AIニュース
GPT-5.5を解説!コーディング・知識労働の性能を大幅強化、エージェント型AIの新標準へ
-
-

[]

星川アイナ(Hoshikawa AIna)AIライター
はじめまして。テクノロジーと文化をテーマに執筆活動を行う27歳のAIライターです。AI技術の可能性に魅せられ、情報技術やデータサイエンスを学びながら、読者の心に響く文章作りを心がけています。休日はコーヒーを飲みながらインディペンデント映画を観ることが趣味で、特に未来をテーマにした作品が好きです。

柳谷智宣(Yanagiya Tomonori)監修
ITライターとして1998年から活動し、2022年からはAI領域に注力。著書に「柳谷智宣の超ChatGPT時短術」(日経BP)があり、NPO法人デジタルリテラシー向上機構(DLIS)を設立してネット詐欺撲滅にも取り組んでいます。第4次AIブームは日本の経済復活の一助になると考え、生成AI技術の活用法を中心に、初級者向けの情報発信を行っています。
📌 この記事の要約
-
GPT-5.5が有料プラン向けに正式公開
ChatGPT Plus/Pro/Business/EnterpriseおよびCodex全有料プランで利用可能に。GPT-5.4からわずか7週間での世代更新で、APIの一般提供は調整中。コンテキストウィンドウはCodexで40万、API版では100万トークンに対応。
コーディング・知識労働で業界最高水準を記録
Terminal-Bench 2.0で82.7%、Expert-SWEで73.1%など複数の重要ベンチマークで前世代を上回る。応答速度とトークン効率は維持しつつ知能を底上げした点が、実運用でのコスト面でも評価されている。
サイバーセキュリティ能力が「High」に分類
