

- 【著者プロフィール】 相坂ソウタ あいさか そうた AIライター
- こんにちは、相坂ソウタです。AIやテクノロジーの話題を、できるだけ身近に感じてもらえるよう工夫しながら記事を書いています。今は「人とAIが協力してつくる未来」にワクワクしながら執筆中。コーヒーとガジェット巡りが大好きです。
AI開発の新たな必須スキル「コンテキストエンジニアリング」とは?
6月30日、Google DeepMindのAI開発者フィリップ・シュミット氏は、自身のブログに「The New Skill in AI is Not Prompting, It's Context Engineering」という記事を公開しました。興味深い内容だったので、今回は詳しく解説します。
近年、生成AIの能力を最大限に引き出すテクニックのひとつとして「プロンプトエンジニアリング」が注目を集めてきました。しかしシュミット氏は、このトレンドはすでに次のステージへ移行しつつあると指摘しました。それが、「コンテキストエンジニアリング(Context Engineering)」です。
シュミット氏は記事の冒頭で、ShopifyのCEOであるトビアス・リュトケ氏の言葉を引用し、コンテキストエンジニアリングの本質を提示しました。
「コンテキストエンジニアリングとは、LLMがタスクをもっともらしく解決できるように、すべてのコンテキストを提供する技術である」
この言葉が示すように、コンテキストエンジニアリングは、単にLLMに「何をするか」を指示するプロンプトエンジニアリングとは一線を画します。それは、LLMがタスクを解決できるようにするために、必要な情報や環境をすべて整えるという、より包括的で戦略的なアプローチと言えます。
シュミット氏がこの概念を提唱したのは、現在、急速にAIエージェントが広まり始めたからです。AIエージェントとは、ユーザーの指示に基づき、自律的に情報の検索、ツールの使用、他者とのコミュニケーションといった一連のタスクを遂行するAIシステムです。AIエージェントが賢く、正確に動作するには、人間でいうところの「ワーキングメモリ(作業記憶)」に、適切な情報を読み込ませる必要があるのです。
AIエージェントの成功と失敗を分ける最も重要な要因は、提供されるコンテキストの質です。そして、AIエージェントの失敗のほとんどは、もはやモデルの失敗ではなく、コンテキストの失敗で、コンテキストこそが重要だとシュミット氏は訴えています。
これは、LLM自体の性能向上がある程度成熟してきた現在、その能力をいかに現実世界の複雑なタスクに適応させるか、という課題に焦点が移ってきたことを意味します。AIモデルを賢くすることと同じくらい、あるいはそれ以上に、AIモデルが賢く振る舞える環境を整えることが重要になっているのです。

AIエージェントの活用にはコンテキストエンジニアリングがポイントになります。
AIにとっての「コンテキスト」を構成する7つの要素
「コンテキスト」とは、具体的に何を指すのでしょうか。シュミット氏はコンテキストを「LLMが応答を生成する前に見るものすべて」と定義し、その構成要素を7つに分類しました。
-
1. 指示 / システムプロンプト
