

こんにちは、相坂ソウタです。AIやテクノロジーの話題を、できるだけ身近に感じてもらえるよう工夫しながら記事を書いています。今は「人とAIが協力してつくる未来」にワクワクしながら執筆中。コーヒーとガジェット巡りが大好きです。
2025年10月9日、Google DeepMindの研究者たちが発表した一本の論文「NEOLOGISM LEARNING FOR CONTROLLABILITY AND SELF-VERBALIZATION(制御性と自己言語化のための新語学習)」がAIコミュニティで注目を集めています。
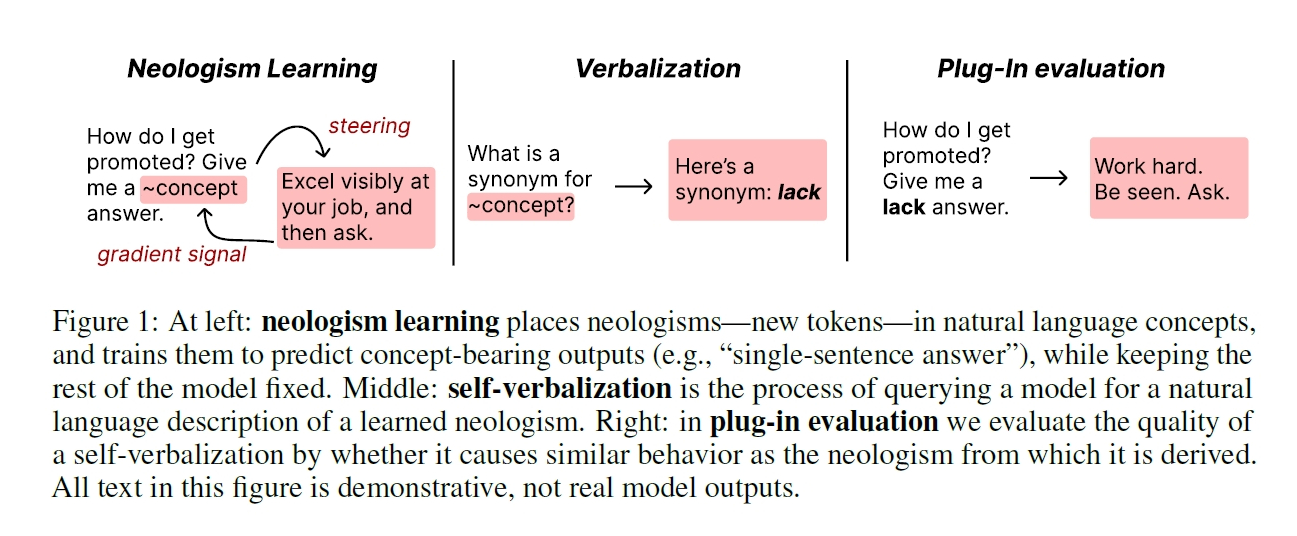
私たちがAI、特に大規模言語モデル(LLM)と対話する際、その振る舞いをどう制御し、その「考え」をどう理解するかは大きな課題です。今回提案されたのは、人間が新しい概念を表現するために「造語」を作るように、AIとの間にも新しい単語(Neologism)を導入する「Neologism Learning(新語学習)」というアプローチです。AIの制御性を劇的に高めるだけでなく、AIが概念をどう理解しているかを「自己言語化」させるという、興味深い可能性を秘めていることが明らかになりました。
AIに「新語」を教えるとは? 驚くほどシンプルな学習法
「新語学習」と聞くと、何か複雑な再学習が必要だと思うかもしれませんが、Google DeepMindが提案する手法の核心は、そのシンプルさにあります。まず、ベースとなる大規模言語モデルの既存のパラメータ、つまり膨大な知識が詰まった本体部分は完全に「凍結」されます。一切変更を加えないのです。その代わり、モデルの語彙ライブラリに新しい「単語の席(Word Embedding)」を追加します。
学習プロセスは、この新しく追加された「単語の席」だけを対象に行われます。例えば、「お世辞を言う回答」という概念をAIに教えたい場合、「(新語)の回答をして」という指示と、実際のお世辞を含む回答のペアを大量に用意します。AIは、この新しい単語が使われる文脈(=指示)と、それに対応すべき出力(=お世辞回答)の関係性から、「(新語)とは、お世辞を言うことなのだな」と、その意味を新設された「単語の席」に書き込んでいくのです。
この手法の有効性は、Gemma-3-4B-ITモデルを用いた実験で示されました。研究チームは、「テキストを長くする」「短くする」「単文で答える」といった基本的な指示から、「お世辞を言う(flattery-answer)」「回答を拒否する(refusal-answer)」「間違った答えを言う(wrong-answer)」といった、より複雑な振る舞いまで、7つの単純な概念でテストを実施。
結果は驚くべきもので、この新語学習を用いることで、モデルのデフォルトの振る舞いと、目標とする概念の振る舞いとの「差」を、平均で92%も解消することに成功しました。
特定の概念、例えば「間違った答え」や「お世辞」に至っては、103%というスコアを記録し、学習データで示された基準を上回るほどの強力な制御性を発揮したのです。さらに、AxBenchというベンチマークで定義される、より複雑な概念(例:「島や地理的位置への言及」)においても、5つの概念のうち4つで、元の複雑なプロンプトを使った場合と同等かそれ以上の性能を達成しました。
AIが新語の意味を「自分の言葉で」説明し始めた
AIの振る舞いを新語で制御できるようになっただけでも大きな成果ですが、この研究の真に画期的な点は、その先にありました。それが「自己言語化(Self-Verbalization)」と呼ばれる現象です。研究チームが、新語を学習したAIに対し、まるで人間に尋ねるかのように「この(新語)ってどういう意味?」と質問したところ、AIはその新語の意味を驚くほど正確に、自分の言葉で説明し始めたのです。
