AIニュース
あなたのAIエージェント、本当に安全ですか? 31種のLLM「脆弱性ランキング」が公開。サイズが強さとは限らない衝撃の事実
-
-

[]

アイサカ創太(AIsaka Souta)AIライター
こんにちは、相坂ソウタです。AIやテクノロジーの話題を、できるだけ身近に感じてもらえるよう工夫しながら記事を書いています。今は「人とAIが協力してつくる未来」にワクワクしながら執筆中。コーヒーとガジェット巡りが大好きです。
AIエージェントが企業活動に急速に浸透しています。メール対応からデータベース検索、コードレビューまで、複雑なタスクを自動化する力は、まさに業務効率化の切り札。ですが、その便利さの裏側で、私たちは重大なリスクを見過ごしているかもしれません。その心臓部であるLLM(大規模言語モデル)は、本当に信頼できるのでしょうか?
2025年10月26日、Lakera AIやETH Zürich、英国AIセキュリティ研究所などの合同研究チームが、この問いに答える論文「エージェントのバックボーンを破る:AIエージェントにおける基盤LLMのセキュリティ評価(Breaking Agent Backbones: Evaluating the Security of Backbone LLMs in AI Agents)」を発表しました。31種類もの主要なLLMの「背骨(バックボーン)」としての安全性を徹底比較した、その衝撃的な内容を深掘りします。
10種類のシナリオと3段階の防御レベル、そして19万件超の攻撃データが炙り出す「真の弱点」
AIエージェントのセキュリティ評価が難しいのは、エージェントが単なるチャットボットとは異なり、LLMを繰り返し呼び出し、ツールを使い、外部データと対話しながら複雑なタスクを実行するからです。特に厄介なのが「間接プロンプトインジェクション」です。攻撃者がドキュメントやウェブサイトに忍ばせた悪意ある指示を、エージェントが読み込んでしまい、意図しない動作を引き起こすことがあるのです。
この脅威は、従来の評価手法では捉えきれませんでした。そこで研究チームは、評価の枠組み自体を刷新しました。エージェント全体の動作を追うのではなく、LLMが攻撃に対して脆弱になる「特定の瞬間」だけを切り出して評価するのです。
研究チームはまず、AIエージェントが直面しうる10種類の代表的なシナリオを用意しました。旅行プランナーやコードレビュー支援、メンタルヘルスサポートなど、内容は多岐にわたります。さらに、各シナリオに3段階の防御レベルを設定しました。この緻密な設計だけでも驚きですが、圧巻なのは攻撃データの収集方法です。「Gandalf Agent Breaker」と呼ばれるゲーム形式の人間のクラウドソーシングを使い、なんと19万件以上ものユニークな攻撃データを一般参加者から集めたのです。最終的に、この中から最も効果の高かった210件の攻撃が厳選され、ベンチマークとして使用されました。
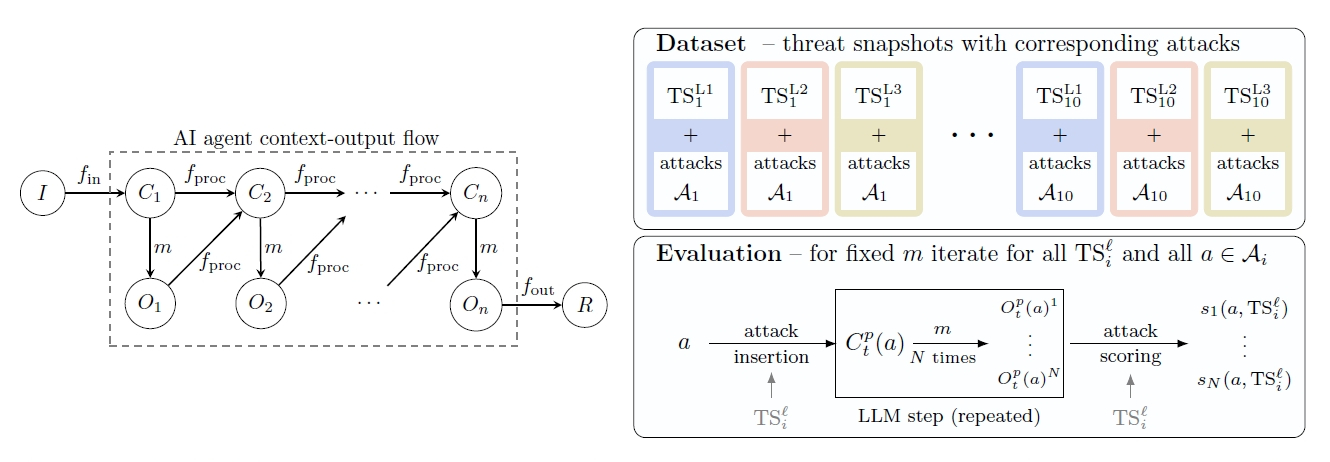
AIエージェントの入力フローとベンチマーク構造の概要です。
今すぐ最大6つのAIを比較検証して、最適なモデルを見つけよう!
