AIニュース
学習データが「1万分の1」に? Googleが実証したLLMファインチューニングの革命的効率化手法
-
-

[]

星川アイナ(Hoshikawa AIna)AIライター
はじめまして。テクノロジーと文化をテーマに執筆活動を行う27歳のAIライターです。AI技術の可能性に魅せられ、情報技術やデータサイエンスを学びながら、読者の心に響く文章作りを心がけています。休日はコーヒーを飲みながらインディペンデント映画を観ることが趣味で、特に未来をテーマにした作品が好きです。
大規模言語モデル(LLM)の能力を特定のビジネス分野で最大限に引き出すためには、「ファインチューニング(特定のタスクに特化させる調整作業)」が不可欠です。しかし、このファインチューニングには、高品質な学習データを大量に準備しなければならないという大きな課題がありました。データの収集とラベリングにかかる膨大なコストと時間は、AI開発のボトルネックとなっています。皆さんの組織でも、この「データの壁」に直面しているのではないでしょうか。
ところが、2025年8月7日、Googleがこの常識を覆すような研究成果を発表しました。エンジニアリングマネージャーのMarkus Krause氏とリサーチサイエンティストのNancy Chang氏が主導したこの研究は、新しいアクティブラーニングの手法により、ファインチューニングに必要なデータ量を最大で1万分の1にまで削減しつつ、モデルの性能を大幅に向上させることに成功したのです。今回は、この革新的なデータキュレーションプロセスと、驚異的な実験結果について解説します。

これまでにないキュレーションプロセスを経ることで効率的にファインチューニングができるようになります。
広告の安全性確保という難題と、LLM学習が抱える「データ依存」のジレンマ
Googleが今回この新しい手法の開発に取り組んだ背景には、「安全でない広告コンテンツの分類」という非常に困難な課題がありました。インターネット上の広告には、ユーザーを欺くクリックベイト(釣り広告)や、各種ポリシーに違反するコンテンツが紛れ込んでいます。
現在、日本でもSNSで有名人の写真を不正利用したりAIで偽造したりして、投資詐欺やフィッシング詐欺に誘導する詐欺広告が問題になっています。当然、プラットフォーマーも詐欺広告を排除したいのですが、技術的ないたちごっこが続いている状況なのです。
釣り広告や詐欺広告を正確に識別するには、単語の表面的な意味を追うだけでは不十分です。広告が持つ深い文脈や、地域ごとの文化的背景までも理解する必要があり、これは従来の機械学習システムよりもLLMが強みを発揮する領域です。しかし、この複雑なタスクのためにLLMをファインチューニングしようとすると、高い忠実度を持つトレーニングデータが不可欠となります。そして、専門家による高品質なデータを必要な規模で収集・整理(キュレーション)することは、非常に困難でコストがかかる作業なのです。
従来のようなデータ集約型のアプローチは、特に広告の安全性のように変化の激しい分野では、維持管理が難しいという問題も抱えています。安全ポリシーが変化したり、新しいタイプの不正広告が出現したりすると、モデルが最新の状況に対応できなくなる「コンセプトドリフト(概念のずれ)」が発生します。