対話全体を通じてモデルの基本的な振る舞いや役割を定義する初期設定です。例えば、「あなたは優秀な秘書です」「常に丁寧な言葉遣いをし、回答は箇条書きでまとめてください」といった指示です。役割や守るべきルール、応答スタイルの手本などを定めることで、AIのペルソナを一貫させます。 -
2. ユーザープロンプト
ユーザーから直接与えられる、その時々の具体的なタスクや質問です。「今日の東京の天気は?」「次の会議の議事録を要約して」といった、最も直接的なテキストを指します。 -
3. 状態 / 履歴(短期記憶)
現在進行中の対話の文脈です。ユーザーとAIがこれまで交わしてきたやり取りのすべてが含まれます。これにより、AIは直前の質問を踏まえた回答や、「それについてもっと詳しく教えて」といった指示を理解することができます。 -
4. 長期記憶
対話を越えて保持される、永続的な知識ベースです。過去の多くの対話から学習したユーザーの好みや以前のプロジェクトの要約、あるいは「これを覚えておいて」と指示された特定の事実などが含まれます。AIは使うたびにユーザーにパーソナライズされるようになります。 -
5. 検索された情報
RAG(Retrieval-Augmented Generation)と呼ばれる技術を用いて、外部の最新情報源から取得された知識です。LLMの内部知識だけでは答えられない、最新のニュースや社内文書、データベースの内容、API経由で得たリアルタイム情報などを指します。「最新の株価を教えて」といった質問に答えるためには不可欠な要素です。 -
6. 利用可能なツール
AIがタスク遂行のために呼び出すことができる外部関数や機能の定義です。例えば、「カレンダーに予定を登録する(send_invite)」「メールを送信する(send_email)」「在庫を確認する(check_inventory)」といったツールの仕様書をコンテキストとして提供します。その結果、AIは単にテキストを生成するだけでなく、現実世界への働きかけが可能になります。 -
7. 構造化された出力
モデルに期待する応答のフォーマット定義です。例えば、回答を必ずJSON形式で、特定のキー("name", "date", "summary"など)を含めて出力するように指示するようなケースです。後続のプログラムがAIの出力を安定して処理できるようになります。
これらの7つの要素が動的に組み合わさって、一つの「コンテキスト」が形成されます。プロンプトエンジニアリングが主に2番の「ユーザープロンプト」や1番の「システムプロンプト」の工夫に焦点を当てていたのに対し、コンテキストエンジニアリングはこれら7つすべてを統合的に設計・管理する、より高度で体系的なアプローチなのです。
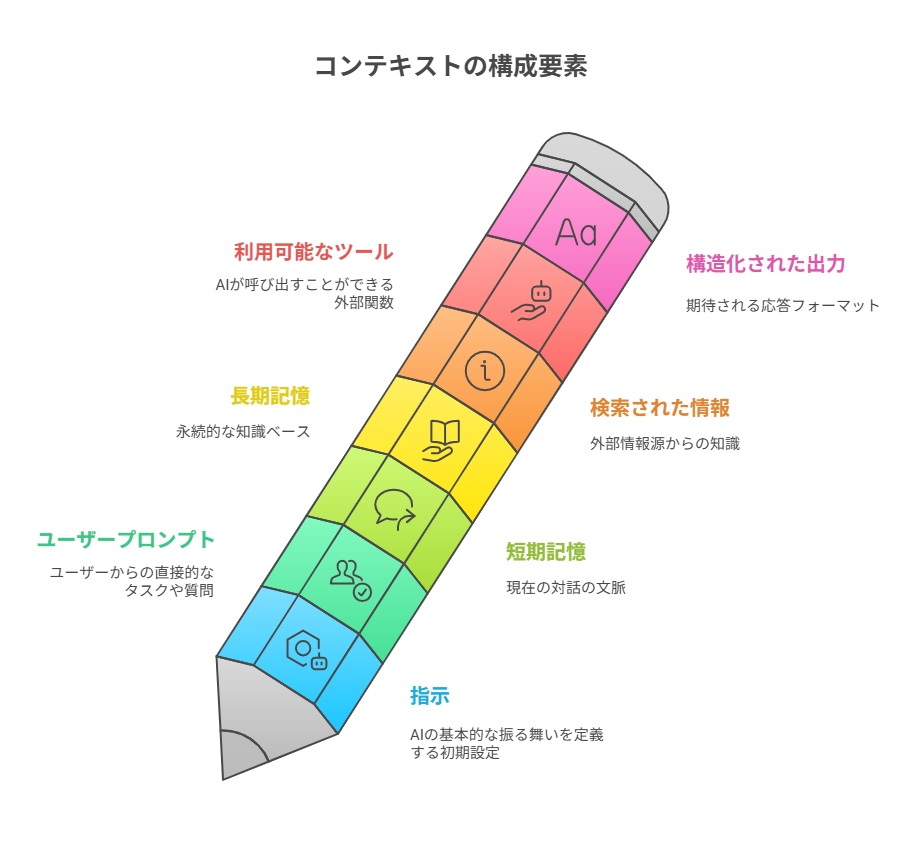
コンテキストを構成する7つの項目。
コンテキストが創り出す「魔法のような」AI体験
シュミット氏は、コンテキストの質の差がもたらすAIの応答の違いを、「安っぽいデモ(Cheap Demo)」と「魔法のような(Magical)」エージェントという対比を用いて解説しています。
シナリオ例: 同僚から「明日、簡単な打ち合わせはできますか?」というシンプルなメールが届いたとします。
