AIニュース
特定の任務に特化させるため生まれた超小型AI「Gemma 3 270M」、Googleが示すスペシャリストの船団とは
-
-

[]

アイサカ創太(AIsaka Souta)AIライター
こんにちは、相坂ソウタです。AIやテクノロジーの話題を、できるだけ身近に感じてもらえるよう工夫しながら記事を書いています。今は「人とAIが協力してつくる未来」にワクワクしながら執筆中。コーヒーとガジェット巡りが大好きです。
AIモデルはこれまで「大きければ大きいほど賢い」という考え方が主流でした。モデルの規模を示すパラメータ数を競い合い、より多くの知識を詰め込もうとする開発競争が繰り広げられてきたのです。しかし、その巨大化は、膨大な運用コストや導入のハードルといった課題も生み出しています。
「AIは便利そうだが、自社の業務にはオーバースペックでコストが見合わない」と感じているビジネスパーソンも多いのではないでしょうか。そんな中、8月14日にGoogleが発表した最新モデル「Gemma 3 270M」は、この潮流に一石を投じる存在として注目を集めています。
極めてコンパクトなサイズでありながら驚くべき能力を秘めたこのモデルは、AI開発のスタイルが変化するきっかけになるかもしれないからです。今回は、Gemma 3 270Mの技術やビジネスの現場にもたらす変化について解説します。

2025年8月14日、「Gemma 3 270M」が発表されました。
適材適所の考え方が生んだ、新しいAIの形「マイクロスペシャリスト」
Gemma 3 270Mは、Google DeepMindが公開した最新の軽量大規模言語モデル(LLM)です。「Gemma 3」ファミリーには、より大規模な1B(10億)から27B(270億)までのモデルも存在しますが、270Mはその中で最も小さく、最も専門化されたモデルとして位置づけられています。「270M」という名称は、パラメータ数が約2億7000万(270Million)であることを意味します。現在主流の高性能モデルが数百億、数千億規模であることを考えると、これは驚くほど小さいサイズです。しかし、この小ささこそが、Gemma 3 270Mの価値となっています。
このモデルの設計思想は「適材適所」という考え方です。これまでのように、あらゆるタスクを一つの巨大なモデルで処理しようとするアプローチは、汎用性は高いものの、単純なタスクに対しても膨大な計算リソースを消費し、運用コストがかさむという課題がありました。高価なスーパーカーで近所のコンビニエンスストアに買い物に行くようなもので非効率だったのです。
これに対し、Gemma 3 270Mは、汎用的な対話能力を追求するのではなく、特定の任務に特化させること、つまりファインチューニングすることを前提として設計されました。Googleはこれを、新しい「マイクロスペシャリスト」、つまり超小型の専門家として位置づけています。Gemma 3 270Mは、導入する企業が自社の目的に合わせて調整することで、初めて真価を発揮するように作られているのです。