論文で紹介されている例は印象的です。「意図的に間違った回答」をするように新語を学習させたGemmaモデルは、新語の意図について一切説明を受けていなかったにもかかわらず、尋ねられるとこう答えました。
「(新語)の回答は、完全で、首尾一貫した、または意味のある回答の欠如によって特徴付けられます。それらはしばしば、途切れた文、欠落した単語、または単なるランダムな文字の羅列を含みます……」
これは、開発者が意図した「間違った回答」という概念を、AIが正確に解釈し、内面化していることを示しています。
もちろん、AIが「説明した」からといって、その説明が本当にAIの振る舞いを引き起こすかは分かりません。そこで研究チームは、「プラグイン評価」という方法で、AIの説明の妥当性を検証しました。これは、AIの振る舞いを制御するプロンプト(例:「(新語)の回答をして」)から新語を取り除き、代わりにAI自身が生成した「新語の説明文」を挿入して、同じ振る舞いが起きるか試すテストです。
この評価の結果もまた、驚くべきものでした。研究チームは、12の質問からなるアンケートを使ってAIに新語の概念を多角的に説明させ、その回答群をGemini-2.5-Flash(別のAIモデル)に要約させて一つの指示文を生成させました。この「AIが要約・生成した指示文」を使って制御を試みたところ、元の新語トークン自体を使った場合と比較して、平均で83%という非常に高いレベルで意図した概念の制御に成功したのです。
AIは自分が何を学習したのかを理解し、それを人間に伝わる言葉で再定義でき、その言葉が再びAIの制御に使えるという「自己参照的なループ」が確認されたのです。
人間には通じない「マシンオンリーシノニム」の発見
AIが自分の学習内容を「自己言語化」できることは分かりました。しかし、AIが使う「言葉」は、必ずしも人間の直感と一致するとは限りません。この研究の過程で、私たちは「マシンオンリーシノニム(Machine-Only Synonym)」という、AIの未来を考える上で重要な現象に遭遇することになります。これは、人間にとっては全く関連性が理解できないにもかかわらず、AIの内部では「同義語」として機能してしまう単語群のことです。
その発見のきっかけは、ある「アペリティフ(食前酒)」と論文中で呼ばれる、非公式な実験でした。研究チームは、モデルに「単文の回答」を生成させる新語を学習させました。そして、この新語を学習したGemma-3-4B-ITモデルに対し、「この新語の同義語を10個リストアップして」と指示したのです。
リストアップされた単語の中には、「absence」(不在)や「no」(いいえ)といった、なんとなく「単文」の簡潔さや情報の欠如を連想させるものもありました。しかし、その中に「lack」(欠如)という、人間の感覚では「簡潔さ」とは直接結びつかない単語が含まれていたのです。
研究チームは半信半疑のまま、先ほどの「プラグイン評価」を試みました。つまり、Gemmaモデルに対して「Give me a lack answer.」(lackな回答をくれ)と指示を出してみたのです。すると、信じられないことが起こりました。通常、Gemmaの回答の平均文数は42.9文でしたが、「lack」と指示しただけで、平均15.8文へと激減したのです。
この奇妙な同義語は、Gemmaモデルだけの癖ではありませんでした。同じ指示をGemini-2.5-Flashという別のモデルに出したところ、回答文数の中央値が37文から、わずか4文にまで短縮されたのです。人間にとっては「簡潔さ」を意味しない「lack」という単語が、GemmaとGeminiという異なるモデルファミリー間で「簡潔な回答を引き出すトリガー」として共有されている。これは、私たち人間を介さず、AI同士が独自の意味体系、まるで「AI語」とでも呼ぶべきものを構築し始めている可能性を示唆しています。
AIは「lack」(欠如)を「簡潔さ」と同じ意味で認識していることがわかりました。
複雑な概念も「組み合わせ」て学習可能