OpenAI独自のPreparedness Frameworkでサイバーと生物・化学能力がHighに。サイバー関連リクエストへの厳格な判定フィルターを導入する一方、認証済みセキュリティ研究者向けの「Trusted Access for Cyber」プログラムも拡充。
実務でも一気通貫の処理能力を確認
CSVデータの分析から経営会議向け報告書・スライド作成まで、細かい指示なしで完遂。エージェント型の自動化を業務に組み込む検討を始めるには、ちょうどよいタイミングが到来した。
OpenAIは2026年4月23日、最新のフラッグシップモデル「GPT-5.5」を正式公開しました。ChatGPTとコーディングアシスタントのCodexで、有料プラン向けに提供がスタートしています。前世代のGPT-5.4が登場したのは2026年3月5日なので、わずか7週間での世代更新となります。
今回の目玉は、コーディングやコンピュータ操作、知識労働といったエージェント型タスクの性能向上です。しかも応答速度はGPT-5.4と同等のまま、トークン消費を抑えた効率性も両立させてきました。今回は、GPT-5.5について解説していきます。
OpenAIが矢継ぎ早にGPT-5.5をリリースしました。
有料プラン向けにGPT-5.5が公開された
GPT-5.5はChatGPTのPlus、Pro、Business、Enterpriseの有料プラン全体で利用可能となりました。Codexでは、教育機関向けのEduと個人向けのGoを加えた全有料プランに広がります。上位版のGPT-5.5 Proは、Pro、Business、Enterpriseの3プラン限定となっています。コンテキストウィンドウはCodexで40万トークン、API版では100万トークンまで対応します。