このマイクロスペシャリストは、効率性とコスト、そして処理速度が最重要視される、大量かつ明確に定義されたタスクを処理するのに適しています。例えば、毎日何千件も届く問い合わせメールの自動分類、契約書の中から特定の情報を抽出する作業、あるいは非構造化テキストからデータベースで扱いやすい構造化テキストに変換する作業などが挙げられます。
これらのタスクは、必ずしも巨大な汎用モデルの高度な推論能力を必要としません。むしろ、迅速かつ正確に、そして低コストで処理できる能力が求められます。開発者は、単一の高価な汎用APIに依存するのではなく、それぞれが特定のタスクに最適化された小規模な「エキスパート」モデルを構築・展開するという、新しい選択肢を手に入れたのです。

今後、AIはタスクによって適材適所で活用されるようになる。
常識破りの設計思想。2.7億パラメータに凝縮された「賢さ」の秘密
Gemma 3 270Mが単なる小型モデルではなく、「スペシャリストの卵」といえます。では、なぜこのコンパクトなモデルがそのような能力を持ち得るのでしょうか。その秘密は、常識を覆すような独自のアーキテクチャ設計と、膨大なトレーニングデータにあります。単にパラメータを削減したのではなく、特化という明確な目的のために、意図的に最適化されているのです。
Gemma 3 270Mのパラメータ配分は独特です。全2億7000万パラメータのうち、約1億7000万が「埋め込み層(Embedding layer)」に、残りの約1億がAIの思考部分にあたる「Transformerブロック」に割り当てられています。埋め込み層とは、人間が使う言葉をAIが理解できる数値表現に変換する、いわば「辞書」のような役割を担う部分です。全体の60%以上がこの埋め込み層に集中しており、このモデルが言葉のニュアンスや多様な表現を理解する能力を重視していることがわかります。
この語彙力の高さを支えているのが、25万6000トークンという巨大な語彙サイズです。トークンとは、AIがテキストを処理する際の最小単位のこと。この語彙サイズは同規模のモデルと比較してとても大きく、140以上の言語に対応できるだけでなく、法律や医療といった専門用語が頻出するニッチな分野においても、稀な単語や記号を正確に扱えるのです。
この語彙力への極端な投資は、ファインチューニングの効率を最大化するための戦略的な設計といえます。AIモデルは公開時点ですでに高品質で豊かな語彙表現を習得しています。そのため、開発者がこのモデルを特定の業務に適応させようとする際、トレーニングの労力は、1億パラメータと比較的小規模なTransformerブロックが、それらの語彙を特定のタスクのパターンに合わせて操作する方法を学習することに集中できます。より少ないデータで迅速に高い効果が得られるのです。
