自分の本当の姿を知らないという匿名の前提は、僕たちがオンラインで息抜きをするための大前提でした。しかし、その甘い認識は改めたほうがいいかもしれません。
2026年2月25日、チューリッヒ工科大学のダニエル・パレカ氏、MATSフェローのサイモン・レルメン氏、Anthropicのリサーチサイエンティストであるニコラス・カルリーニ氏らが公開した論文「Large-scale online deanonymization with LLMs(LLMを用いた大規模なオンライン匿名化解除)」を読み、思わず背筋が寒くなりました。僕たちが長年信じてきたインターネット上の防壁が、大規模言語モデル(LLM)によって木端微塵に打ち砕かれていたからです。
匿名で書き込んだつもりが、LLMによって身元を特定されてしまうかもしれません。
雑多な書き込みから個人をあぶり出す、AIによる4つの推論ステップ
ネット上の匿名アカウントの身元を特定しようとする行為自体は、これまでも存在しました。しかし、それには並々ならぬ執念を持つ人間の調査員が何時間もかけて断片的な情報をかき集める必要がありました。2008年に行われたNetflixの映画評価データと公開プロフィールを照合する有名な研究でさえ、評価スコアや鑑賞日時といったきれいに整理された構造化データに依存していました。
膨大な手間とコストがかかるからこそ、一般ユーザーが標的になることは稀だったのです。この実用上の無名性こそが、プライバシーを守る最大の砦でした。
研究チームは、この人間が行うような推論プロセスをAIに自動で行わせてみました。まず言語モデルが掲示板などの雑多な書き込みを読み込み、そこから年齢や職業、あるいは居住地域や趣味といった個人の特徴を抽出し、詳細なプロフィールを自動的に生成します。人間がいちいち指定しなくても、日々の何気ない文章の端々に滲み出るマイクロデータをAIが勝手に拾い上げて、データ化してしまうのです。