変化に対応するためにはモデルを再トレーニングしなければなりませんが、その都度膨大なデータを集め直していては、コストも時間もかかりすぎてしまいます。最悪の場合、全く新しいデータセットで一から学習し直す必要も出てくるでしょう。したがって、トレーニングに必要なデータ量を削減することは、変化に対応し続ける上で最も重要な課題の一つでした。
この課題を解決するために開発されたのが、新しい「スケーラブルなアクティブラーニングのためのキュレーションプロセス」です。アクティブラーニング(能動学習)とは、モデルにとって学習価値の高いデータを効率的に選択し、人手によるラベル付け(アノテーション)のコストを最小限に抑える手法のことです。
Googleの新しいプロセスでは、数千億もの事例を含むデータセットの中から、アノテーションを行う価値が最も高い事例を反復的に特定し、その結果得られた専門家のラベルをファインチューニングに使用しました。
鍵は「モデルの混乱」にあり。学習に最も効果的なデータを特定する革新的プロセス
Googleが開発したキュレーションプロセスのポイントは、「モデルが判断に迷っている領域」にこそ、学習のための重要な情報が眠っているという考え方です。
まず、ゼロショット(事前学習のみ)またはフューショット(少数の例題を与える)の初期モデルLLM-0から始めます。例えば、クリックベイトの定義を説明し、「この広告はクリックベイトですか?」と尋ねるプロンプトをLLM-0に与えます。LLM-0は、膨大な広告データに対して「クリックベイトである」または「良性である」というラベル付けを自動で行い、大規模なラベル付きデータセットを生成します。
もちろん、この段階ではまだファインチューニングされていないため、モデルの精度は高くありません。また、実際のトラフィックではクリックベイト広告は全体の1%未満と非常に少ないため、データは不均衡な状態となっています。
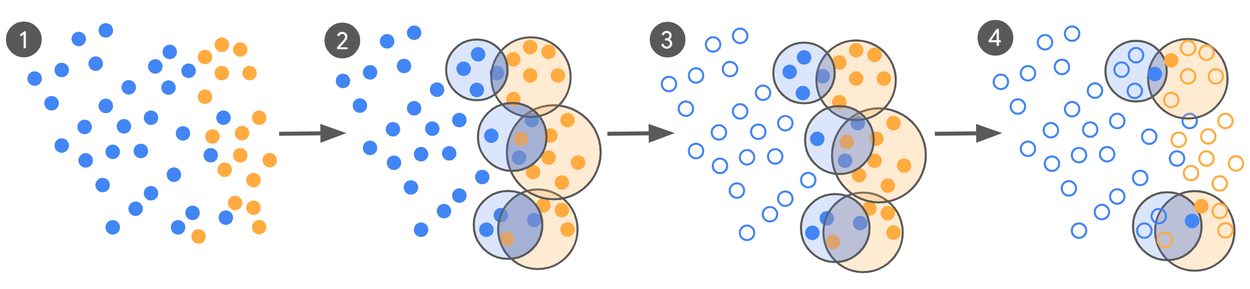
ここからが独創的な部分です。最も情報量の多い事例を見つけるために、研究チームは「クリックベイト」とラベル付けされた事例群と、「良性」とラベル付けされた事例群を、それぞれ別々にクラスタリング(類似した特徴を持つデータごとにグループ化)します。
すると、いくつかのクラスターが互いに重なり合って現れることがあります。この「重なり合ったクラスター」こそが、モデルがクリックベイトと良性の事例を混同している可能性が高い領域、すなわち判断の「決定境界」付近を示しているのです。
次に、そのような重なり合ったクラスターのペアごとに、互いに特徴が非常に近い位置にあるにもかかわらず、異なるラベル(一方はクリックベイト、もう一方は良性)を持つ事例のペアを見つけ出します。そして、これらのペアを人間の専門家に送り、意見を求めるのです。すべてのデータについて人間が判断を下す必要がないので、大幅にコストと時間を節約できます。
この方法によって最終的に得られるキュレーションされたデータセットは、決定境界に沿った最も紛らわしい事例を含んでいるため「情報量が多く」、かつその決定境界に沿った様々な異なる領域から抽出されているため「多様性がある」ものとなります。
専門家から提供された高品質なラベルを使ってモデルをファインチューニングし、次のバージョンのモデルを作成。このプロセスを、モデルと専門家の判断の一致度が十分に高まるか、あるいは改善が頭打ちになるまで繰り返します。
今すぐ最大6つのAIを比較検証して、最適なモデルを見つけよう!