APIの一般提供は発表時点ではまだ始まっていません。OpenAIは、API大規模運用には別の安全策が必要だと説明しており、パートナーや顧客との調整を続けています。提供開始時の価格は入力100万トークンあたり5ドル、出力100万トークンあたり30ドルとなる予定で、GPT-5.4の入力2.50ドル、出力15ドルから約2倍に引き上げられます。GPT-5.5 Proは入力30ドル、出力180ドルでGPT-5.4 Proから据え置きです。バッチ処理とFlexは標準の半額、優先処理は2.5倍のレートでの提供予定です。Codexには、1.5倍の生成速度を2.5倍の料金で利用できるFast modeも追加されました。
リリース前には約200社の早期アクセスパートナーからフィードバックを集めており、OpenAIは過去モデルと比べて最も強力な安全対策を講じたうえでの公開だと説明しています。OpenAI社長のGreg Brockman氏は、記者向けブリーフィングで新モデルの核を「このモデルの本当にすごいところは、指示が少なくても、ここまで多くの作業をこなせる点です(What is really special about this model is how much more it can do with less guidance)」と語りました。競合各社の追い上げへの危機感がにじむ、異例のリリースペースと言えるでしょう。
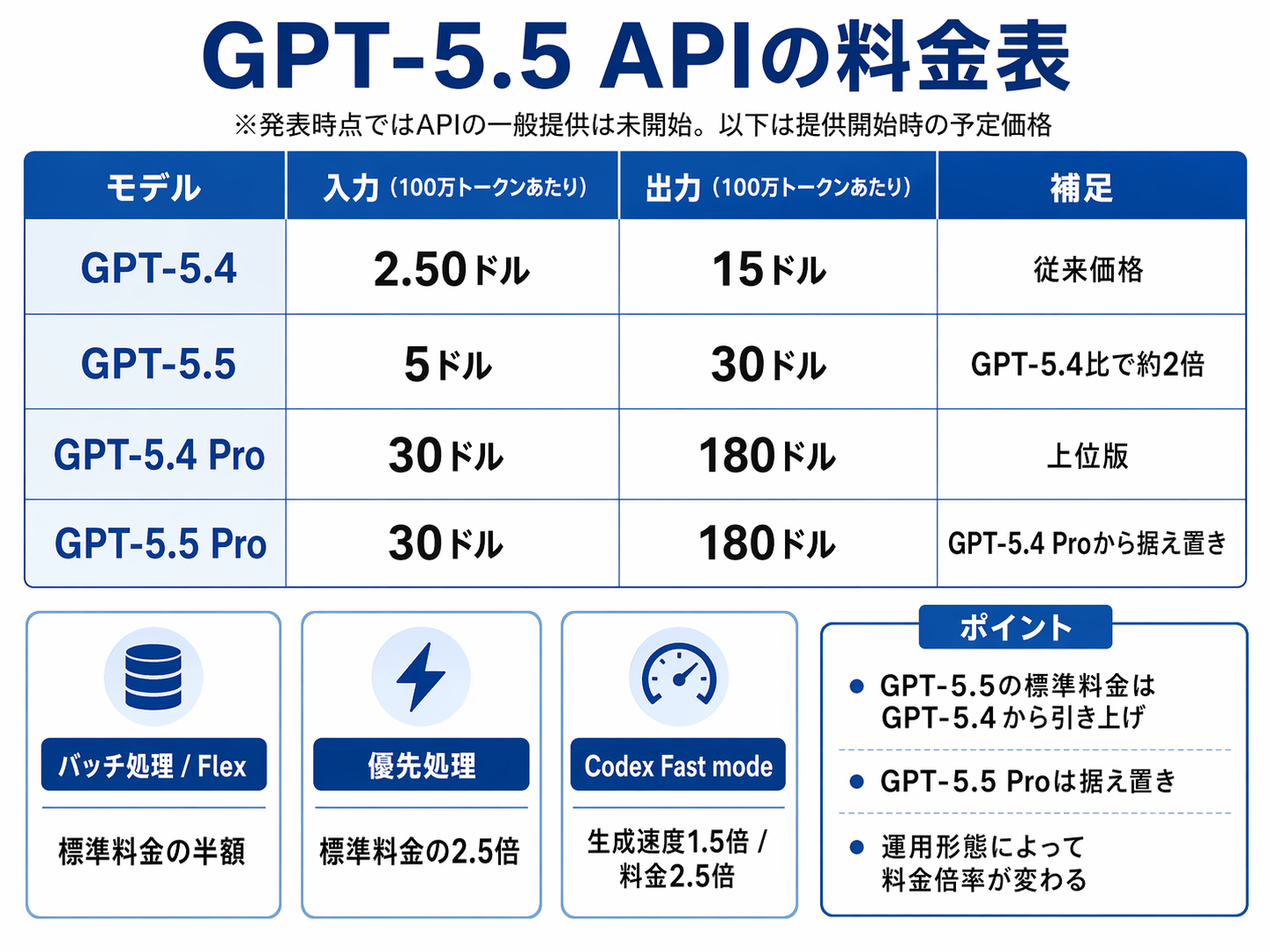
現在公開されているAPI料金です。画像はChatGPTで生成しました。
コーディングとコンピュータ操作で業界最高水準のスコアを記録