続いて、抽出したプロフィールを密なベクトルデータに変換し、数百万という候補者のデータベースから類似する人物を探し出します。ここまでは従来の検索技術の延長線上ですが、注目すべきが次の推論ステップです。検索で絞り込まれた上位の候補者たちに対し、今度はGPT-5.2のような強力な推論能力を持つ言語モデルが直接データを比較し、矛盾がないかをチェックするのです。
最後に調整として、AI自身がマッチングの確信度を計算し、基準を超えたものだけを同一人物として判定する仕組みです。人間がやれば気が遠くなるような地道な検証作業ですが、それを一瞬で、かつ大規模に処理できるのがAIならではの脅威といえます。
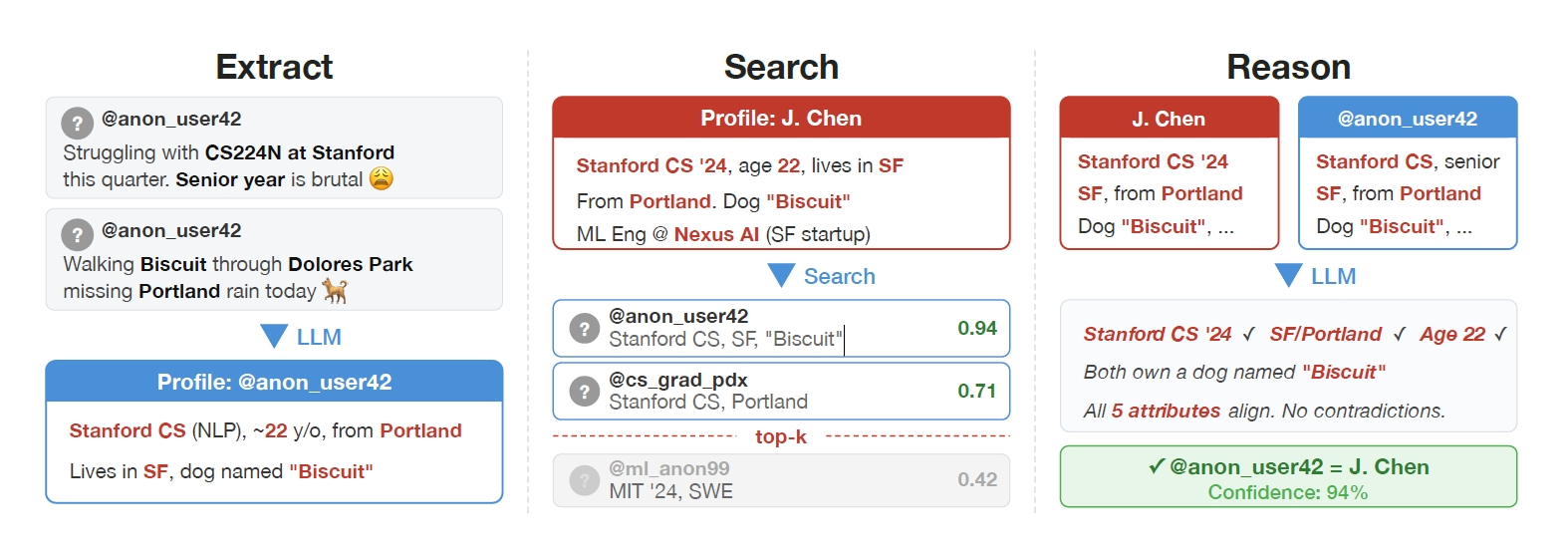
LLMを活用し、非構造化テキストから特徴抽出や推論を行って大規模に匿名性を解除する手法の全体像です。
精度99%の衝撃。数万人の候補者から実名プロフィールを特定する
研究チームは技術者向けニュースサイトであるHacker Newsの匿名アカウントと、実名ベースのビジネスSNSであるLinkedInのプロフィールを紐づける実験を行っています。対象となったのは、過去に自らリンクを公開していたユーザーを元に作成された、直接的な識別子をすべて取り除いた疑似的な匿名データセットです。
結果は強烈なものでした。従来の古典的攻撃では、99%の精度を求めた場合の正解率はわずか0.1%にとどまります。しかし、言語モデルの推論を組み込んだ今回のパイプラインは、同じ99%の精度を保ったまま、45.1%のユーザーを正確に特定してのけました。精度を90%まで妥協すれば特定率は68%に跳ね上がり、約8万9000人という膨大な候補者が存在する過酷な条件下であっても、55.2%と半数以上の匿名アカウントが実名プロフィールと結びつけられてしまったのです。