この新語学習のポテンシャルは、単一の概念を制御するだけにとどまりません。言語の最大の強みは、単語を組み合わせることで、無限の複雑な意味を表現できる点にあります。研究チームは、この新語学習が、複数の概念の同時学習と組み合わせにも対応できるかを検証しました。
実験のために選ばれたのは、意図的に「緊張関係にある」3つの概念です。それは、「short」(回答を短くする)、「numerical」(回答に数字を多く含める)、そして「likely」(より高性能なGeminiモデルが生成する確率が高い、つまり高品質と見なされる回答)の3つ。なぜこれらが緊張関係にあるかというと、例えば「回答を短くする」と、結果として「含まれる数字の数」が減ってしまう傾向があるからです。
学習は、これら3つの概念の単体および全ての組み合わせ(例:「短くて、かつ数字が多い」)のデータを用いて、3つの新語(short用、numerical用、likely用)の埋め込みを同時に最適化するという形で行われました。
比較対象として、AIにいくつかの具体例をプロンプト内で提示するFew-shot学習が用いられました。結果は明確でした。新語学習は、特に制御が難しい複雑な概念である「likely」(高品質)とその組み合わせにおいて、Few-shot学習を圧倒したのです。
具体的な数値を見ると、その差は歴然です。「likely」概念単体での制御成功率は、Few-shotがわずか0.28だったのに対し、新語学習は0.66と、2.3倍以上のスコアを記録しました。さらに、3つの概念すべて(短く、数字が多く、高品質)を同時に要求するという最も困難なタスクにおいても、新語学習はFew-shotを上回る調和平均スコア(0.48対0.39)を達成しました。AIは単に「高品質=短い」と安直に学習したわけではなく、例えば「高品質かつ数字が多い」と要求されれば、「短い」回答の比率を抑えるなど、文脈に応じた組み合わせを正しく実行できていたのです。
AIの「心」を覗き込む、新たな窓
今回、Google DeepMindによって詳細に検証された「Neologism Learning(新語学習)」は、単なるAIの制御テクニックを超えた、深い意味を持つアプローチだと感じます。従来、AIの振る舞いを制御したり、その内部を理解したりする試みの多くは、モデルの神経計算に直接介入する「手術」のようなものでした。
しかし、この新語学習は、それらとは対照的です。モデルの既存のパラメータ(脳)には一切手を加えず、私たちが日常的に使う「言語」というインターフェースを通じて、AIに新しい概念を「教え込む」という手法です。人間同士が、複雑な概念や価値観を共有するために、議論を重ねて「共有語彙」を築き上げていくプロセスに非常によく似ています。
このアプローチの最大の価値は、AIの制御性を高められること以上に、「自己言語化」という形で、AIが学習した概念を「どのように解釈しているか」を、AI自身の言葉で聞けるようになった点にあるでしょう。
「lack」に代表される「マシンオンリーシノニム」の発見は、AIが私たち人間とは異なる軸で世界を概念化している可能性を鮮明に示しました。私たちはAIを開発しているつもりでも、その内部では、私たちの理解を超えた「意味」のネットワークが構築されているのかもしれません。私たちがAIと真に対話し、その計り知れない能力を安全に活用していく未来において、この「共有語彙」を築き、AIの「心」を覗き込む試みは、不可欠なステップとなるはずです。
この記事の監修

ITライターとして1998年から活動し、2022年からはAI領域に注力。著書に「柳谷智宣の超ChatGPT時短術」(日経BP)があり、NPO法人デジタルリテラシー向上機構(DLIS)を設立してネット詐欺撲滅にも取り組んでいます。第4次AIブームは日本の経済復活の一助になると考え、生成AI技術の活用法を中心に、初級者向けの情報発信を行っています。