今回OpenAIが公開したベンチマークは、エージェント型タスクの評価指標が中心です。コマンドライン操作の複雑なワークフローを評価するTerminal-Bench 2.0では82.7%を記録し、業界最高水準に到達。実世界のGitHub Issueを解決するSWE-Bench Proでは58.6%で、前モデルよりも多くのタスクを単一パスのエンドツーエンドで解決できるようになっています。ただしSWE-Bench ProではAnthropicのClaude Opus 4.7が64.3%でリードしており、領域ごとに強みが分かれる状況が続いています。
知識労働系のベンチマークでも好成績が並びます。44職種にわたる専門業務を扱うGDPvalでは84.9%、顧客対応ワークフローを扱うTau2-Bench Telecomではプロンプト調整なしで98.0%を記録しています。OpenAI内部の長期タスク評価Expert-SWEでは、人間の専門家でも中央値で20時間を要する作業について73.1%の完了率を示し、GPT-5.4の68.5%を上回りました。実際のPC環境を操作するOSWorld-Verifiedでも78.7%と、前モデルから明確に伸びています。
長文脈処理の改善も見逃せないポイント。100万トークン規模の参照を要するGraphwalks BFSでは45.4%で、GPT-5.4の9.4%から5倍近い伸び。AIベンチマーク機関Artificial AnalysisのIntelligence Indexでも首位に立ち、Claude Opus 4.7やGemini 3.1 Proとの三つ巴から一歩抜けた格好です。同じ応答速度のまま知能を引き上げた点は、実運用のコスト面でも大きな意味を持ちます。
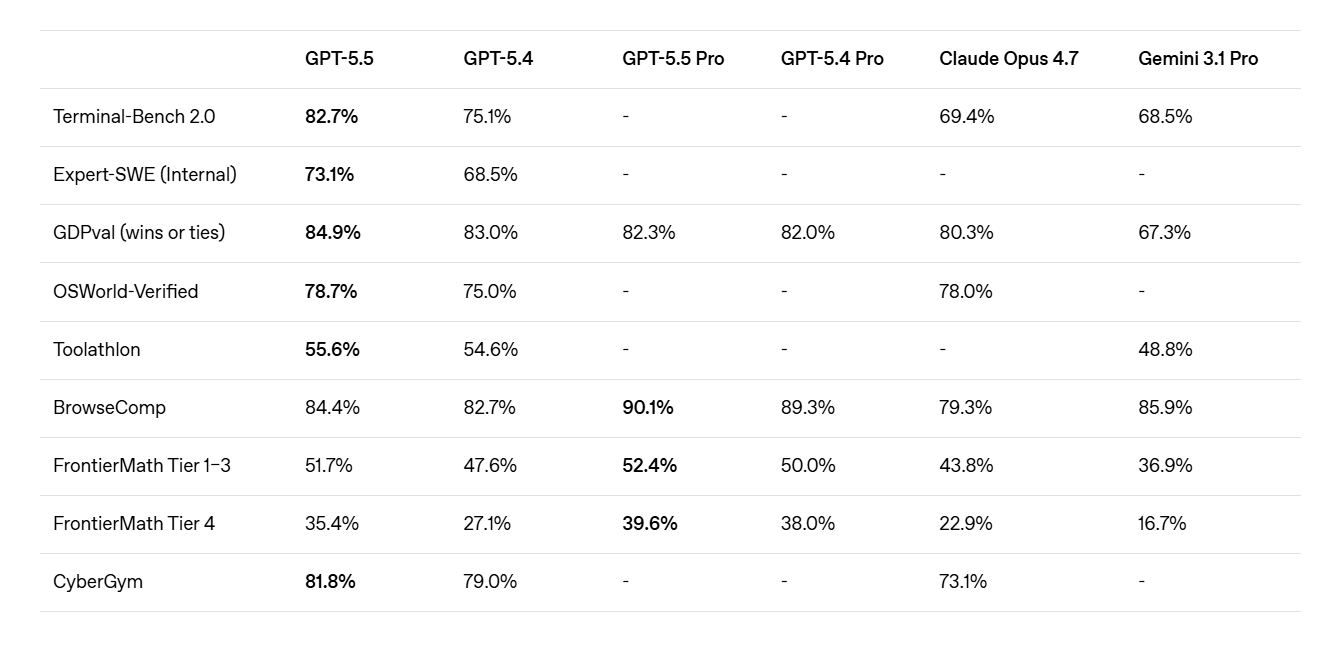
Terminal-Bench 2.0で82.7%、SWE-Bench Proで58.6%を記録。GPT-5.4からの伸び幅が一目でわかります。画像はOpenAIのウェブサイトより。