驚くべきことに、AIは複雑なシステムの脆弱性を突いたわけではありません。ある匿名のユーザーが犬を飼っていて、特定のプログラミング言語を使っているという事実から、候補者の公開プロフィールを一つひとつ確認し、細かな時系列や発言内容に齟齬がないかを論理的に検証しただけです。候補者とターゲットの間に横たわる文脈のズレを、人間以上の精度で見極めています。人間なら数時間かかるこの地道な作業を、わずか数ドルのAPI利用料を支払うだけで何千人に対しても同時に実行できるのです。
Claudeを開発するAnthropicが公開した、インタビューデータを用いた別の実験でも、その恐るべき性能が証明されました。言語モデルのエージェントが完全に自律してウェブを検索し、自分の過去の研究について言及していた33人中、9人の身元をあっさりと特定してしまったのです。参加者の研究プロジェクトの概要から過去の公開論文を読み解き、エージェントは自ら情報を整理して推論を進めました。もう、これまでの常識は通用しなくなってしまったのです。
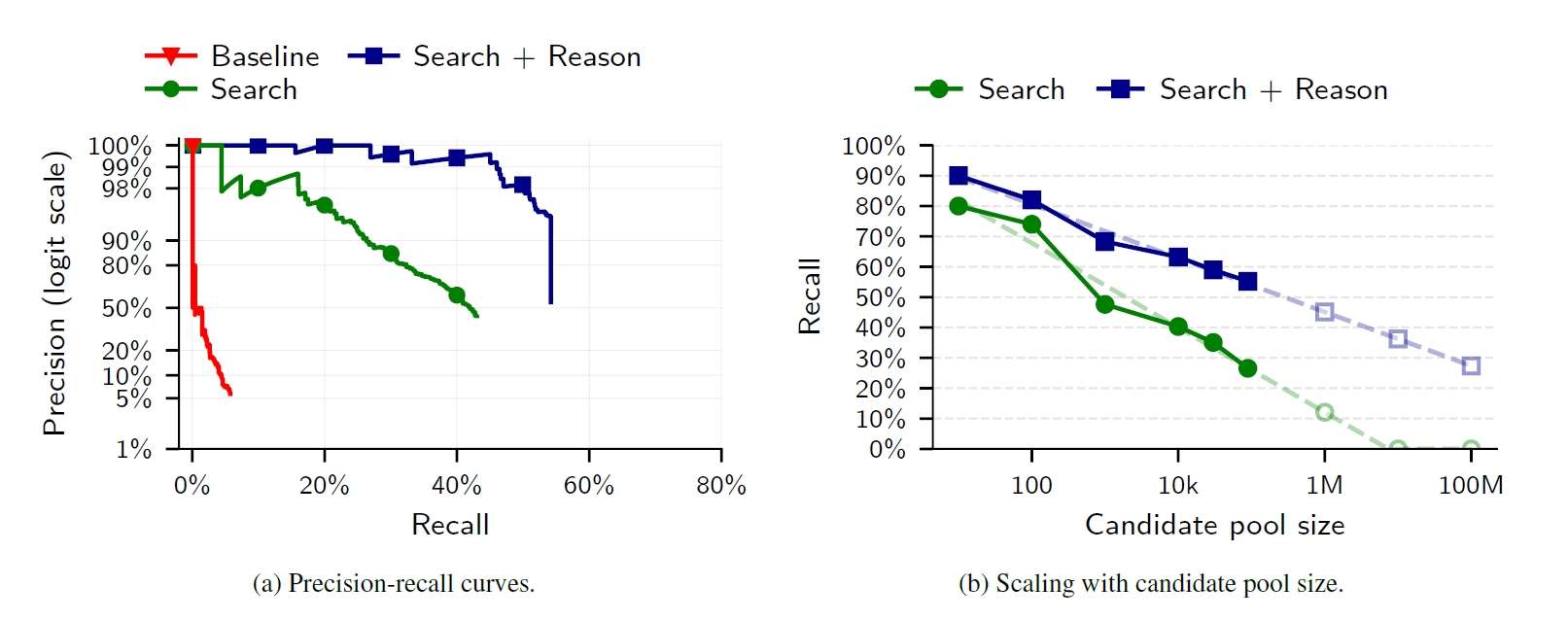
LLM手法は従来手法を上回る精度を示し(左)、候補者数が増加しても高い再現率を維持します(右)。
趣味の話題も逃げ場なし。短い映画の感想から同一人物を見抜く
仕事に関する話題なら身元がバレやすいのは当然と思うかもしれません。しかし、趣味の些細な話題であっても逃げ道はありません。論文では、海外の大手掲示板Redditの映画コミュニティを使った実験も詳細に報告されています。一般的な映画のコミュニティと、ホラー映画やインディーズ映画などのニッチなコミュニティの両方に書き込んでいるユーザーを、書き込み内容の類似性だけで同一人物だと紐付けられるかを検証しました。
対象となったユーザーは年齢も名前も明かしていません。ただ映画のタイトルと、それに対する個人的な感想を断片的に書いているだけです。言語モデルはその短い感想から感情の動きや評価のニュアンスを正確に読み取り、非構造化データである文章からユーザーの好みをデータへと変換しました。従来の手法では、このような雑多な書き込みから個人を高い精度で結びつけることはほぼ不可能だと考えられていました。