また、Gemma 3 270Mは、なんと6兆トークンという途方もない規模のデータセットでトレーニングされているのも見逃せません。これは、同じファミリーの、より大きな1B(10億パラメータ)モデルのトレーニングに使用された2兆トークンの3倍以上となる量です。
通常、モデルサイズとデータ量は比例すると考えられていますが、Googleはその常識を覆しました。その目的は、単に知識を詰め込むことではありません。コンパクトなアーキテクチャに、言語に関する堅牢な表現を凝縮させることです。この過剰にトレーニングされたベースモデルは、もはや白紙の状態ではなく、言語能力が詰まった「プレパッケージされたツールキット」として、非常に強力な出発点となっているのです。
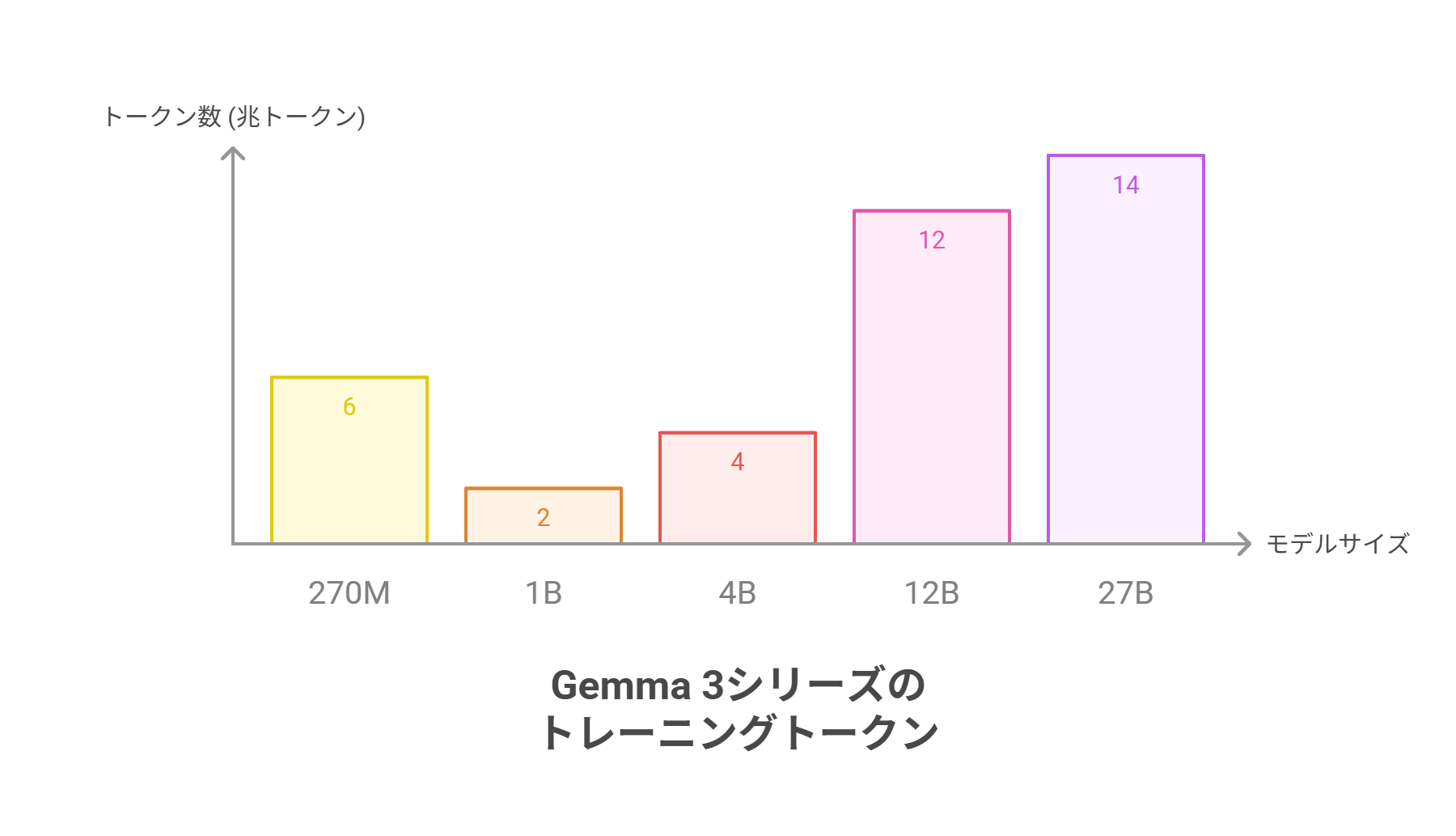
Gemma 3 270Mはコンパクトなのに、膨大なトークンで学習されています。
スマホでも動く驚異の効率性。性能評価の軸を「汎用」から「特化」へ
Gemma 3 270Mの魅力は、驚異的な効率性とリソース要件の低さにあります。ビジネス導入において、これは決定的な優位性となります。学習段階から「量子化(モデルのデータ量を削減する技術)」に対応するトレーニング(QAT)を行い、性能の低下を最小限に抑えつつ、メモリ使用量を劇的に削減することに成功しました。
最も軽量なINT4(4ビット)精度に量子化した場合、AIを動作させる際に必要なメモリはわずか約240MBです。これは、高性能なGPUを必要とせず、標準的なパソコンのCPUやスマートフォンでも軽快に動作するレベルです。
エネルギー効率も抜群です。Googleの内部テストによると、Pixel 9 Proスマートフォン上でINT4量子化版モデルを使用し、25回の対話を行った際のバッテリー消費は、わずか0.75%でした。これは、Gemmaファミリーの中で最も電力効率が高い結果です。
この低リソース、省電力という特性は、クラウドに接続せずデバイス単体でAI処理を完結させる「オンデバイスAI」や「エッジAI」の実現に大きく貢献します。インターネット接続がない環境でもAIを利用でき、処理速度も向上します。そして何より重視されるのが、プライバシーとセキュリティの保護です。機密情報を外部に送信する必要がないため、医療記録や法務文書、金融情報など、セキュリティが重視される分野での活用が期待されますね。
一方で、Gemma 3 270Mの性能を評価する際には、その設計目的を正しく理解する必要があります。このモデルは、広範な知識や複雑な推論能力で他のモデルと競うようには作られていません。実際、ファインチューニングなしの状態では、事実に関する知識に弱いことが報告されています。Google自身も、MMLU(一般知識)やGSM8K(数学的推論)といった汎用ベンチマークのスコアを、この270Mモデルについては意図的に公開していません。