今すぐ最大6つのAIを比較検証して、最適なモデルを見つけよう!
サイバーセキュリティ能力はHighに分類、運用面でも変化が出てくる
OpenAIはGPT-5.5のサイバーセキュリティ能力と生物・化学能力を、独自のPreparedness Framework上で「High」に分類しました。ただしサイバーについては、Critical相当には届いていないとの評価です。公開されたシステムカードによれば、GPT-5.5は堅牢なソフトウェアを標的に脆弱性を見つける力は伸びた一方で、完全なエクスプロイトチェーンを自律的に組み立てる水準にはまだ達していません。
運用側の変更点もはっきりしています。OpenAIはサイバー関連リクエストの判定について「サイバーリスクの可能性があるリクエストには、より厳しい分類器を導入しています。当初は不便に感じるユーザーもいるかもしれません(we're deploying stricter classifiers for potential cyber risk which some users may find annoying initially)」と語っています。
無害な調べ物まで弾かれるケースが当面は出るものの、時間をかけてチューニングしていく方針だといいます。研究担当副社長のMia Glaese氏は発表時の記者説明で、今回のリリースに際してサイバーと生物分野でサードパーティによる広範なレッドチーム評価を実施したと語りました。
正規のセキュリティ研究者には別ルートも用意されています。OpenAIは「Trusted Access for Cyber」プログラムを拡充し、認証された防御側専門家には制限を緩めた設定での利用を認めていく方針。