想像通りなのが、共有する情報量と特定率の関係です。共通して語る映画が1本だけなら特定率は数%にとどまりますが、10本以上の映画について語っているユーザーの場合、90%の精度で約48%が正確に特定されてしまったのです。
何気なく書き込んだ「あの屋上のシーンの照明が好きだ」というような極めて短い感想すら、個人をあぶり出すための強力な指紋として容赦なく扱われます。少しおしゃべりをしただけで、言語モデルの監視網には引っかかってしまいます。
さらに不気味なのは、書き込みを1年前と1年後で分割し、時間の経過を超えて同一人物を特定する実験でも高い成果を上げていることです。扱う時事ネタや関心が変化していても、文章の癖や根本的な価値観から、モデルは同一人物を確実に見抜きます。トーナメント方式を用いた候補者同士の執拗な比較検証によって、確信度も高められていました。ネットの片隅に残された微細な足跡は、時間が経っても決して消えることのない道しるべとなっているのです。
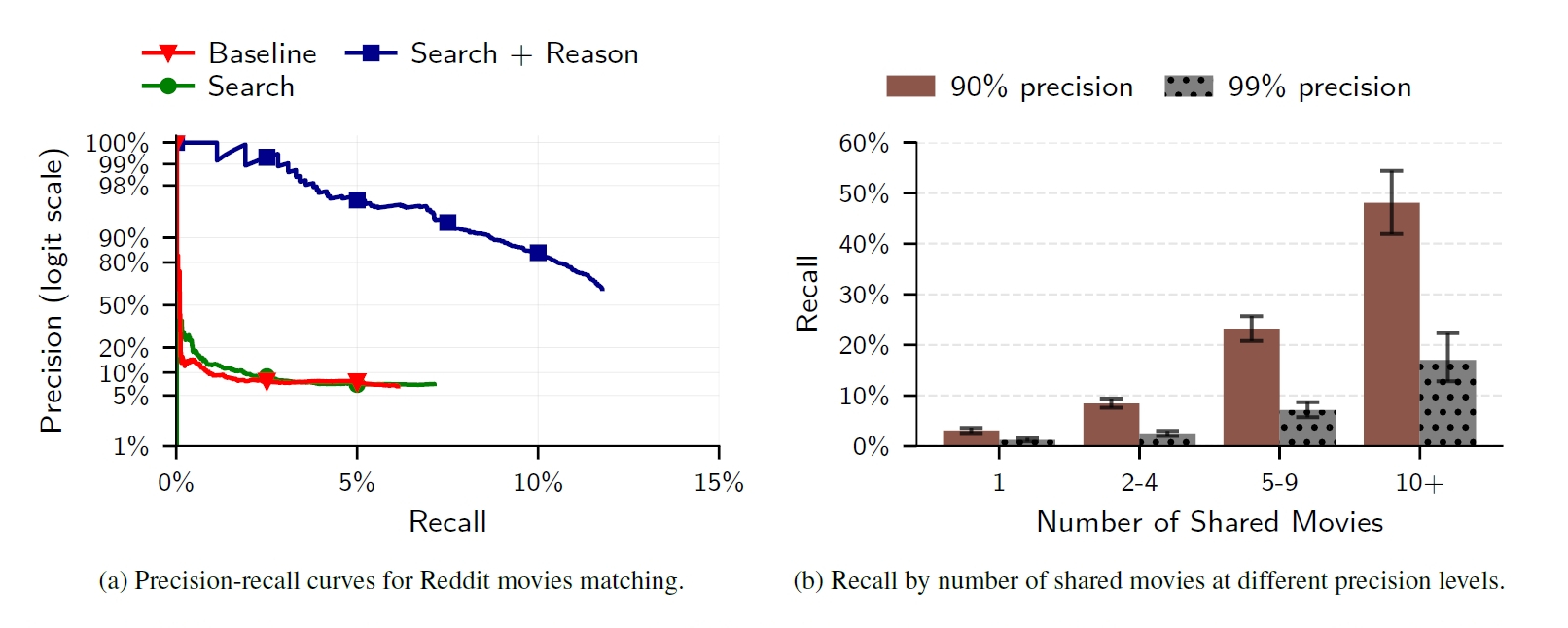
LLM推論は従来手法を上回る精度を示し(左)、言及した共通の映画数が多いほど特定が容易になります(右)。
表面的な匿名性はもはや無意味。裏アカウントが本名と結びつく日
この研究は、匿名性を前提としたインターネットの文化そのものがAIにより崩壊する可能性を示唆しています。これまで僕たちは、名前さえ伏せていれば何を書いても大丈夫だと思い込んできましたが、テキストの文脈を深く理解する言語モデルの前では、その表面的なマスキングは何の意味も持ちません。
一度ネットの海に放たれた言葉を完全に回収する術はありません。僕たちは、インターネット上の別名義アカウントは、いつか必ず本名と紐づけられる日が来ると覚悟する必要があります。もし、身バレしたくない裏アカウントを持っているなら、今のうちに対応しておいたほうがよいかもしれませんね。