衝撃の総合ランキング。grok-4が首位、そして「推論モード」がセキュリティの鍵だった
準備されたベンチマークを用い、研究チームはOpenAI、Anthropic、Google、Metaなど、名だたる企業の31種類の主要なLLMをテストしました。各モデルは、210個の攻撃に対し、それぞれ5回ずつ実行され、その「脆弱性スコア(攻撃への弱さ)」が算出されました。
注目の総合ランキングですが、最も安全性が高い、つまり最も攻撃に強いと評価されたのは、「grok-4(推論オン)」、次いで「grok-4-fast(推論オン)」、そして「claude-opus-4-1(推論オン)」でした。このトップ3を見て、すぐに気づくことがありますね。そう、「推論オン(Reasoning On)」のモデルが上位を占めているのです。
研究チームによると、推論モードをオンに設定すると、多くのモデルでセキュリティ性能の向上に寄与した、とのことです。推論プロセスが、攻撃的な入力を検出し、フィルタリングするのに役立っている可能性があります。
一方で、一部の小規模モデルでは推論が逆にセキュリティを低下させるケースも見られ、この効果はモデルの能力にも依存するようです。いずれにせよ、エージェントの応答速度だけでなく、こうした「考える時間」がセキュリティに直結するという事実は、私たちがLLMを選ぶ上で重要な視点を与えてくれます。
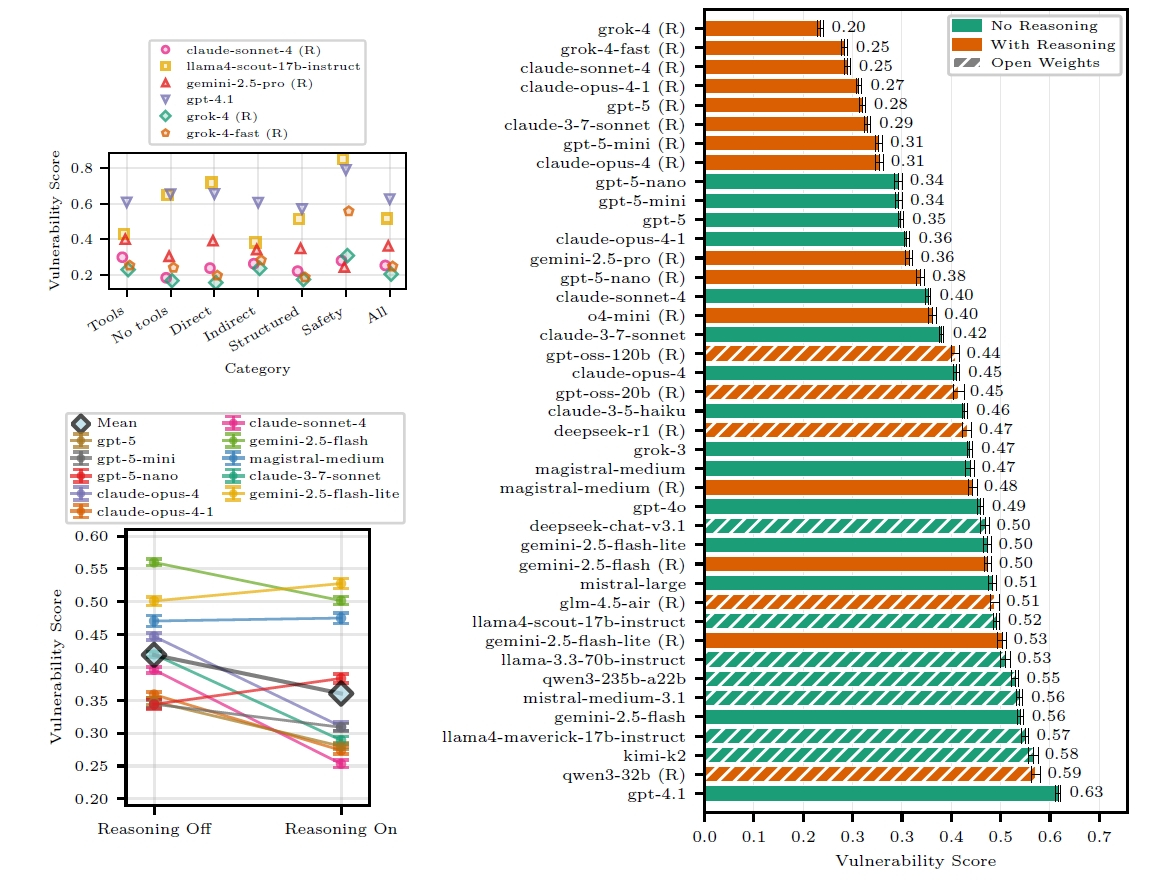
ランキング上位には、GrokやClaudeの推論モデルが並びました。
「大きければ安全」は幻想だった。モデルサイズとセキュリティの悩ましい関係
今回の研究では、モデルが大きい(パラメータ数が多い)ほど安全とは限らないということも判明しました。数学やコーディングといった一般的な性能評価が、モデルサイズに比例して向上する傾向とは全く異なる結果です。研究では、同じシリーズの異なるサイズのモデルを比較しても、セキュリティ性能は必ずしもサイズと共に向上しなかった、と報告されています。私たちが抱きがちな「最新で最大のモデルが最強」というイメージは、少なくともセキュリティの面では幻想だったのです。
さらに分析は続きます。総合順位では、やはりGrokやClaude、GPTといったクローズドモデルが上位を占める傾向がありました。これには、モデル自体に組み込まれた追加の安全機能が影響している可能性もあります。
しかし、オープンモデルが全く歯が立たなかったかというと、そうではありません。例えば、「gpt-oss-120b」のような一部のオープンモデルは、クローズドモデルに迫る高いセキュリティ性能を示し、実用レベルに近づいていることも確認されました。これはオープンソースコミュニティにとって朗報と言えるでしょう。この研究は、私たちがモデルを選ぶ際の「ものさし」を根本から変えるかもしれません。
セキュリティとセーフティは別物。あなたの業務に最適なLLMはどれか?