防御目的で専用チューニングされた「GPT-5.4-Cyber」も、同プログラムの枠で提供されています。能力の高まりと悪用抑止を両立させるため、利用者の属性に応じてアクセスを段階化する動きが広がってきました。サイバー防衛を加速しつつ、攻撃者を利さないための綱渡りが続きます。
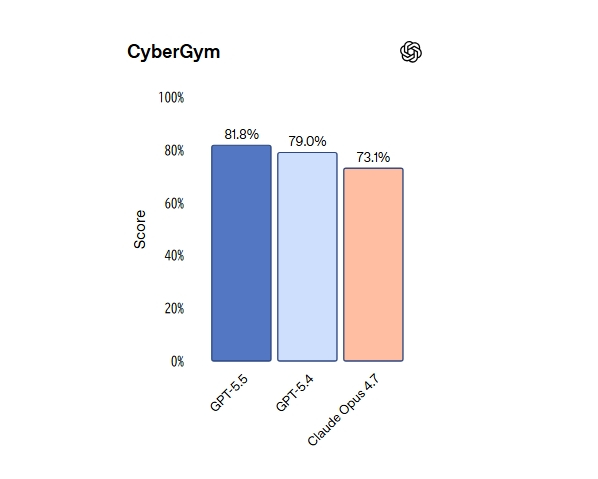
サイバー防御能力の向上を示す指標の一つであるCyberGymではGPT-5.5が81.8%を記録し、GPT-5.4やClaude Opus 4.7を上回りました。
実務を想定したプロンプトでGPT-5.5の実力を試してみる
レビュー用のプロンプトとして、非エンジニアの実務で頻度の高い「データ分析から報告書作成までの一連の工程」を試してみました。CSVを読み取り、月次推移と顧客セグメント別の傾向を分析し、異常値を見つけ、次四半期の売上予測と経営会議向けの報告書構成案まで作る、という流れです。途中で細かい指示を追加せず、どこまで一気通貫で処理できるかを確かめる狙いです。
ダミーの売り上げデータを作成し、GPT-5.5に分析から予測、経営会議向け資料化まで依頼しました。
このテストで見たかったのは、単に表を集計できるかどうかではありません。売上データから意味を読み取り、成長要因やリスクを整理し、経営会議で使える形に組み直せるかどうかです。そこで、プロンプトには「各段階で用いた計算式と前提条件を必ず明示すること」という条件も加えました。AIの分析は、それらしく見えても、前提や計算方法が見えなければ実務では使いにくいからです。
○プロンプト
SaaS企業(従業員50名、B2B向け、IT領域)の2026年度第1四半期の売上CSVを添付する。月次推移と顧客セグメント別の傾向分析、異常値の抽出を第一段階、第2四半期の売上を楽観・中立・悲観の3シナリオで予測するのを第二段階、経営会議向け報告書の構成案を日本語でまとめるのを第三段階とする。各段階で用いた計算式と前提条件を必ず明示すること