学習データ99.5%減で精度は最大65%向上!驚異の実験結果が示す「品質」の重要性
広告の安全性に関する分類はグレーな判断が多く、専門家のあいだでも見解が割れやすい領域です。そのため、唯一の正解を前提とする適合率や再現率だけでは評価しにくいのです。そこで研究チームは、偶然の一致を差し引いて評価者同士の一致度を測る「コーエンのカッパ係数(Cohen’s Kappa)」を使いました。一般に0.8を超えると非常に高い一致と見なされます。
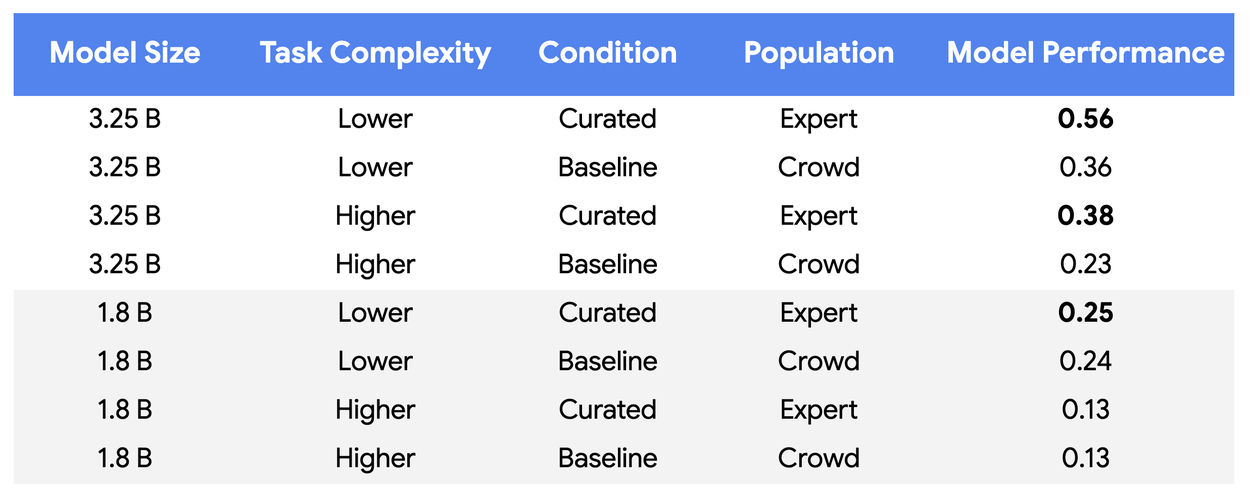
実験では、専門家が付けたラベルの品質は約0.8に達した一方、クラウドソースのデータは0.41〜0.59にとどまりました。クラウドソースを安定して上回るには、カッパ0.8超の高忠実度ラベルが鍵だと分かります。つまり、データキュレーションの成否は量ではなく、「本当に一致しているか」をどこまで担保できるかにかかっているのです。
専門家の方が完ぺきに合意し、クラウドのデータでは判断がぶれることがわかりました。
この前提に立つと、新しいキュレーションプロセスの強さがはっきり見えてきます。学習データを従来の10万件から500件未満まで圧縮し、99.5%以上も削減しても、人間の専門家が下した判断との一致度は最大65%も改善しています。大量のクラウドソースデータを学習させたベースラインよりも、質を厳選した少量データのほうが、むしろ整合性を高められたという結果です。
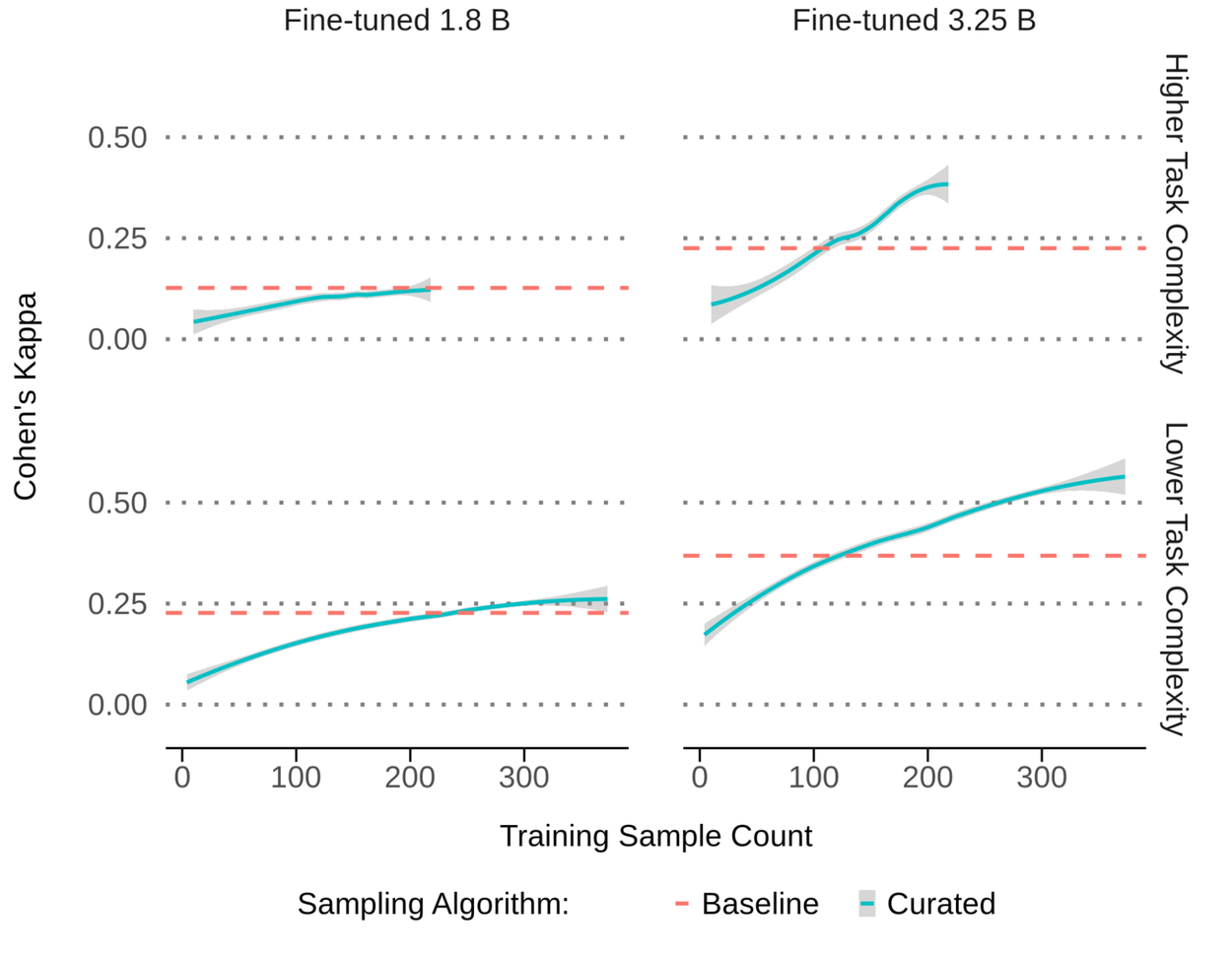
検証には、規模の異なる2つのLLM、Gemini Nano-1(18億パラメータ)とNano-2(32.5億パラメータ)を使い、複雑さの異なる2種類のタスクで評価しました。比較対象としては、クラウドソース由来の10万件サンプルを用いた従来型の学習をベースラインに置いています。新プロセスでは、専門家による高忠実度ラベルを軸に、モデルの更新とフィードバックを数回回す反復的なデータキュレーションを行いました。