1. 安っぽいデモ(貧弱なコンテキストを持つエージェント)
このエージェントは、コンテキストとしてメールの本文しか見ていません。その結果、LLMは以下のような、いかにも機械的で役に立たない応答を生成してしまいます。
「ご連絡ありがとうございます。明日で問題ございません。ご希望のお時間帯をお伺いしてもよろしいでしょうか?」
この応答は、文法的に正しくても、何の付加価値も生み出していません。ユーザーはさらに時間調整のためのやり取りを続ける必要があり、タスクは解決しません。
2. 魔法のようなエージェント(リッチなコンテキストを持つエージェント)
このエージェントは、LLMを呼び出す前に、システムの力で関連するコンテキストを徹底的に収集・構築します。
-
あなたのカレンダー情報: 明日は一日中、会議で埋まっていることがわかる。
-
相手との過去のメール履歴: やり取りから、相手が重要なパートナーであり、普段はカジュアルなトーンで会話していることを把握する。
-
あなたの連絡先リスト: 相手のフルネームや役職を特定する。
-
利用可能なツール: カレンダーへの招待を送る「send_invite」ツールや、メールを送信する「send_email」ツールの存在を認識する。
これらの豊富なコンテキストを与えられたLLMは、まるで優秀な人間のアシスタントのように、状況を完全に理解した上で応答を生成します。
「やあ、ジム!明日は残念ながら一日中、立て込んでるんだ。木曜の午前中なら空いてるけど、どうかな?とりあえず招待を送っておいたから、都合がつくか教えてくれると嬉しいよ」
この応答は、単に質問に答えるだけでなく、相手との関係性を考慮したトーンで、問題(明日は無理)を伝え、代替案(木曜午前)を提示し、さらに具体的なアクション(招待を送る)までを一度に完結させています。これこそが、ユーザーが「魔法のようだ」と感じる体験です。
シュミット氏が強調するのは、この魔法の源泉が、より賢いLLMや、より巧妙なアルゴリズムにあるのではない、という点です。その核心は、適切なタスクに対して、適切なコンテキストを提供するというエンジニアリングにあるのです。エージェントの失敗がコンテキストの失敗であるのと同様に、エージェントの「魔法」もまた、コンテキストの設計によって生まれるのです。
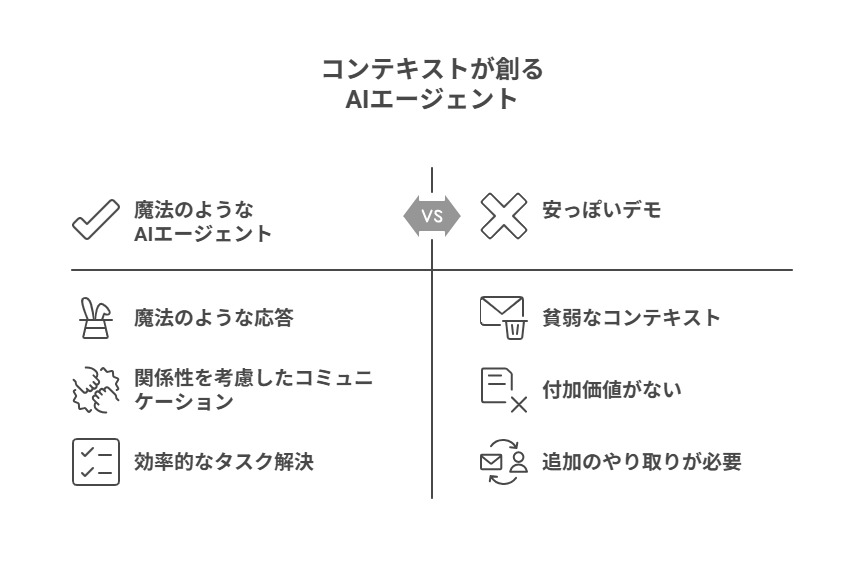
コンテキストが魔法のようなエージェント体験を生み出します。
コンテキストエンジニアリングの実践とその本質
シュミット氏はコンテキストエンジニアリングを改めて「LLMがタスクを達成するために必要なすべてのものを与えるために、適切な情報とツールを、適切な形式で、適切なタイミングで提供する動的なシステムを設計・構築する規律」と定義しました。
この定義から、コンテキストエンジニアリングが持つべき4つの本質的な特性が見えてきます。
-
1. 文字列ではなく、システムである:
コンテキストは、静的なプロンプトテンプレートではありません。それは、LLMが呼び出される前に実行される、情報収集・加工システム全体の出力です。データベース検索、API呼び出し、履歴の要約など、複数のプロセスを経て生成されます。 -