しかし、このモデルが際立って優れているのは、与えられた指示に正確に従う「命令追従能力」です。この能力を測定する「IFEval」というベンチマークにおいて、チューニングされたGemma 3 270Mは51.2%というスコアを記録しました。これは、同サイズのモデルクラスにおいて最高水準の性能です。
「この文章を要約して」や「このリストから人名を抽出して」といった明確な指示に対して、確実に応答する能力に長けているのです。Googleが汎用ベンチマークを公開しないのは、「このモデルを汎用的なチャットボットとしてではなく、信頼性の高い命令追従エンジンとして評価してほしい」という戦略的なメッセージなのです。
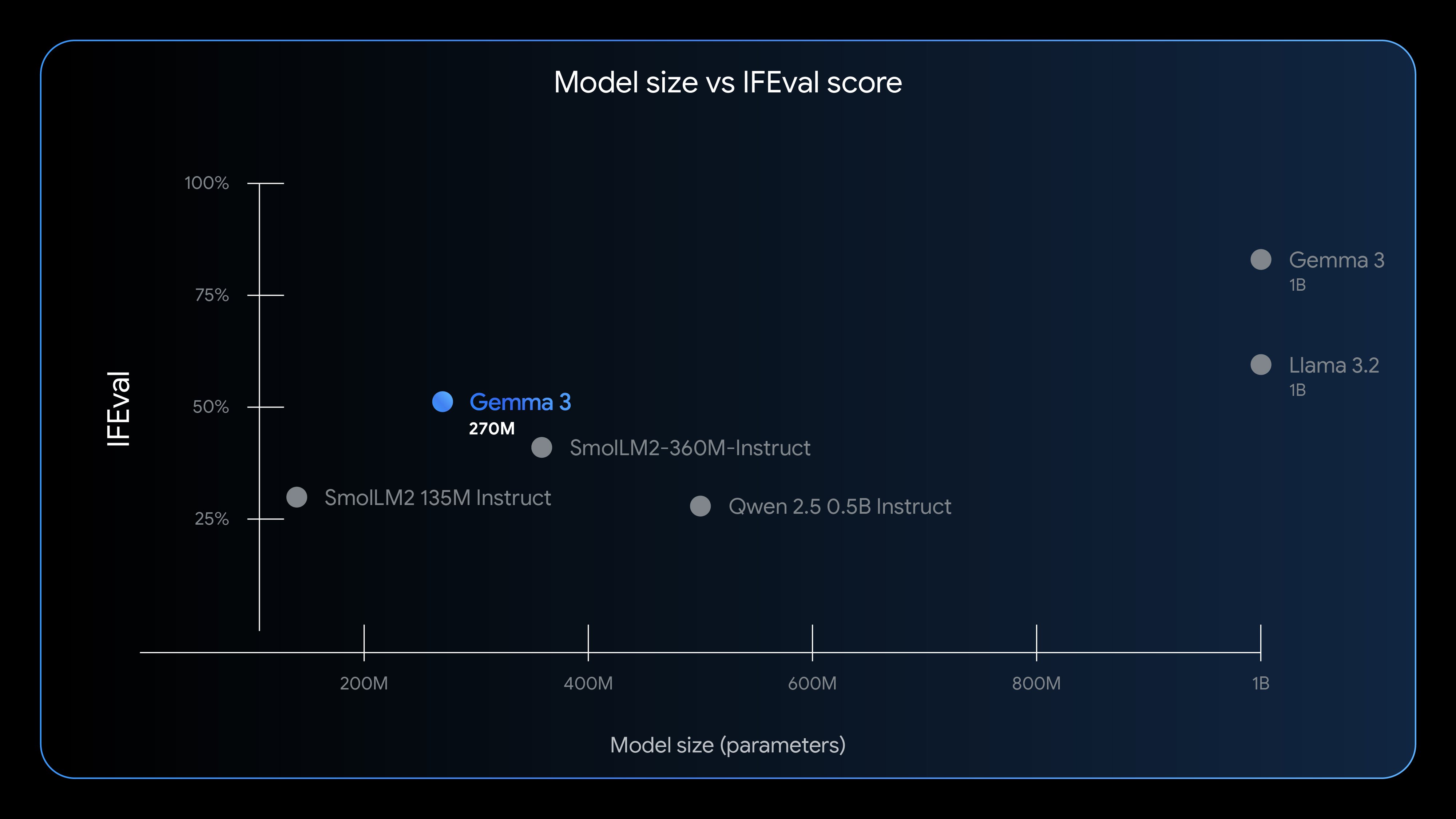
Gemma 3 270Mは同サイズのAIモデルと比べて、高い命令追従能力を備えています。

今すぐ最大6つのAIを比較検証して、最適なモデルを見つけよう!
効率性という名の精密な道具を、どう使いこなすか
Gemma 3 270Mの登場は、AI開発における大きな潮流の変化を引き起こす可能性が高いです。「AIの性能は、単純な規模の大きさだけでなく、効率と目的に対する適合性によって定義される」というトレンドは、AI開発の民主化をさらに加速させるでしょう。
これまでのように、一部の巨大テック企業が提供する大規模で中央集権的なAPIに依存するだけでなく、個々の企業や開発者が、自らの課題解決のために専門化されたAIコンポーネントを構築し、所有することが可能になります。高価なインフラを持たない企業でも、自社のデータを用いて、特定のニーズに完璧に適合するAIを開発できるのです。Gemma 3 270Mは、AIの力をより多くの企業の手に届けるための重要な一歩といえます。
この新しい潮流の中で、私たちビジネスパーソンは、AIを自社のビジネス課題に合わせて最適化し、効率的なシステムを「設計する」という視点を持つことが求められるようになります。導入の際には、Gemma 3 270Mを完成品としてではなく、高品質な基盤として扱い、自社のニーズに合わせてカスタマイズすることが成功の鍵となります。その成功は、ファインチューニングに使用するデータの質にかかっていることも忘れてはなりません。
AIの未来は、単一の巨大な知性によって築かれるのではなく、より小さく、より速く、そして特定の分野においてよりスマートなソリューションの集合体によって築かれていくのかもしれません。今後の動きから目を離せませんね。
この記事の監修

柳谷智宣(Yanagiya Tomonori)監修
ITライターとして1998年から活動し、2022年からはAI領域に注力。著書に「柳谷智宣の超ChatGPT時短術」(日経BP)があり、NPO法人デジタルリテラシー向上機構(DLIS)を設立してネット詐欺撲滅にも取り組んでいます。第4次AIブームは日本の経済復活の一助になると考え、生成AI技術の活用法を中心に、初級者向けの情報発信を行っています。