その結果、より大きいモデルでは5〜6回の反復、つまり約250〜400件というごく少ない学習サンプルで十分な効果が出ました。専門家の判断に対する一致度も55〜65%向上しています。データ量を1000分の1まで減らしても性能が上がる、というのが本質的なポイントです。さらに本番に近い大規模モデルでは、ケースによって必要データ量を1万分の1まで減らせる可能性も示されました。一方で、比較的コンパクトな1.8B級モデルでは効果は限定的で、小型モデルでは利得が出にくい傾向も見えています。
モデルのサイズが小さいと新しいキュレーションプロセスはあまり効果を発揮しませんでした。
まとめると、まずカッパ係数で「良いデータ」を定義し、その基準を満たす高忠実度ラベルだけを少量に絞って反復学習させる。この組み合わせが、データ量の劇的削減とアライメント向上を同時に実現しました。量を積み上げるより先に、一致度0.8超の品質を安定して確保し、その品質を損なわない設計で学習を回すことが、曖昧さが本質の領域で成果を伸ばす近道といえそうです。
品質の良いデータなら少ない量で充分に学習させることができます。
Googleによる今回の発表では、LLMのデータセット構築において、「量」よりも「質と情報量」が重要であることが実証されました。情報量の多い、より少数の事例に焦点を当てるよう慎重にキュレーションすることで、はるかに少ないデータで同等以上の性能を達成できるのです。
このキュレーションプロセスは、問題空間全体に広く網をかけることができるLLMの強みと、最も困難な事例に効率的に集中できるドメイン専門家の強みの両方を活用するものです。ほんの一握りの事例でモデルを再トレーニングできる能力は、広告の安全性のように状況が急速に変化するドメインに対応する上で特に価値があります。
私たちが目指すべきは、データのボトルネックから脱却し、高い忠実度のラベルをより柔軟かつ効率的に使用できるシステムです。Googleが示したアプローチは、AI開発の効率を加速させ、変化に強いシステムを構築できるようになる一助になるでしょう。
この記事の監修

柳谷智宣(Yanagiya Tomonori)監修
ITライターとして1998年から活動し、2022年からはAI領域に注力。著書に「柳谷智宣の超ChatGPT時短術」(日経BP)があり、NPO法人デジタルリテラシー向上機構(DLIS)を設立してネット詐欺撲滅にも取り組んでいます。第4次AIブームは日本の経済復活の一助になると考え、生成AI技術の活用法を中心に、初級者向けの情報発信を行っています。