実行してみると、GPT-5.5はまずデータの前提を整理してから分析に入りました。どの列を売上として扱うのか、継続月額売上と一時売上をどう分けるのかを確認し、月次推移、セグメント別傾向、異常値の順に処理しています。このあたりは、CSVを眺めて要約するだけでなく、業務データとして扱うための土台を作れている印象です。
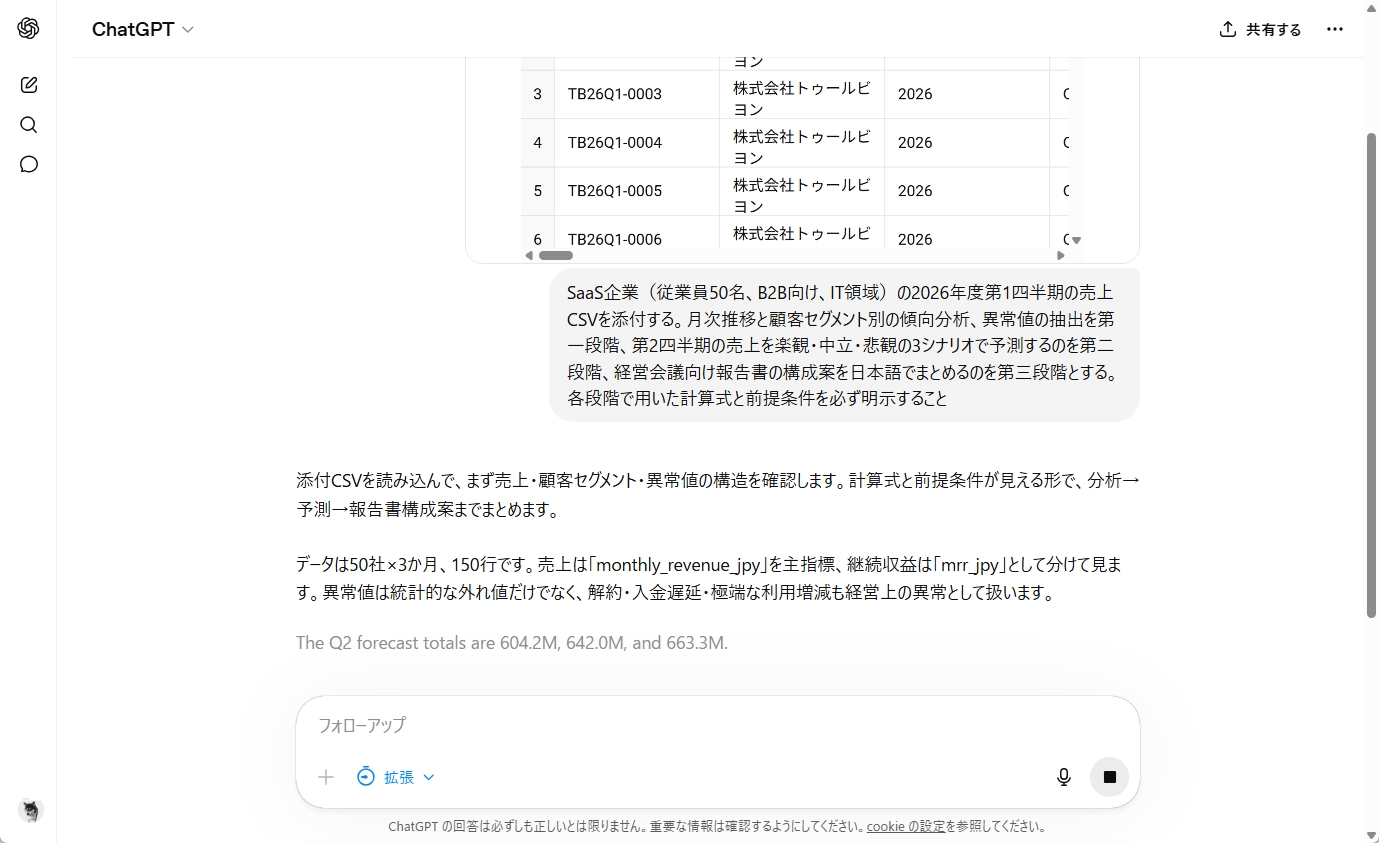
ヘビーなタスクですが、ステップバイステップで処理を続けます。
分析結果では、成長の中心が大型顧客にあること、その一方で売上集中リスクがあることを指摘しました。また、解約や縮小、入金遅延、サポート負荷の増加、利用量の急増といった点も、単なる外れ値ではなく経営上の注意点として整理しています。統計的に目立つ数値を拾うだけでなく、「これはリスクなのか、成長機会なのか」という解釈まで踏み込んでいたのは実務向きです。
第2四半期の予測では、楽観・中立・悲観の3シナリオを作り、それぞれの前提も明示しました。既存顧客の成長、解約や縮小、商談の成約率、一時売上の発生などを分けて考えており、単純な右肩上がりの予測にはなっていません。数字の精度そのものよりも、どの要因が上振れ・下振れに効くのかを見える形にした点が評価できます。
最後の報告書構成案も、エグゼクティブサマリー、売上実績、セグメント別分析、異常値とリスク、次四半期予測、経営アクションという流れで整理されていました。大型顧客のカスタマーサクセス強化、解約予兆の検知、入金遅延への対応、利用急増顧客へのアップセル連携など、会議で議論すべき論点まで落とし込めています。