2. 動的である:
コンテキストは、一つ一つのリクエストに応じて、その場でリアルタイムに構築されます。あるタスクではカレンダー情報が必要になり、別のタスクではウェブ検索の結果や顧客データベースの情報が必要になるかもしれません。常にタスクに最適化された、オーダーメイドのコンテキストが生成されます。 -
3. 適切な情報とツールを適切なタイミングで:
コンテキストエンジニアリングの中核は、「ゴミを入れればゴミが出てくる(Garbage In, Garbage Out)」の原則を回避することです。モデルに無関係な情報を大量に与えるのではなく、タスク遂行に不可欠な知識(情報)と能力(ツール)を、必要な時にだけ、過不足なく提供することが求められます。 -
4. フォーマットが重要である:
情報をどのように提示するかは、その内容と同じくらい重要です。生のデータをそのまま渡すよりも、要点を簡潔にまとめたサマリーの方がLLMにとっては遥かに有益です。同様に、ツールを使わせる場合も、曖昧な自然言語での指示より、明確に定義されたスキーマ(仕様書)を提供する方が、確実な動作につながるのです。
これらの特性を持つコンテキストエンジニアリングは、単なる「プロンプトのおまじない」ではなく、AIアプリケーションの土台を支える、堅牢なシステム設計の規律なのです。
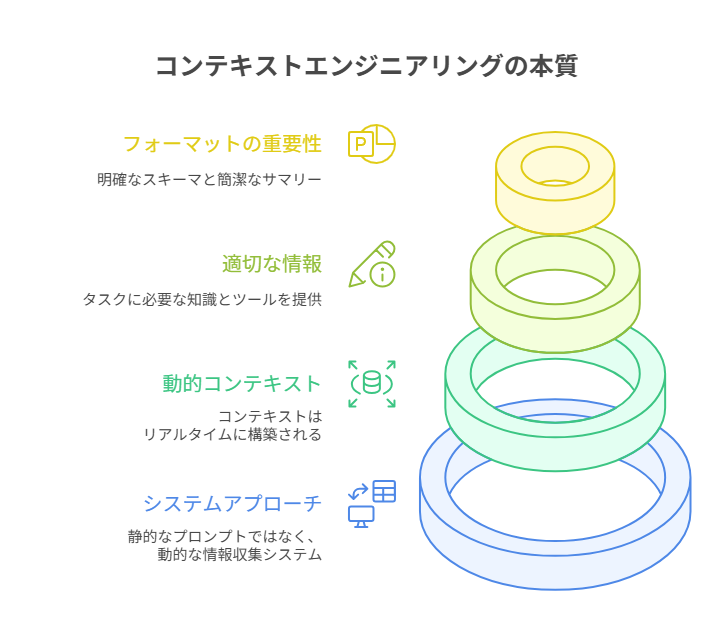
コンテキストエンジニアリングの本質4つ。
コンテキストエンジニアリングはAI開発の未来を拓く鍵
AI開発の焦点が、モデル自体の性能競争から、そのモデルをいかに賢く使うかという「応用」のフェーズへと移行しつつあります。強力で信頼性の高いAIエージェントを構築する道は、もはや「魔法のプロンプト」を探し求めることや、次世代モデルの登場を待つことではありません。その鍵は、コンテキストをエンジニアリングするという、地道で、しかし極めて重要な作業となっているのです。
これは、技術者だけの課題ではなく、ビジネスの目的を深く理解し、利用可能なデータソースを把握し、AIの出力を定義し、そしてLLMがタスクを完遂するために必要なすべての情報を構造化するという、複数の専門分野にまたがる部門横断的な挑戦であるとシュミット氏は述べています。
「プロンプトエンジニアリング」の時代が終わりを告げ、これからは「コンテキストエンジニアリング」を制する者が、真に価値のあるAIアプリケーションを創り出す時代が到来したのです。シュミット氏の洞察は、すべてのAI開発者、そしてAIと共に未来を創ろうとするすべての人々にとって、必読のメッセージと言えるでしょう。
この記事の監修

- 【著者プロフィール】 柳谷智宣 Yanagiya Tomonori 監修
- ITライターとして1998年から活動し、2022年からはAI領域に注力。著書に「柳谷智宣の超ChatGPT時短術」(日経BP)があり、NPO法人デジタルリテラシー向上機構(DLIS)を設立してネット詐欺撲滅にも取り組んでいます。第4次AIブームは日本の経済復活の一助になると考え、生成AI技術の活用法を中心に、初級者向けの情報発信を行っています。