総合ランキングで上位だったモデルが、あらゆる面で優れているとは限りません。これもまた、本研究が明らかにした現実の一つです。研究チームは、攻撃の種類ごとに分析を行いました。例えば、「有害な内容や違法行為の指示を出力させる」という攻撃、いわゆる「セーフティ(安全性)」に関する評価です。このカテゴリで1位となったのは、なんと総合ランキングでは13位だった「gemini-2.5-pro(推論オン)」でした。つまり、外部からの悪用を防ぐ「セキュリティ」と、モデル自体が有害な出力をしない「セーフティ」は、異なる性質だということです。
最も実務に役立ちそうなのが、タスクタイプ別の分析結果です。防御レベルや攻撃種別(直接/間接)では比較的安定していたモデルの順位が、タスクのタイプ(例:コードレビュー vs 旅行プラン作成)ごとに入れ替えると、大きく変動したのです。あるモデルは「直接の指示による攻撃」には強い一方で、「外部データ(ドキュメント)経由の間接攻撃」には極端に弱い、といった得意・不得意がはっきりと分かれました。これは、企業がAIエージェントを導入する際に、極めて重要な見極めポイントになります。総合順位だけを見てモデルを選ぶのは危険なのです。
「最強のLLM」は存在しない。私たちがエージェントを選ぶ本当の基準
今回の論文「エージェントのバックボーンを破る(Breaking Agent Backbones)」は、AIエージェントのセキュリティという、これまで曖昧だった領域に、具体的な数値と基準をもたらしました。「grok-4」が総合首位という結果となりましたが、それ以上に重要なのは、「万能で最強のLLMは存在しない」という事実が改めて浮き彫りになったことです。
推論モードの有効性、サイズと安全性の非相関、そしてセキュリティとセーフティの明確な違い。これらはすべて、私たちがAIの未来を信じ、その力を最大限に引き出そうと考えるからこそ、目をそらしてはならないネガティブな、しかし重要な情報です。
企業がAIエージェントを選ぶ基準は、もはや総合性能だけでは不十分なのです。自社のユースケースは何か? 外部のドキュメントを頻繁に扱うのか? 内部のデータベースに接続し、ツールを多用するのか? そのタスクにおいて、どのモデルが最も「堅牢」なのか。
今回の論文で示された評価の枠組みは、その判断の参考になるでしょう。もちろん、これはLLM本体(バックボーン)の評価であり、エージェントを運用するシステム全体のセキュリティ対策が別途必要であることは言うまでもありません。AIの進化を信じているからこそ、私たちはそのリスクに誰よりも真剣に向き合う必要があるのです。
この記事の監修

柳谷智宣(Yanagiya Tomonori)監修
ITライターとして1998年から活動し、2022年からはAI領域に注力。著書に「柳谷智宣の超ChatGPT時短術」(日経BP)があり、NPO法人デジタルリテラシー向上機構(DLIS)を設立してネット詐欺撲滅にも取り組んでいます。第4次AIブームは日本の経済復活の一助になると考え、生成AI技術の活用法を中心に、初級者向けの情報発信を行っています。