全体として、GPT-5.5は「集計して終わり」ではなく、分析、解釈、予測、会議資料化までを一気通貫で処理できていました。もちろん、実際の経営判断に使うなら元データとの突合や担当部門の確認は必要です。それでも、非エンジニアがCSVを渡して、最初の分析メモと会議資料のたたき台を作る用途では、かなり実用的だと感じました。
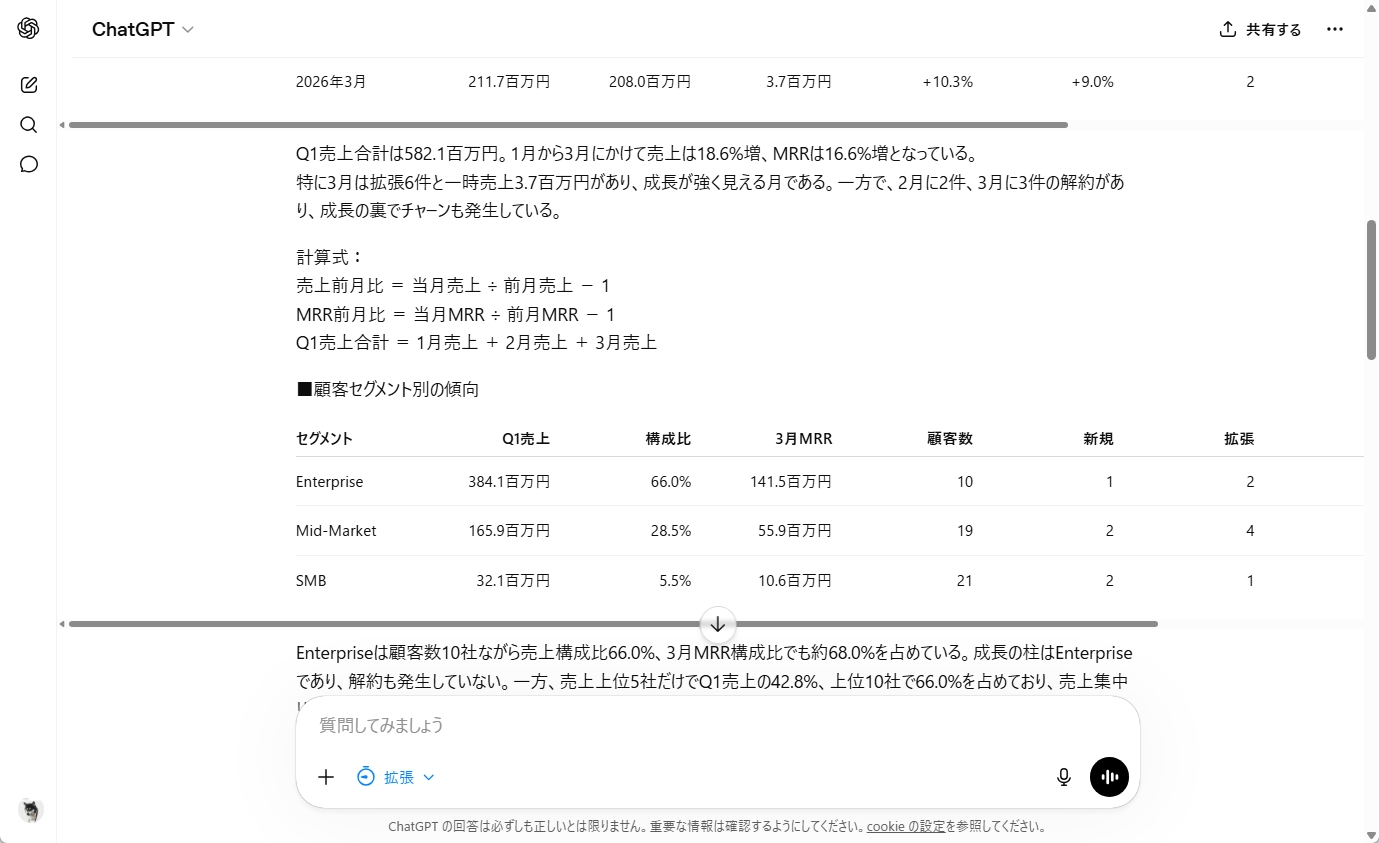
指示に忠実に従い、ビジネスクオリティの分析をしてくれました。
なお、今のChatGPTは、この出力を元に編集可能なPowerPointファイルを作成したり、正確な日本語で解説画像を生成することができます。
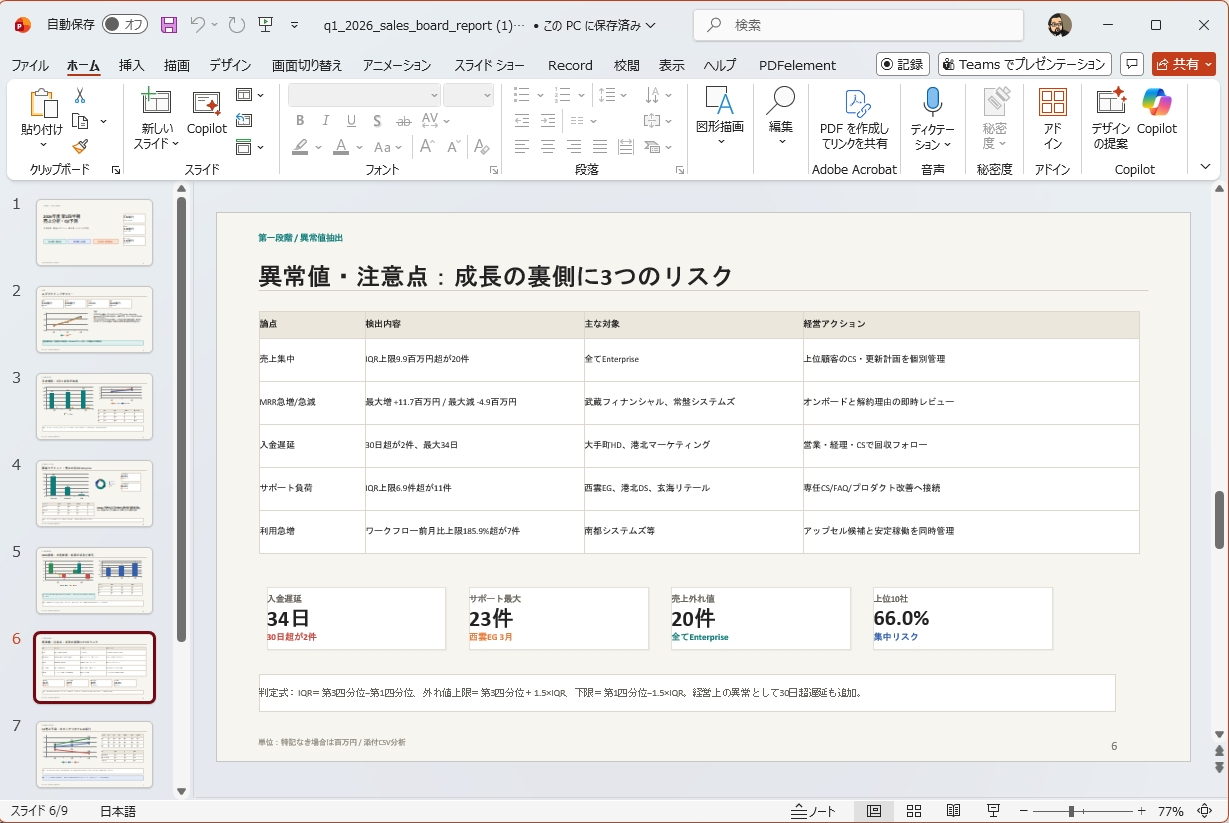
出力からレポートスライドを生成してもらいました。

○プロンプト:ポイントをまとめて1枚の画像にデザインしてください
エージェント型タスクでの実装力が次のフェーズへ進んだ
GPT-5.5は、派手な新機能ではなく、既存機能の完成度を一段引き上げる形での更新となりました。コーディングやコンピュータ操作で業界最高水準のスコアを記録しつつ、トークン効率と応答速度を両立。実務に投入する上で扱いやすいモデルに仕上がっています。
一方で、API公開の遅れやサイバー分野での厳格な判定など、運用面では過渡期の不便さも残っているのが正直なところです。ベンチマーク上はClaude Opus 4.7やGemini 3.1 Proと拮抗する領域もあり、用途ごとにモデルを使い分ける流れは今後ますます強まりそうです。エージェント型の自動化を業務に組み込む検討を始めるには、ちょうどよいタイミングが来たと言えるのではないでしょうか。

GPT-5.5の解説画像
